1. 概述
本文将带你快速掌握 Kafka 的核心概念和基础用法。理解这些后,你可以进一步探索更深入的 Kafka 专题文章。
2. 什么是 Kafka?
Kafka 是 Apache 软件基金会开发的开源流处理平台。它不仅能用作消息系统解耦生产者和消费者,还专为实时数据流设计,相比 ActiveMQ 等传统消息队列,提供了分布式、容错且高可扩展的数据处理架构。
典型应用场景包括:
- 实时数据处理与分析
- 日志与事件聚合
- 监控指标收集
- 用户行为流分析
- 欺诈检测
- 大数据管道中的流处理
3. 搭建本地环境
初次接触 Kafka 时,建议先部署本地环境熟悉功能。通过 Docker 可以快速实现:
3.1 安装 Kafka
执行以下命令启动容器:
docker run -p 9092:9092 -d bashj79/kafka-kraft
这将在主机 9092 端口暴露 Kafka 代理。接下来需要客户端连接:
3.2 使用 Kafka CLI
Kafka CLI 已集成在容器中,需先进入容器 bash:
docker ps # 查看容器名(示例:awesome_aryabhata)
docker exec -it awesome_aryabhata /bin/bash
执行基础操作:
cd /opt/kafka/bin
# 创建主题 'my-first-topic'
sh kafka-topics.sh --bootstrap-server localhost:9092 --create --topic my-first-topic --partitions 1 --replication-factor 1
# 列出所有主题
sh kafka-topics.sh --bootstrap-server localhost:9092 --list
# 向主题发送消息
sh kafka-console-producer.sh --bootstrap-server localhost:9092 --topic my-first-topic
>Hello World
>The weather is fine
>I love Kafka
3.3 使用 KafkaIO GUI
KafkaIO 是跨平台 GUI 工具。下载安装后,配置 Kafka 代理地址:

3.4 使用 Kafka UI
Kafka UI 是基于 Spring Boot 和 React 的 Web 界面:
docker run -it -p 8080:8080 -e DYNAMIC_CONFIG_ENABLED=true provectuslabs/kafka-ui
访问 http://localhost:8080 配置集群:
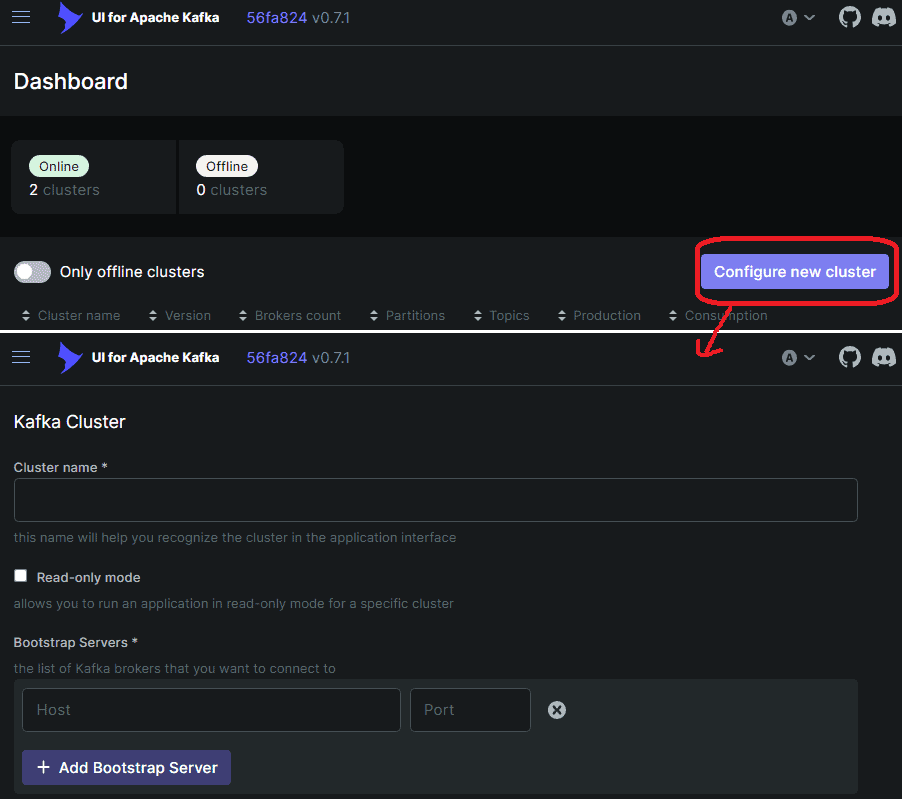
⚠️ 跨容器连接问题:由于 Kafka 和 Kafka UI 在不同容器,需解决网络互通问题:
- 进入 Kafka UI 容器安装
socat:docker exec -it --user=root <kafka-ui-container-name> /bin/sh apk add socat socat tcp-listen:9092,fork tcp:host.docker.internal:9092 - 网络架构示意:
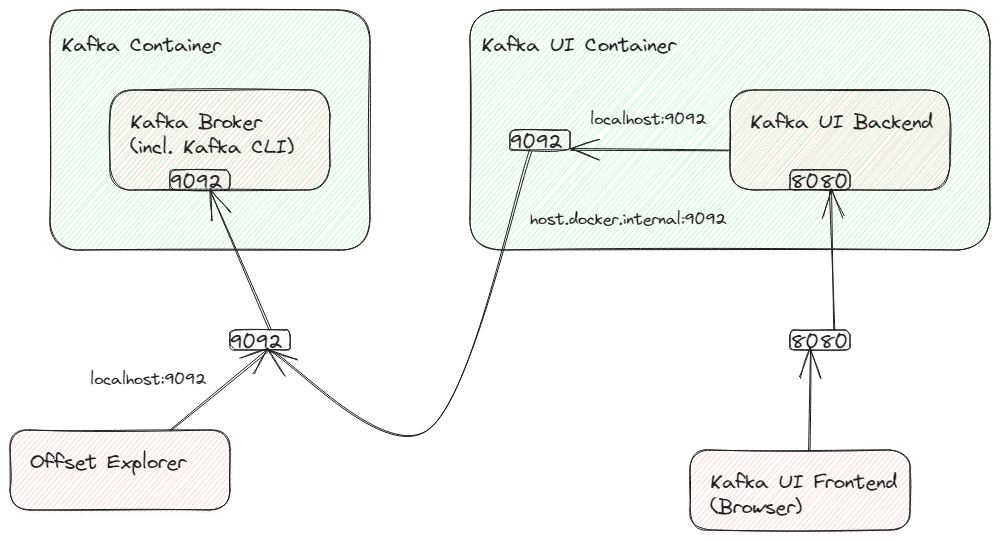
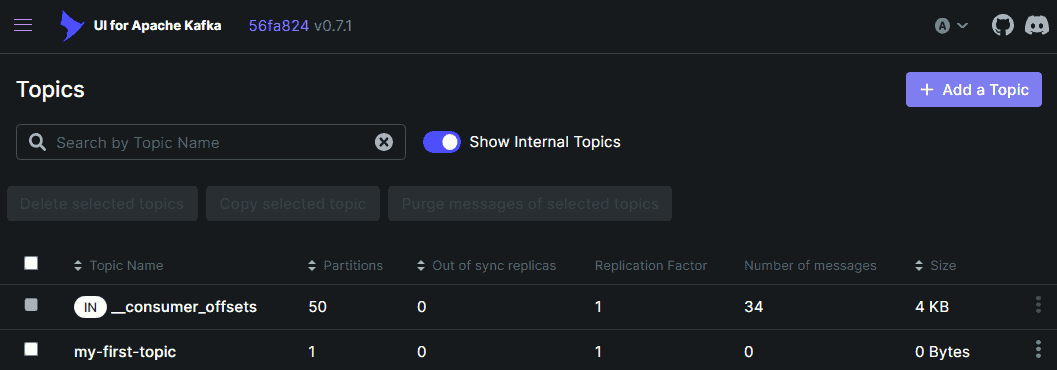
配置后即可正常管理主题:
3.5 使用 Java 客户端
添加 Maven 依赖:
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>3.9.0</version>
</dependency>
消费消息示例:
Properties props = new Properties();
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
props.put(ConsumerConfig.GROUP_ID_CONFIG, "MyFirstConsumer");
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
props.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");
try (Consumer<Long, String> consumer = new KafkaConsumer<>(props)) {
String topic = "my-first-topic";
consumer.subscribe(Arrays.asList(topic));
consumer.poll(Duration.ofMinutes(1))
.forEach(System.out::println);
}
Spring 项目可直接使用 Spring Kafka 集成。
4. 核心概念
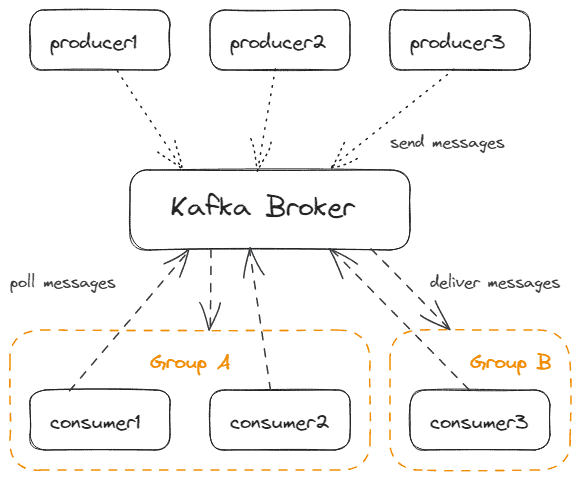
4.1 生产者与消费者
Kafka 客户端分为生产者和消费者:
- 生产者:向 Kafka 发送消息
- 消费者:通过主动拉取(poll)接收消息
✅ 关键特性:
- 消费者以组(Consumer Group)形式工作
- 同组内只有一个消费者能收到消息(保证仅一次投递)
- 支持多生产者/多消费者并行
架构示意:
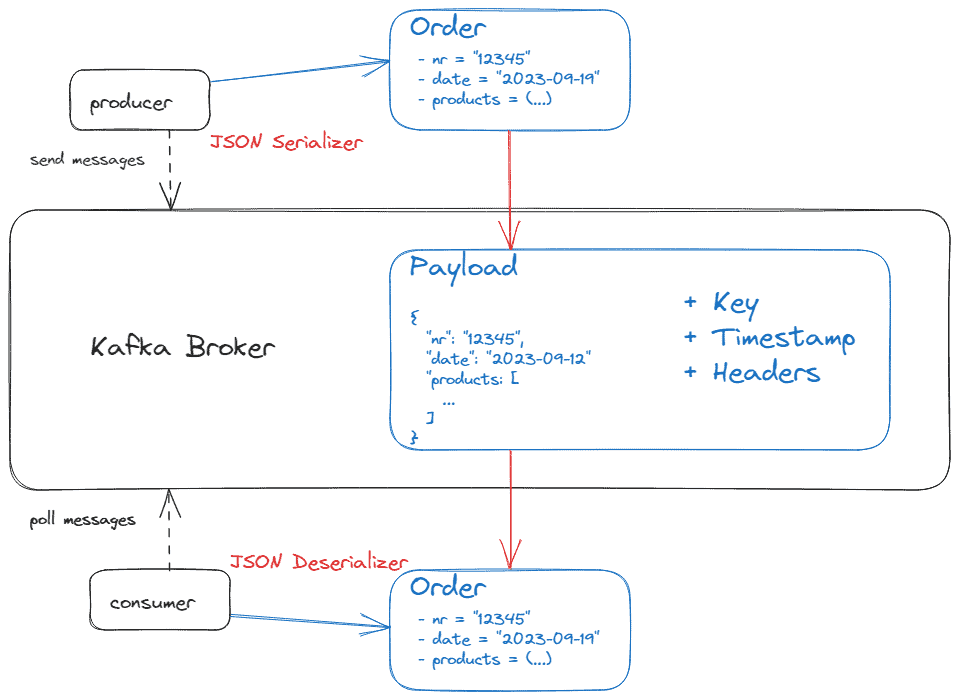
4.2 消息结构
消息(也称 record/event)是 Kafka 的基本数据单元,支持二进制或文本格式(JSON/Avro/XML)。
核心组件:
- SerDes:序列化/反序列化器(生产者用序列化,消费者用反序列化)
- 可选属性:
- Key:用于分区策略(需配套 SerDes)
- Timestamp:消息生产时间
- Headers:元数据(如 Spring 添加的类型头)
数据流示意:
4.3 主题与分区
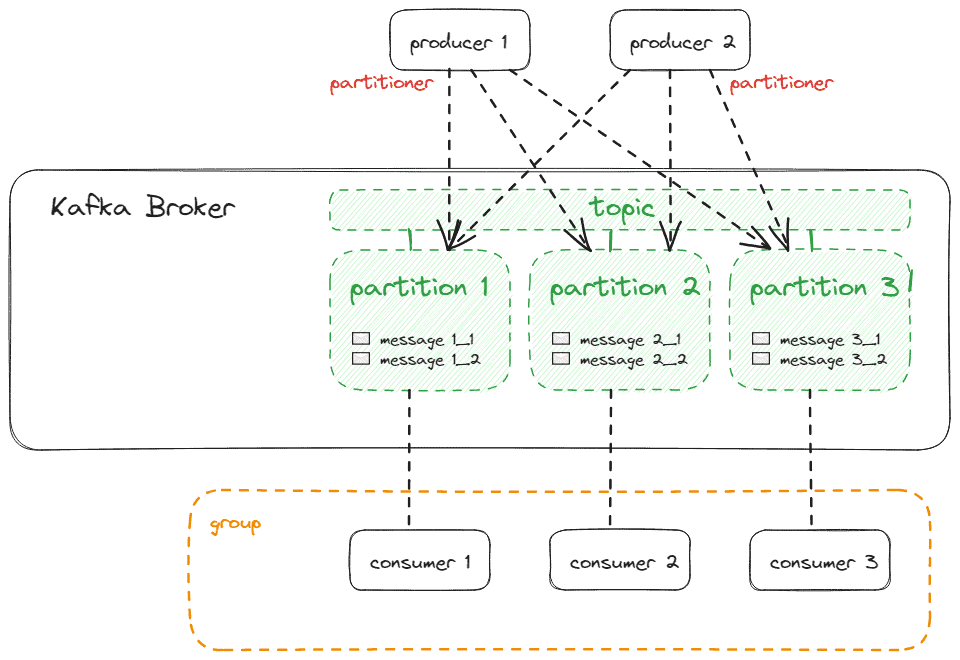
主题(Topic)是消息的逻辑通道:
- 默认保留 7 天(可配置)
- 由至少一个分区(Partition)组成
分区机制:
- 每个分区内的消息有序(通过 offset 标识)
- 消费者订阅主题时自动分配分区:
consumer.subscribe(Arrays.asList(topic)); // 自动分配 - 也可手动指定分区(不推荐):
TopicPartition myPartition = new TopicPartition(topic, 1); consumer.assign(Arrays.asList(myPartition));
⚠️ 分区与消费者数量关系: | 消费者数量 | 分区数量 | 效果 | |------------|----------|------| | = 分区数 | = 消费者数 | ✅ 理想状态(每个消费者处理一个分区) | | > 分区数 | 固定 | ❌ 多余消费者闲置 | | < 分区数 | 固定 | ⚠️ 部分消费者需处理多个分区 |
分区分配策略:
- 生产者显式指定分区(最高优先级)
- 根据 Key 哈希值分配(相同 Key 进入同一分区)
- 默认使用 Sticky Partitioner 轮询分配
自定义分区器实现:
props.put(ProducerConfig.PARTITIONER_CLASS_CONFIG, MyCustomPartitioner.class.getName());
架构示意:
4.4 集群与副本
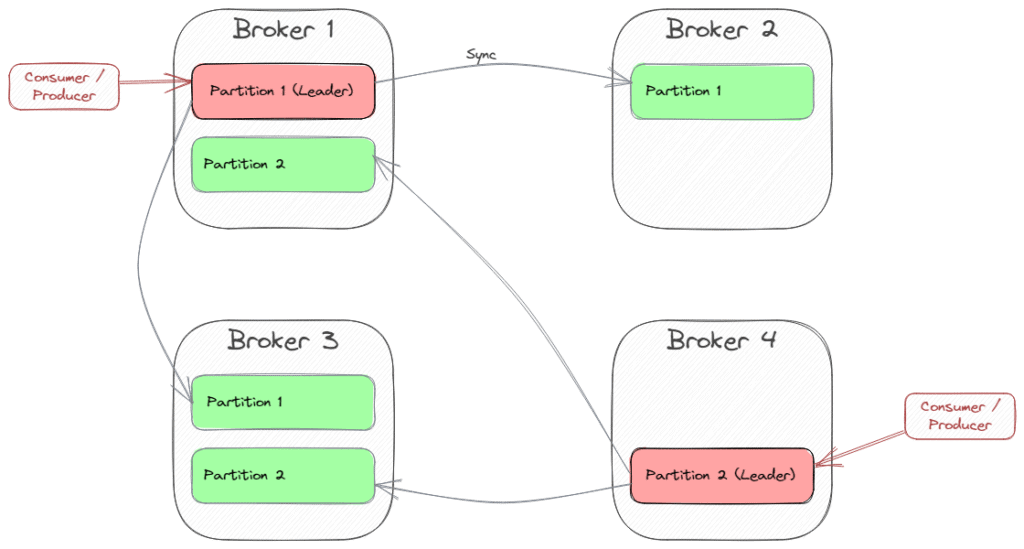
Kafka 通过多代理(Broker)集群实现高可用:
- 创建主题时需指定副本因子(Replication Factor)
- 例如:3 副本可容忍 2 台代理故障(N-1 容错)
副本机制:
- 每个分区选举一个 Leader(生产者/消费者只与 Leader 交互)
- Follower 从 Leader 同步数据
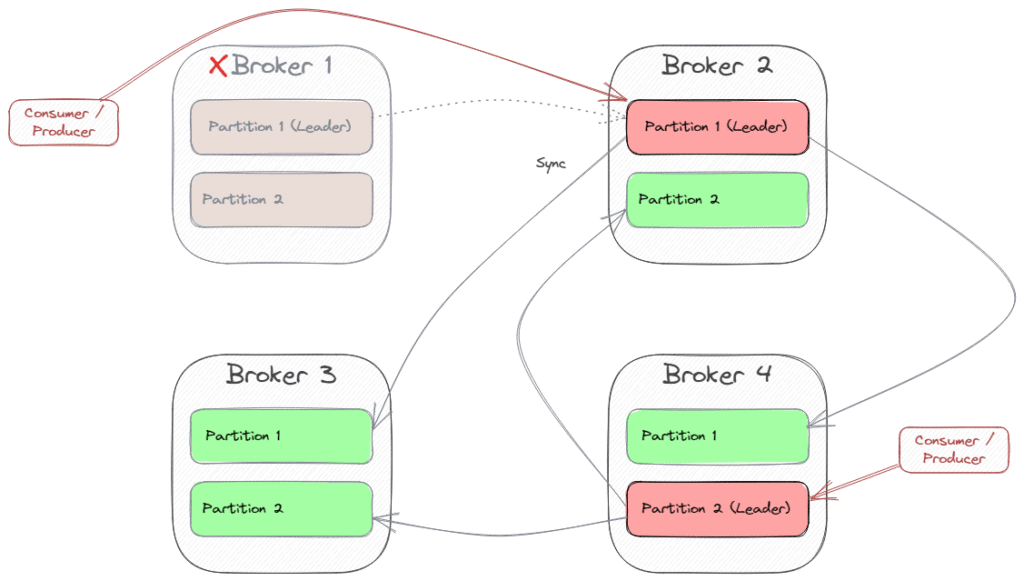
- Leader 故障时自动切换 Follower
集群拓扑示例(2 分区,副本因子 2):
故障转移示意:
集群协调依赖 KRaft(旧版使用 Zookeeper)
4.5 整体架构
3 代理集群 + 主题(3 分区/3 副本)的完整架构:
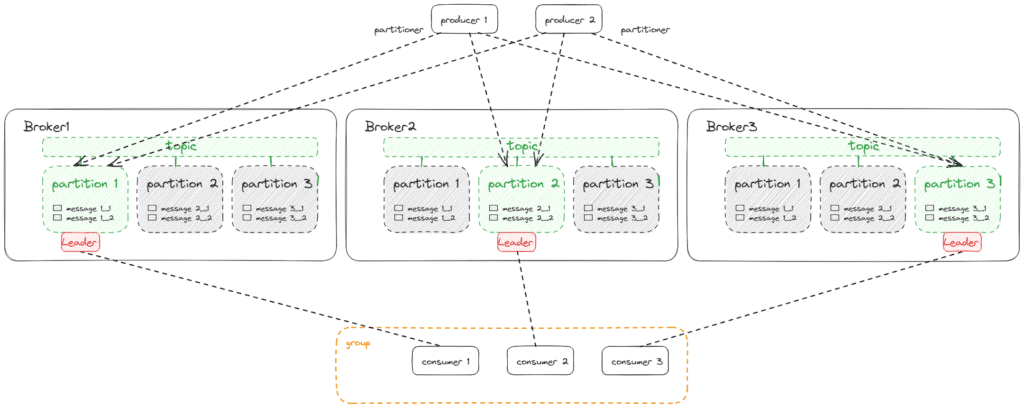
5. 生态系统
5.1 Kafka Connect API
用于与第三方系统数据交换的框架,支持:
- 预置连接器(AWS S3/JDBC/Kafka 集群间同步)
- 自定义连接器开发
5.2 Kafka Streams API
构建流处理应用的 Java 库,实现:
- 从 Kafka 主题读取数据
- 处理后写入另一个主题
5.3 KSQL
基于 Kafka Streams 的 SQL 接口:
- 通过 ksqlDB 执行类 SQL 查询
- 支持 CLI 和 Java 客户端
5.4 Kafka REST Proxy
提供 RESTful 接口访问 Kafka:
- 避免原生协议限制
- 便于 Web 前端/API 网关集成
5.5 Kubernetes Operator (Strimzi)
Strimzi 提供 Kubernetes 原生 Kafka 部署方案:
- 自定义资源定义(CRD)
- 自动化集群运维(扩容/升级/监控)
5.6 云托管服务
主流云平台提供的 Kafka 托管服务:
- Amazon MSK
- Azure Managed Kafka
- Google Cloud Managed Kafka
6. 总结
Kafka 通过以下设计实现高扩展与容错:
- 生产者批量发送:提升吞吐效率
- 主题分区机制:支持并行处理与消费者负载均衡
- 多副本集群:保障数据高可用
掌握这些核心概念后,就能应对大多数 Kafka 应用场景。