1. 引言
Transformer 模型是一种在机器学习领域引发重大变革的神经网络架构。在撰写本文时,Transformer 的各种变体已经长期主导了几乎所有自然语言处理(NLP)任务的性能排行榜。不仅如此,近年来一些类 Transformer 的架构也在计算机视觉领域崭露头角,成为该领域的主流方案。
2017 年首次提出的 Transformer 论文中,除了模型结构本身,还介绍了一些关键技术,比如位置编码(Positional Encoding)和掩码(Masking)机制。
不过,在本教程中,我们将聚焦于让 Transformer 架构大获成功的最核心机制 —— 自注意力机制(Self-Attention)。
2. 什么是注意力机制?
注意力机制,本质上是指聚焦于某一部分信息,同时忽略其他无关信息的能力。在机器学习中,这一概念被用于让模型学会关注输入数据中的关键部分,忽略不相关部分,从而更好地完成当前任务。
以机器翻译为例,输入是一段文本序列。当我们人类阅读文本时,自然会更关注句子中的“谁、何时、何地”等关键信息。
这种能力是我们从出生就开始培养的,以至于我们常常忽略了它的重要性。但如果没有这种能力,我们就无法理解上下文。
举个例子,如果我们看到“bank”这个词,脑海中可能会联想到银行、血液储存点,甚至是一个便携电源。但如果我们看到句子“我打算去银行申请贷款”,我们就能立刻判断这里的“bank”指的是金融机构。这是因为我们隐式地关注了几个线索:“going to”告诉我们 bank 是一个地点,“apply for a loan”说明在那里可以办理贷款。
整句话的信息叠加起来,帮助我们在脑海中构建出 bank 的具体含义。如果机器也能像我们一样做到这一点,那么诸如多义词、多结构句式、代词指代等自然语言处理难题都将迎刃而解。
3. Transformer 基础知识
虽然 Transformer 并非完美无缺,但目前它是我们解决上下文理解问题的最佳方案之一。其核心机制就是自注意力机制。该机制通过关联一个序列中不同位置的信息,来计算该序列的表示。它在机器阅读、摘要生成,甚至图像描述生成等任务中都起到了关键作用。
由于 Transformer 最初用于机器翻译,因此它采用了经典的编码器-解码器结构,包含两个主要组件:
- 编码器(Encoder):接收一个序列输入,并将其转换为一个固定维度的状态表示。
- 解码器(Decoder):将编码后的固定维度状态映射为输出序列。
下图展示了 Transformer 的整体结构:
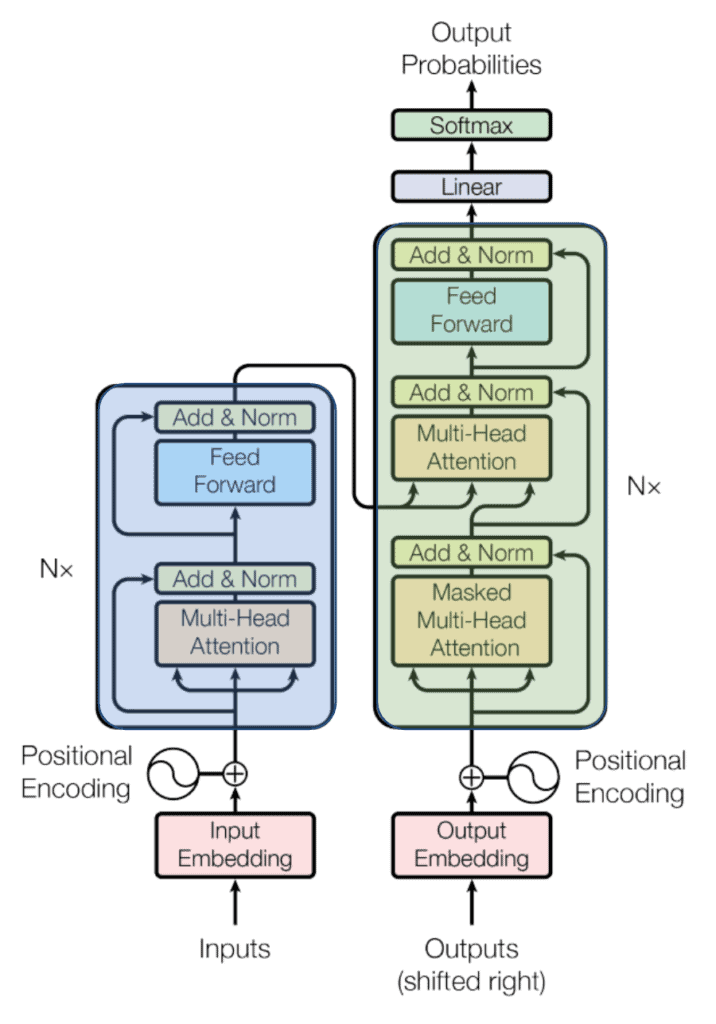
图中蓝色部分为编码器,绿色部分为解码器。我们可以看到,编码器和解码器中都使用了 Multi-Head Attention 层。我们先忽略“多头”的部分,先聚焦于单个注意力头的实现。
注意力机制的核心是缩放点积注意力(Scaled Dot-Product Attention),它通过简单的线性代数运算实现了强大的功能。它由三个矩阵组成:
- Query(Q)
- Key(K)
- Value(V)
每个矩阵的维度都是 d_k。
这个设计灵感来源于数据库系统。在数据库中,数据值通常通过键(Key)进行索引,用户通过查询(Query)来检索数据。
在自注意力机制中,这个过程是自动学习的。通过反向传播,神经网络会自动调整 Q、K、V 矩阵,以模拟用户与数据库之间的交互。
我们可以把检索过程想象成一个向量点积操作:
其中:
α是一个 one-hot 向量,由 0 和 1 组成v是我们要检索的值向量
此时,α 就是事实上的查询向量,因为输出只包含 α 为 1 的 v 对应部分:
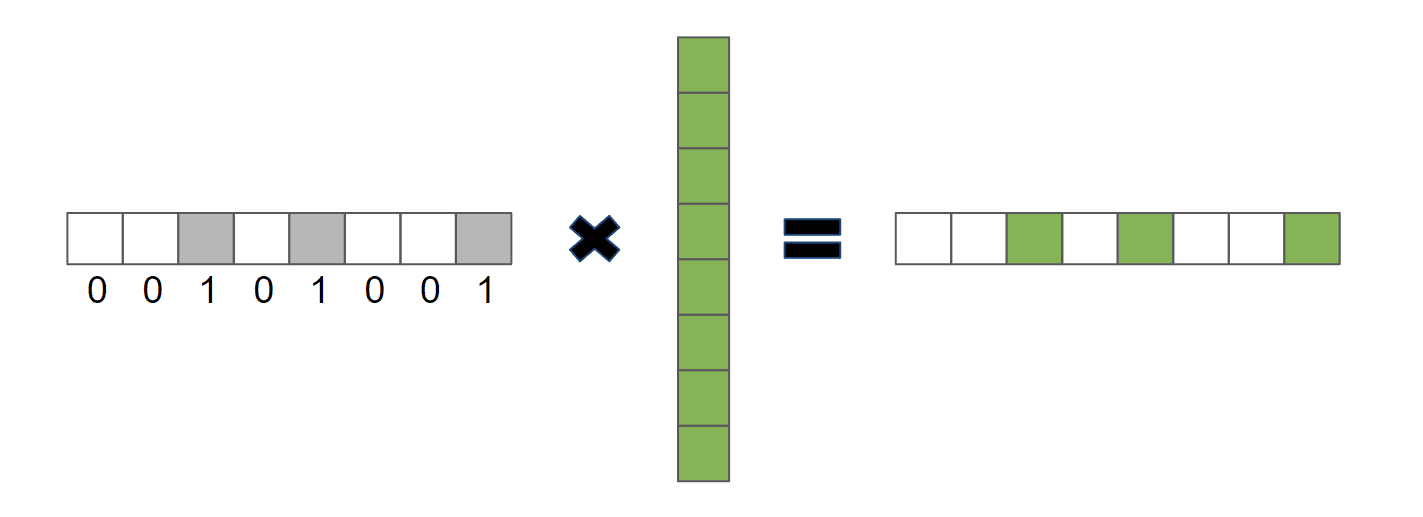
如果我们允许 α 使用 0 到 1 之间的浮点数,那么输出将是一个加权比例检索结果:
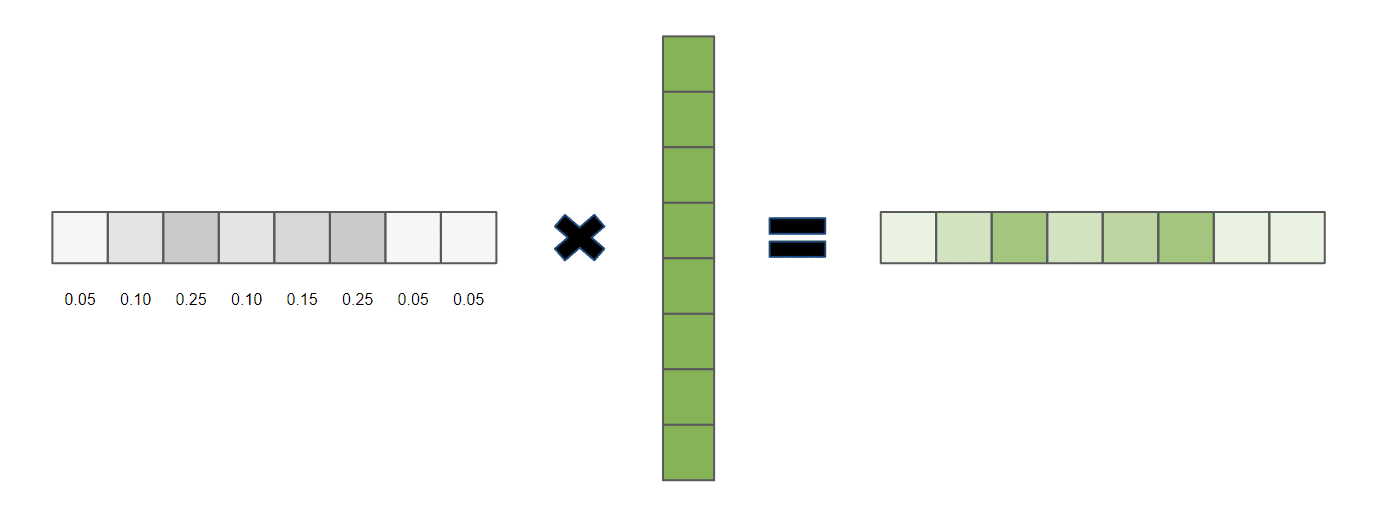
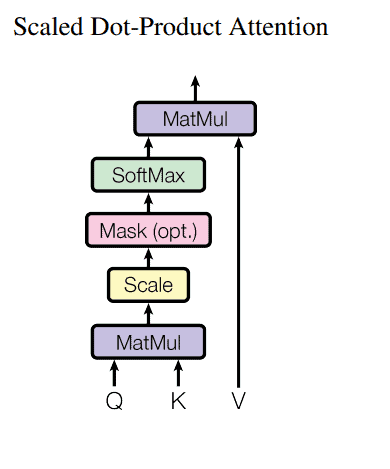
在缩放点积注意力中,这种向量乘法方式被直接应用。为了得到最终的值权重,首先计算 Query 与所有 Key 的点积,然后除以 √d_k,再应用 Softmax 函数。
最终的计算公式如下:
$$ \text{Attention}(Q, K, V)=\text{softmax}\left(\frac{Q K^{T}}{\sqrt{d_{k}}}\right) V $$
其计算过程可以用下图表示:
但这还不是全部。
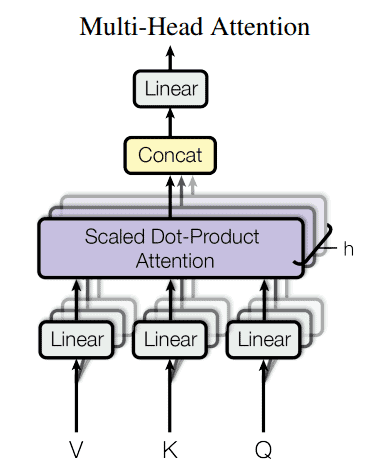
4. 多头注意力机制(Multi-Head Attention)
我们为什么要限制模型只能学习一种类型的关系呢?✅
一个更强大的方法是使用多组不同的 Key、Query 和 Value 矩阵。这样,每个注意力模块都可以专注于计算输入之间的不同类型关系,从而生成具有不同上下文含义的嵌入向量。
如上图所示,这些嵌入向量可以被拼接后通过一个普通的线性层,形成所谓的多头注意力模块(Multi-Headed Attention Module)的最终输出。
实践表明,这种方法不仅提升了模型性能,还增强了训练的稳定性。
下图展示了多头注意力机制的结构:
5. 总结
在本文中,我们深入了解了 Transformer 架构中最核心的部分 —— 注意力模块。我们看到了它是如何借鉴信息检索系统的概念,从而有效地学习长距离依赖关系,并模拟人类在处理自然语言或其他序列数据时的行为。
自注意力机制的强大之处在于它能够在不依赖序列位置的情况下,动态地捕捉输入之间的相关性,这是传统 RNN 或 CNN 架构难以实现的。这种机制也成为了现代 NLP 模型的基石,并逐步扩展到了图像、语音等多个领域。