1. 概述
本文将深入探讨构建现代中央处理器(CPU)所依赖的复杂机制。尽管我们通常将CPU抽象为寄存器、算术逻辑单元(ALU)和控制单元的组合,但现代CPU还包含诸如缓存、指令流水线、分支预测等先进机制,以提升整体性能。
2. 引言
我们用来编写和发布文章的设备,其处理器频率通常以GHz为单位运行,意味着每秒可执行数十亿条指令。回想早期计算机每秒仅能执行一次运算,可以看出处理器技术已经取得了巨大进步。
早期的处理器设计者主要依赖提升晶体管切换速度或增加芯片内晶体管数量来提高性能。但由于物理限制,如今更多采用架构优化手段来提升效率。
CPU通过指令执行最小的计算任务。例如,除法操作在早期CPU中可能需要通过反复减法实现,消耗大量时钟周期。如今,大多数处理器的ALU已直接支持除法指令,虽然增加了ALU复杂度,但显著提升了性能。
此外,一些专用CPU集成了特定电路,如加密、视频解码、图形处理等。例如:
- Intel 的 MMX
- AMD 的 3DNow!
如下图所示:


随着时间推移,指令集不断扩展。一旦被广泛使用,这些指令就很难被移除。最早的CPU之一 Intel 4004 仅有46条指令,却已能构建完整计算机系统,如 Kenbak-1。
2.1 处理器的性能瓶颈
现代CPU拥有成千上万条指令,内部结构复杂。但高速执行带来了新的问题:数据无法快速地进出CPU。
类比一个家具厂:若工厂能秒产家具,但木材无法及时送达,工厂就会空转。CPU与RAM之间的数据传输就存在类似问题。
RAM位于CPU外部,相当于城市外的森林。CPU与RAM之间通过总线通信,即便电信号以接近光速传播,在GHz频率下,几厘米的延迟也足以造成性能瓶颈。此外,RAM查找地址和读取数据也需要时间,一次RAM加载可能消耗数百个时钟周期。
3. 缓存(Cache)
解决这一瓶颈的方法之一是:在CPU内部集成高速缓存(cache)。如下图所示,缓存容量虽小(通常为KB或MB级),但访问速度极快,相当于家具厂附近的木材仓库:
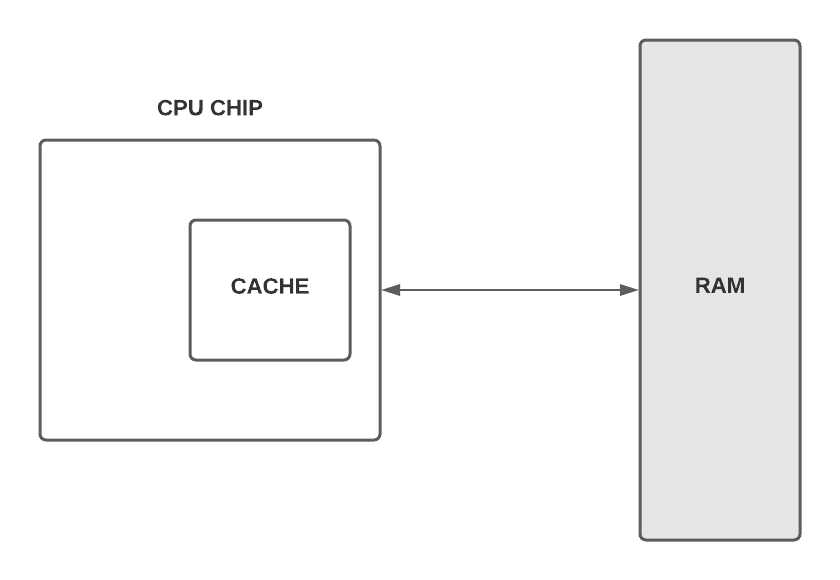
当CPU请求RAM中的数据时,RAM通常会返回一个数据块而非单个值。这个块被缓存后,后续访问可直接命中缓存,大幅提升效率。
✅ 缓存命中(Cache Hit):请求的数据已在缓存中
❌ 缓存未命中(Cache Miss):请求的数据不在缓存中,需从RAM加载
缓存同步问题:如果缓存数据被修改,需写回RAM。为此,每个缓存块都有一个“脏位(Dirty Bit)”标记。当缓存满时,若某块为“脏”,则需先写回RAM再替换。
4. 指令流水线(Instruction Pipelining)
指令流水线是提升CPU吞吐量的重要机制。CPU执行指令的基本流程包括:
- 取指(Fetch)
- 解码(Decode)
- 执行(Execute)
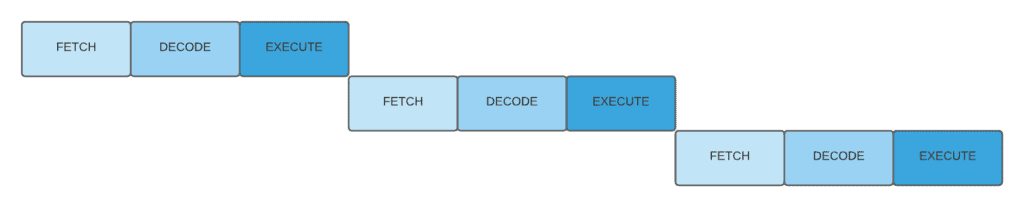
传统方式是串行执行每条指令。而指令流水线允许不同阶段并行处理多条指令,如下图所示:
❌ 无流水线:
✅ 有流水线:
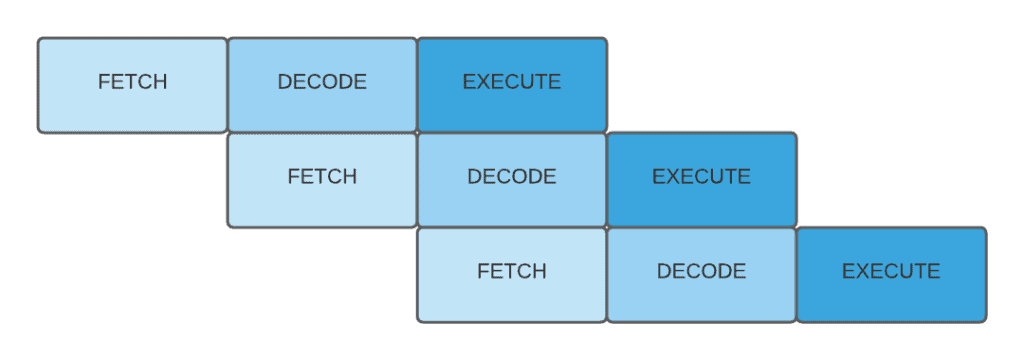
这种设计显著提升了CPU利用率和吞吐量。
4.1 指令依赖问题
指令之间可能存在依赖关系,例如前一条指令的结果是后一条指令的输入。此时流水线可能读取到旧值。
解决办法:
- 流水线阻塞(Stall)
- 乱序执行(Out-of-Order Execution):高端处理器通过动态重排指令顺序来减少阻塞
4.2 分支预测与推测执行
条件跳转指令(如 if-else)会导致流水线停顿,因为CPU需等待判断结果才能继续取指。
推测执行(Speculative Execution):CPU根据预测选择一个分支继续执行,待判断结果确定后决定是否保留执行结果。
为了提高预测准确率,现代CPU使用分支预测器(Branch Predictor),其准确率已远超50%。但这也带来了安全风险,如 Spectre 漏洞。
5. 超标量与多核处理器
5.1 超标量处理器(Superscalar)
超标量处理器可在单个时钟周期内执行多条指令。通过复制常用指令的执行单元(如ALU),充分利用CPU资源:
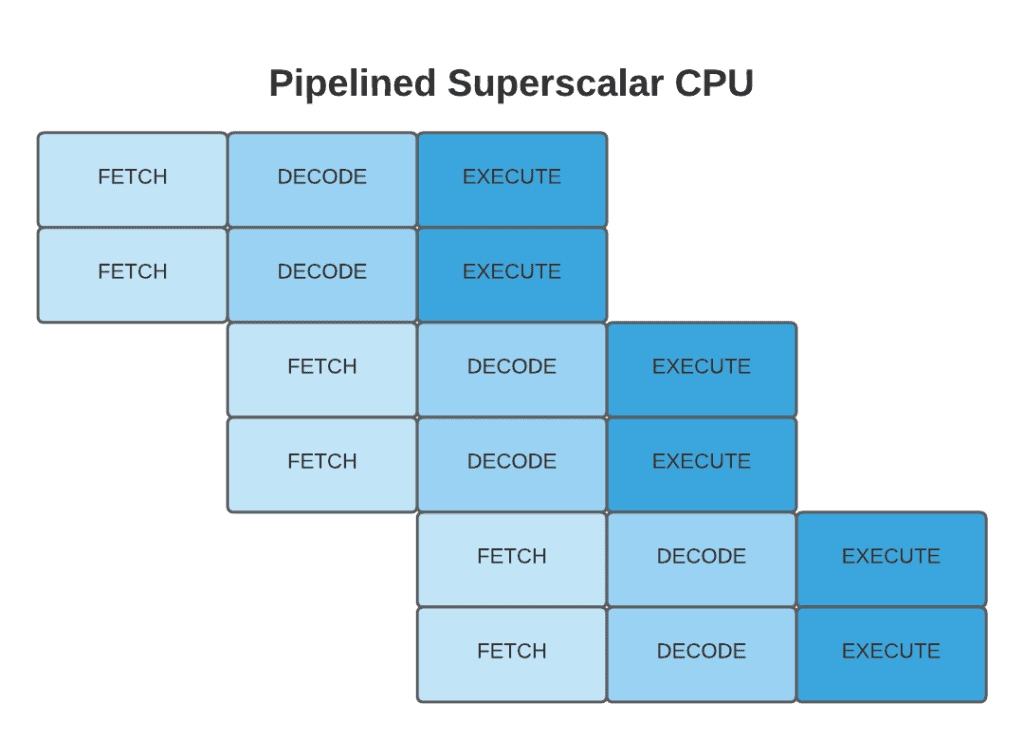
5.2 多核处理器(Multi-Core)
多核处理器是现代CPU提升性能的另一手段。通过在一个芯片中集成多个独立核心,可并行执行多个指令流。例如:
- 双核(Dual-Core)
- 四核(Quad-Core)
下图展示了2008年Intel Nehalem架构的多核结构:

6. 总结
本文介绍了现代CPU中几个关键机制:
- 缓存(Cache):缓解CPU与RAM之间的速度差异
- 指令流水线(Instruction Pipelining):提升指令吞吐率
- 分支预测与推测执行:减少条件跳转带来的停顿
- 超标量与多核处理器:充分利用硬件资源并行处理
这些机制共同推动了现代处理器的高性能与高效率。理解它们不仅有助于系统调优,也能帮助我们在开发中避免一些常见的性能陷阱。