1. 概述
在计算机科学的众多应用中,手写识别(Handwriting Recognition)是一个非常实用的技术方向。根据输入方式的不同,手写识别系统通常分为两大类:在线识别(Online) 和 离线识别(Offline)。
在本文中,我们将从技术角度出发,探讨手写文本识别中常用的方法和关键技术,帮助你构建起对手写识别系统的基本认知框架。
2. 在线字符识别算法
在线识别指的是在书写过程中实时采集数据(如触控笔轨迹、压力、速度等),并进行识别的过程。通常用于手写板、电子笔等设备。
整个识别流程通常分为三个阶段:预处理(Pre-processing)、特征提取(Feature Extraction) 和 分类识别(Classification and Recognition)。这些步骤通常是串联执行的,其中预处理为特征提取服务,而特征提取又直接影响分类效果。
2.1. 预处理
预处理的目的是去除干扰信息,提高后续处理的效率和准确性。常见操作包括:
- 二值化(Binarization)
- 采样(Sampling)
- 归一化(Normalization)
- 平滑处理(Smoothing)
- 去噪(Denoising)
这些操作能有效提升识别系统的稳定性和精度。
2.2. 特征提取
在这一阶段,我们需要提取出能代表字符特性的关键特征。这些特征通常包括:
- 笔触压力(Pen Pressure)
- 书写速度(Velocity)
- 书写方向变化(Direction Changes)
这些特征是后续分类的基础,也是识别准确率的关键因素之一。
2.3. 分类与识别
这是识别系统的“大脑”,负责将提取到的特征映射到具体的字符类别上。常用的分类模型包括:
- 支持向量机(SVM)
- 隐马尔可夫模型(HMM)
- 神经网络(Neural Networks)
该阶段的模型选择和训练质量直接影响最终识别效果。
3. 离线字符识别算法
离线识别是指基于图像输入进行识别,例如从扫描文档或照片中提取手写文字。其流程与在线识别类似,但数据来源不同。
3.1. 传统方法
传统离线识别方法通常包含以下三个步骤:
✅ 字符提取(Character Extraction)
从图像中切分出单个字符。难点在于连笔字可能被误判为一个字符块。
✅ 字符识别(Character Recognition)
使用识别引擎(如模板匹配、OCR)将每个字符映射为标准字符。
✅ 特征提取(Feature Extraction)
需要人工选择关键特征,如边缘、形状、笔画密度等。此过程不是完全自动化,依赖经验判断。
下图展示了一个典型的离线识别流程示例:
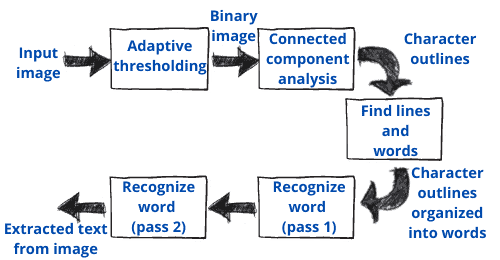
3.2. 现代方法
现代方法主要依赖深度学习技术,尤其是卷积神经网络(CNN)和循环神经网络(RNN)的结合。
与传统方法相比,现代方法的优势在于:
- ✅ 自动特征提取:CNN 可以自动从图像中提取视觉特征,无需人工设计
- ✅ 端到端识别:从图像直接输出字符序列,减少中间环节
- ✅ 处理连笔字更高效:通过对整行文本进行分析,提升切分与识别准确率
典型的现代识别流程如下图所示:
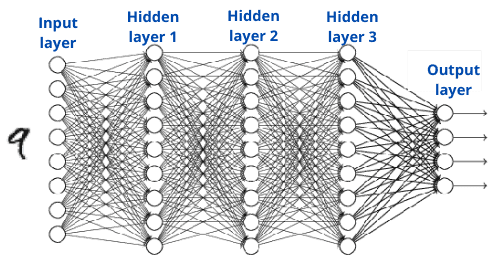
4. 文本识别技术
手写识别本质上是对“数据流”的处理,即一个输入对应多个输出(如图像 → 一串字符)。这就要求系统能处理序列数据(Sequential Data)。
常见的处理方式包括:
4.1. 循环神经网络(RNN)
RNN 是最早用于序列识别的模型之一,但存在一些明显缺陷:
❌ 训练效率低:RNN 的前一状态会影响当前状态,导致训练难以并行化
❌ 长距离依赖问题:记忆能力有限,难以处理长句或复杂结构
4.2. Transformer 模型
Transformer 引入了“注意力机制(Attention)”,解决了 RNN 的部分问题:
✅ 训练效率高:可大规模并行化
✅ 处理长序列能力强:注意力机制能捕捉远距离依赖关系
✅ 端到端建模更自然:更适合图像到文本的映射任务
目前,Transformer 已广泛应用于图像识别、OCR、机器翻译等领域。
5. 总结
本文简要介绍了手写识别的两种主要方法:在线识别与离线识别,并对各自的技术流程进行了拆解。
✅ 在线识别:适合实时输入,数据维度丰富,但硬件依赖高
✅ 离线识别:基于图像,依赖图像处理与深度学习,应用场景更广
✅ 现代方法:CNN + RNN / Transformer 是主流方案,识别准确率和效率更高
如果你正在构建一个手写识别系统,建议优先考虑现代深度学习方法,尤其是 CNN + Transformer 的组合,它在多个基准测试中表现优异,且具备良好的扩展性。