1. 简介
高效处理 Excel 文件至关重要,无论是读取数据还是生成报表。Apache POI 是 Java 中强大的库,让开发者能通过编程方式操作 Excel 文件。
本教程将探索如何使用 Apache POI 读取 Excel 工作表的列名。我们将:
- 快速概览 POI API
- 配置必要依赖
- 准备示例数据
- 演示从新旧格式 Excel 文件提取列名的步骤
- 编写单元测试验证功能
2. 依赖配置与示例准备
在 pom.xml 中添加以下依赖:
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi-ooxml</artifactId>
<version>4.1.2</version>
</dependency>
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-collections4</artifactId>
<version>4.4</version>
</dependency>
准备两个示例文件:
food_info.xlsx(新格式):
consumer_info.xls(旧格式):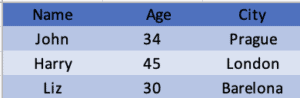

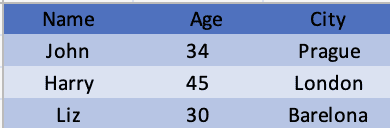
3. 从 Excel 提取列名
核心步骤:
- 打开 Excel 文件
- 访问目标工作表
- 读取标题行(首行)获取列名
3.1. 打开 Excel 文件
首先创建 WorkBook 实例。POI 通过两个抽象类支持不同格式:
✅ XSSFWorkbook 处理 .xlsx 格式
✅ HSSFWorkbook 处理 .xls 格式
public static Workbook openWorkbook(String filePath) throws IOException {
try (InputStream fileInputStream = new FileInputStream(filePath)) {
if (filePath.toLowerCase().endsWith("xlsx")) {
return new XSSFWorkbook(fileInputStream);
} else if (filePath.toLowerCase().endsWith("xls")) {
return new HSSFWorkbook(fileInputStream);
} else {
throw new IllegalArgumentException("指定文件不是 Excel 文件");
}
} catch (OLE2NotOfficeXmlFileException | NotOLE2FileException e) {
throw new IllegalArgumentException(
"不支持的文件格式,请确保是有效的 Excel 文件", e);
}
}
⚠️ 踩坑提示:文件格式错误会抛出 IllegalArgumentException,需处理异常。
3.3. 读取标题行
通过 Sheet 对象访问数据。使用 Row 接口表示行,Cell 接口表示单元格:
public static List<String> getColumnNames(Sheet sheet) {
Row headerRow = sheet.getRow(0);
if (headerRow == null) {
return Collections.EMPTY_LIST;
}
return StreamSupport.stream(headerRow.spliterator(), false)
.filter(cell -> cell.getCellType() != CellType.BLANK)
.map(Cell::getStringCellValue)
.filter(cellValue -> cellValue != null && !cellValue.trim().isEmpty())
.map(String::trim)
.collect(Collectors.toList());
}
关键处理逻辑:
- 获取首行(索引 0)
- 使用 Java Stream 处理单元格
- 过滤空白单元格和空值
- 提取字符串值并去除前后空格
💡 扩展知识:若需保留文本格式(字体/颜色等),可用 Cell::getRichStringTextValue() 替代 Cell::getStringCellValue()。
4. 单元测试
验证两种格式的文件读取:
@Test
public void givenXLSXFile_whenGetColumnNames_thenReturnsCorrectNames() throws IOException {
Workbook workbook = ExcelUtils.openWorkbook("food_info.xlsx");
Sheet sheet = workbook.getSheet("Sheet1");
List<String> columnNames = ExcelUtils.getColumnNames(sheet);
assertEquals(4, columnNames.size());
assertTrue(columnNames.contains("Category"));
assertTrue(columnNames.contains("Name"));
assertTrue(columnNames.contains("Measure"));
assertTrue(columnNames.contains("Calories"));
workbook.close();
}
@Test
public void givenXLSFile_whenGetColumnNames_thenReturnsCorrectNames() throws IOException {
Workbook workbook = ExcelUtils.openWorkbook("consumer_info.xls");
Sheet sheet = workbook.getSheet("Sheet1");
List<String> columnNames = ExcelUtils.getColumnNames(sheet);
assertEquals(3, columnNames.size());
assertTrue(columnNames.contains("Name"));
assertTrue(columnNames.contains("Age"));
assertTrue(columnNames.contains("City"));
workbook.close();
}
✅ 测试要点:
- 验证列名数量
- 确认关键列名存在
- 显式关闭
Workbook避免资源泄漏
5. 总结
本文展示了使用 Apache POI 从 Excel 工作表提取列名的完整流程:
- 通过文件扩展名自动选择 Workbook 实现类
- 利用 Stream API 高效处理标题行
- 处理空值和格式化文本的注意事项
- 单元测试覆盖新旧格式
Apache POI 简化了 Java 操作 Excel 的复杂度,是应用与 Excel 数据交互的利器。完整实现可参考 GitHub 示例。