1. 引言
在实际开发中,我们经常会遇到需要将两个数据集进行最优匹配的场景。例如,安排学生与导师的面谈时间、匹配任务与可用资源、调度航班与登机口等。这类问题本质上都可以建模为二分图的最大匹配问题(Maximum Bipartite Matching)。
如果我们能高效地找到最大匹配,就能实现资源利用的最大化。这正是 Hopcroft-Karp 算法所擅长的。
2. 二分图最大匹配简介
在图论中,二分图(Bipartite Graph) 是一种特殊的图结构,其所有顶点可以被划分为两个互不相交的集合  和
和  ,并且每条边都连接一个 中的点与一个 中的点。
,并且每条边都连接一个 中的点与一个 中的点。
在匹配问题中,我们的目标是尽可能多地连接两个集合中的顶点,且每条边只能连接两个未被其他边占用的顶点。
举个例子:
一个教授有若干个面谈时间段(集合 V),有若干学生希望预约(集合 U)。如果学生只能在某些时间段预约,那么如何安排才能让最多的学生获得面谈机会?这就对应了一个二分图的最大匹配问题。
示意图如下:
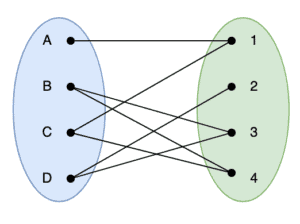
3. Hopcroft-Karp 算法概述
Hopcroft-Karp 算法 是用于求解二分图最大匹配的经典算法,由 John Hopcroft 和 Richard Karp 于 1973 年提出。该算法的时间复杂度为 **O(E√V)**,优于传统的 BFS/DFS 实现。
该算法的核心思想是:
- 每次寻找所有最短的增广路径(augmenting paths)
- 一次 BFS 找出所有可能的增广路径
- 多次 DFS 将这些路径“应用”到当前匹配中,从而提升匹配数
增广路径 是一种特殊的路径,其起点和终点都是未匹配的顶点,路径中的边交替为“未匹配”和“已匹配”状态。每次找到一条增广路径,匹配数就增加 1。
举个例子:
初始匹配:
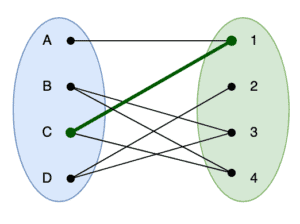
找到路径 A-1-C-4 后,更新匹配为:
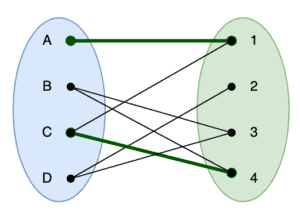
匹配数从 1 增加到 2。
4. Hopcroft-Karp 算法详解
Hopcroft-Karp 算法由两个主要步骤组成:
- BFS:寻找所有可能的增广路径
- DFS:沿着这些路径调整匹配
我们维护两个数组:
pairU[u]:记录集合 U 中顶点 u 的匹配对象(集合 V 中的顶点)pairV[v]:记录集合 V 中顶点 v 的匹配对象(集合 U 中的顶点)
还有一个特殊值 NIL,表示未匹配。
4.1 整体算法流程
algorithm HopcroftKarp(U, V, Edges):
pairU <- new int[U.length + 1] filled with NIL
pairV <- new int[V.length + 1] filled with NIL
dist <- new int[U.length + 1] filled with INF
repeat:
BFS to find augmenting paths and update dist
if no augmenting path found:
break
for each u in U:
if pairU[u] == NIL:
DFS(u, Edges, pairU, pairV, dist)
4.2 BFS 阶段:发现所有增广路径
algorithm BFS(U, V, Edges, pairU, pairV):
Queue <- new Queue()
dist[NIL] <- INF
for each u in U:
if pairU[u] == NIL:
dist[u] <- 0
Queue.push(u)
else:
dist[u] <- INF
while not Queue.empty():
u <- Queue.pop()
if dist[u] < dist[NIL]:
for v in Edges[u]:
paired <- pairV[v]
if dist[paired] == INF:
dist[paired] <- dist[u] + 1
Queue.push(paired)
return dist
4.3 DFS 阶段:构建增广路径并更新匹配
algorithm DFS(u, Edges, pairU, pairV, dist):
if u != NIL:
for v in Edges[u]:
paired <- pairV[v]
if dist[paired] == dist[u] + 1:
if DFS(paired, Edges, pairU, pairV, dist):
pairV[v] <- u
pairU[u] <- v
return true
dist[u] <- INF
return false
return true
5. 示例演示
我们来看一个简单示例,图结构如下:
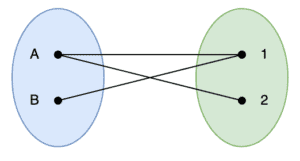
- U = {A, B}
- V = {1, 2}
- Edges = {A: [1], B: [1, 2]}
5.1 Phase 1
BFS 发现从 A 到 1 的增广路径。
DFS 找到 A-1,更新匹配:
pairU[A] = 1
pairV[1] = A
匹配数:1
5.2 Phase 2
BFS 发现从 B 出发的增广路径:B-1-A-2
DFS 找到 B-2 和 A-2(替换 A-1)
更新后:
pairU[A] = 2
pairV[2] = A
pairU[B] = 1
pairV[1] = B
匹配数:2
5.3 Phase 3
所有顶点都已匹配,算法结束。
最终匹配:
A - 2
B - 1
6. 总结
✅ Hopcroft-Karp 是一个高效的二分图最大匹配算法
✅ 核心思想是每次寻找多个最短增广路径
✅ 时间复杂度为 O(E√V),优于传统 BFS/DFS 实现
✅ 适用于任务调度、资源分配、图匹配等场景
如果你在开发中遇到类似“匹配两个集合”的问题,可以考虑使用 Hopcroft-Karp 算法。虽然实现稍复杂,但效率高,适合大规模数据处理。