1. 引言
在本教程中,我们将研究 ARMA 类模型的 ACF(自相关函数)与 PACF(偏自相关函数)图,理解如何从中选择最佳的  和
和  值。
值。
我们会从一些基础概念讲起,比如 ACF 图、PACF 图和平稳性。接着介绍 ARMA 模型及其 和 的选择方法。最后,我们会提出一种基于数据科学和机器学习的方法来解决这个问题。
2. 自相关函数(ACF)
自相关函数(ACF)是一种统计技术,用于识别时间序列中各值之间的相关性。 ACF 图将相关系数与滞后(lag)作图,其中滞后是以周期或单位数来衡量的。滞后对应于时间序列中第一个值之后的某个时间点。
相关系数的范围从 -1(完全负相关)到 +1(完全正相关)。系数为 0 表示变量之间没有关系。通常使用皮尔逊相关系数或斯皮尔曼等级相关系数来度量。
ACF 常用于分析随机过程生成的数值序列,如经济或科学测量数据,也可用于检测证券价格或气候测量等有系统性模式的数据集中的相关性。通常可以使用 Python、R 的统计包,或 Excel、SPSS 等软件来计算 ACF。下面是一个 ACF 图的示例:
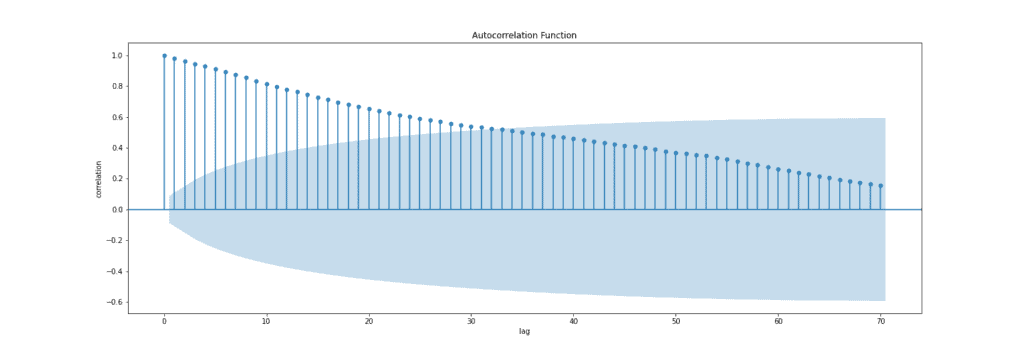
上图中的蓝色条带是误差带,位于其中的相关值不具有统计显著性。这意味着超出这个区域的相关值很可能是真实的相关性,而非统计上的偶然现象。置信区间默认为 95%。
注意:滞后为 0 时,ACF 值恒为 1,因为信号总是与其自身完全相关。
✅ 总结:
自相关是指时间序列与其滞后版本之间的相关性,而 ACF 是将相关系数与滞后作图的可视化表示。
3. 偏自相关函数(PACF)
偏自相关是一种统计度量,它捕捉在控制其他变量影响后两个变量之间的相关性。 例如,如果我们对信号  在滞后
在滞后  (
( ) 与滞后
) 与滞后  、
、 和
和  (
( ,
,  ,
,  ) 进行回归分析,那么 与 的偏相关性,是指它们之间未被 和 解释的部分。
) 进行回归分析,那么 与 的偏相关性,是指它们之间未被 和 解释的部分。
求 与 的 PACF 的方法是使用回归模型:
(1) 
其中  、
、 和
和  是系数,
是系数, 是误差。从上述回归公式中,PACF 值就是系数
是误差。从上述回归公式中,PACF 值就是系数  。这个系数表示了时间序列 对 的直接影响,因为 和 的影响已经被 和 所捕捉。
。这个系数表示了时间序列 对 的直接影响,因为 和 的影响已经被 和 所捕捉。
下图展示了 PACF 图:
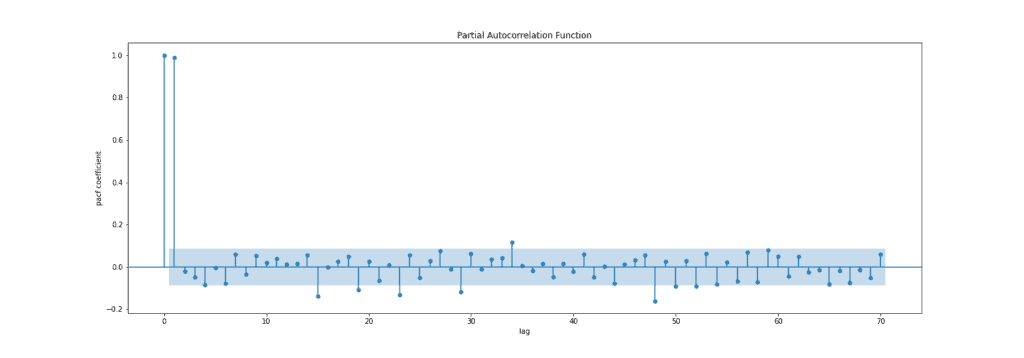
✅ 总结:
偏自相关函数捕捉的是时间序列与其滞后版本之间的“直接”相关性。
4. 平稳性
在时间序列预测中,平稳性是大多数算法要求的重要条件之一。简而言之,时间序列 是平稳的(弱平稳)当满足以下条件:
- 有恒定的均值。
- 有恒定的标准差。
- 无季节性。如果 在一年内有重复模式,则说明存在季节性。
我们可以通过可视化(近似)或统计假设检验来检查信号的平稳性。常用检验包括:
- ADF 检验(Augmented Dickey-Fuller Test):原假设是信号非平稳。
- KPSS 检验(Kwiatkowski-Phillips-Schmidt-Shin Test):原假设是信号平稳。
如果信号 是非平稳的,可以通过差分转换为平稳信号  :
:
(2) 
或计算变化百分比:
(3) 
⚠️ 注意:
这些转换并不能保证 就是平稳的。如果仍然非平稳,可以对 再次应用相同变换。
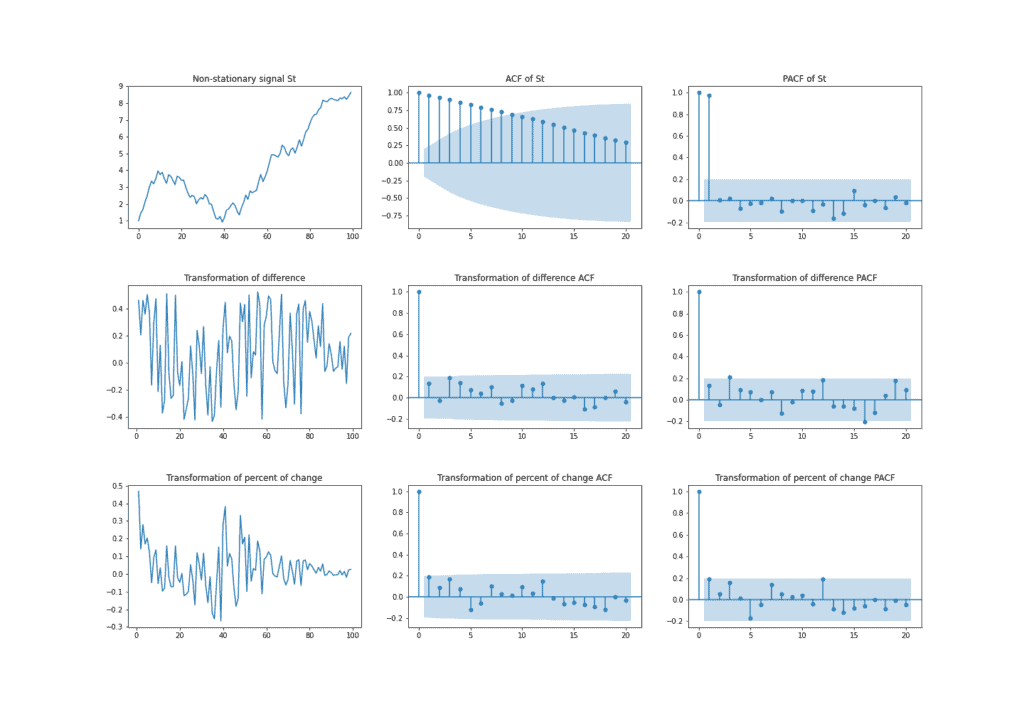
下图展示了非平稳时间序列及其变换后的结果,以及 AFC 和 PACF 的变化情况。由于正向趋势,信号 与其滞后版本高度相关,因此 ACF 图显示缓慢下降。相比之下,两种变换后的 AFC 仅在滞后为 0 时有显著相关性。
5. 自回归移动平均模型(ARMA)
ARMA( ) 模型是一种用于经济学、统计学和信号处理中的时间序列预测技术,用于描述变量之间的关系。 它可以根据过去值预测未来值,包含两个参数:(自回归部分 AR 的阶数)和 (移动平均部分 MA 的阶数)。
) 模型是一种用于经济学、统计学和信号处理中的时间序列预测技术,用于描述变量之间的关系。 它可以根据过去值预测未来值,包含两个参数:(自回归部分 AR 的阶数)和 (移动平均部分 MA 的阶数)。
我们分别定义 AR 和 MA 部分以便更好地理解。
⚠️ 注意:
AR 和 MA 模型都要求信号是平稳的。使用非平稳时间序列进行回归可能导致高 R² 值和显著的回归系数,但这些结果可能是误导性的或虚假的。
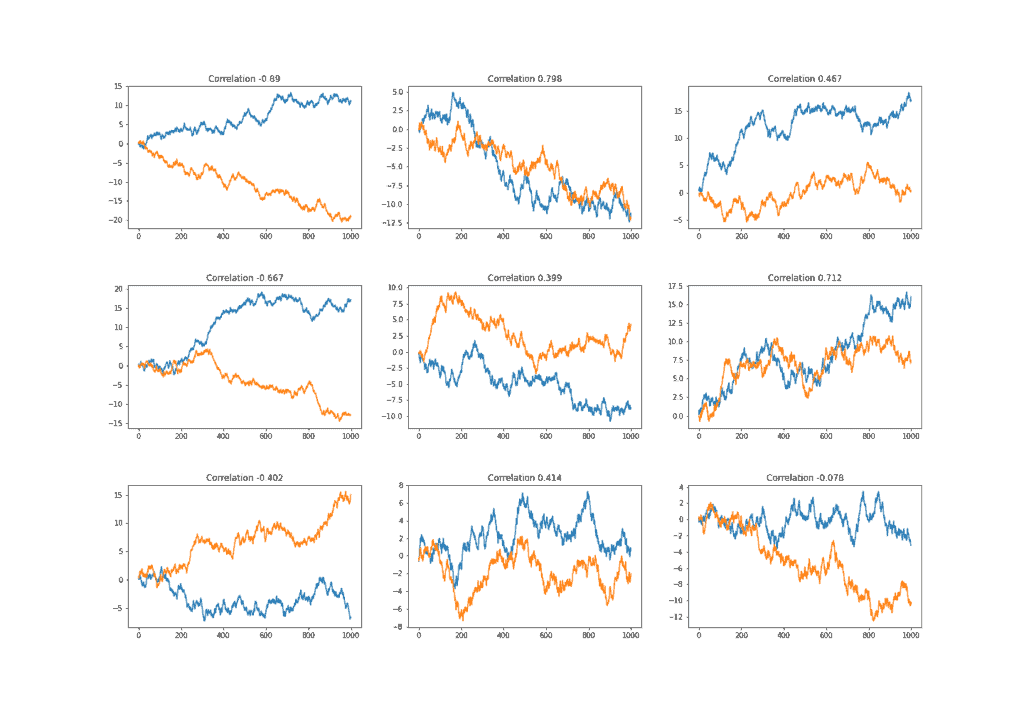
这是因为变量之间可能没有真实关系,只是它们随时间增长(或下降)。我们可以通过计算两个随机游走之间的相关性来验证这一点:
(4) ![\begin{align*} y_{t} = y_{t-1} + \epsilon_{t}, \epsilon_{t} \in [-1, 1] \end{align*}](/wp-content/ql-cache/quicklatex.com-50ac4a97259797945fe4c243bf112369_l3.svg "Rendered by QuickLaTeX.com")
下图展示了生成的 9 对随机游走,大多数对显示出高度相关性,显然是虚假的。
5.1. 自回归模型(AR)
自回归模型是一种统计模型,表示一个变量对其早期时间点的依赖关系。它是一个信号仅依赖其自身过去值的模型。例如,AR(3) 模型依赖其前 3 个值,可表示为:
(5) 
其中  是系数,
是系数, 是误差。
是误差。
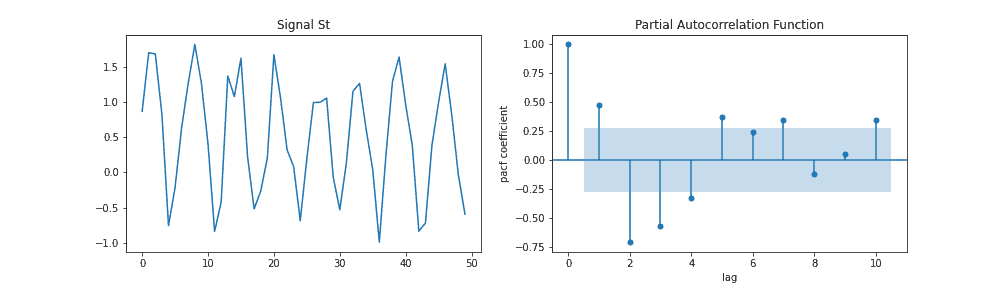
✅ 选择 AR 模型阶数 p 的方法:
- 查看 PACF 图中显著的尖峰(spike)
- ACF 图缓慢下降是 AR 过程的标志
例如,下图中 PACF 图在滞后 2 和 3 处有显著尖峰,说明可以考虑  或
或  。
。
5.2. 移动平均模型(MA)
MA() 模型通过取过去误差的加权平均值来计算预测值。 它能捕捉时间序列中的趋势和模式。例如,MA(3) 模型可表示为:
(6) 
其中  是序列的均值,
是序列的均值, 是系数,
是系数, 是均值为 0、标准差为 1 的误差(白噪声)。
是均值为 0、标准差为 1 的误差(白噪声)。
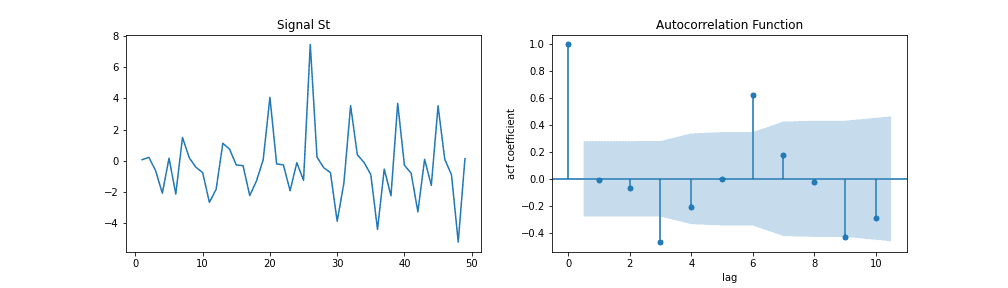
✅ 选择 MA 模型阶数 q 的方法:
- 查看 ACF 图在滞后 后是否突然截断
- PACF 图缓慢下降是 MA 过程的标志
例如,下图中 ACF 图在滞后 3 和 6 处有显著尖峰,说明可以尝试  或
或  。
。
5.3. ARMA 定义
ARMA( ) 是 AR() 和 MA() 模型的组合。例如,ARMA(3,3) 模型可表示为:
) 是 AR() 和 MA() 模型的组合。例如,ARMA(3,3) 模型可表示为:
(7) 
其中  、
、 是系数, 是误差。
是系数, 是误差。
我们已在前面章节中介绍了如何选择 和 。
6. 使用机器学习方法选择 p 和 q 阶数
有时通过分析 ACF 和 PACF 图来选择 ARMA 模型的 和 阶数非常困难且耗时。因此,有一些更简单的方法可用于调参。如今,大多数统计工具集成了“auto ARIMA”功能。
例如,在 Python 和 R 中,“auto ARIMA”方法可以自动生成适合数据集的最优 和 参数,从而提供更好的预测效果。其背后的逻辑与机器学习模型的超参数调优一致:尝试不同的 和 组合并使用验证集比较结果。
✅ 由于搜索空间不大,通常 和 不会超过 10,我们可以使用网格搜索(Grid Search)进行超参数优化。
6.1. AIC(Akaike 信息准则)
AIC(Akaike Information Criteria)是一种用于比较不同模型相对质量的统计度量。 它衡量模型在数据拟合度、简洁性和调参依赖性方面的质量。公式如下:
(8) 
其中  是对数似然,
是对数似然, 是参数数量。例如,AR() 模型有 个参数。AIC 倾向于选择对数似然高(拟合能力强)且参数少(模型简单)的模型。
是参数数量。例如,AR() 模型有 个参数。AIC 倾向于选择对数似然高(拟合能力强)且参数少(模型简单)的模型。
6.2. BIC(贝叶斯信息准则)
BIC(Bayesian Information Criteria)与 AIC 类似,但它还引入了样本数  来衡量模型质量。 公式如下:
来衡量模型质量。 公式如下:
(9) 
6.3. 时间序列的交叉验证
由于我们处理的是时间序列,必须使用合适的时间序列验证技术来进行参数调优。例如:
- 训练 [1],测试 [2]
- 训练 [1, 2],测试 [3]
- 训练 [1, 2, 3],测试 [4]
- 训练 [1, 2, 3, 4],测试 [5]
⚠️ 注意:
不能使用未来数据预测过去数据,这在现实中是不可行的。
7. 总结
在本文中,我们介绍了时间序列预测中的一些重要概念。
时间序列预测是一项复杂且困难的任务,没有一种“万能”方法。通过 ACF 和 PACF 图选择 和 阶数往往具有不确定性。因此,我们介绍了一种基于机器学习的方法来选择最佳 和 阶数的方法。