1. 简介
在本篇文章中,我们将介绍两种常用于数据库索引实现的数据结构:B树(B-tree) 和其变种 B+树(B+tree)。
我们会从结构特点、构建过程、以及它们在数据库管理系统中的应用角度进行分析。最后,我们还会对两者进行对比,帮助你理解它们各自适用的场景。
2. 什么是 B 树?
B 树是一种自平衡的多路搜索树结构,专为高效存储和检索大规模数据而设计。
它经常被误认为是二叉搜索树(Binary Search Tree)的扩展,但实际上,二叉树只是 B 树的一种特例。B 树每个节点可以包含多个键值对(key/value pairs),这些键值对按 key 的升序排列。
我们称这些键值对为 payload。其中,value 部分有时也被称为“卫星数据”或简称为“数据”。
在数据库场景中,key 通常对应记录的主键或索引列,value 则可能是记录本身,也可能是指向记录的引用。
除了 payload 外,每个节点还保存对其子节点的引用。由于每个节点通常占用一个磁盘页,这些子节点引用通常表示子节点在磁盘中的页号。和所有搜索树一样,B 树的结构确保左子树的所有键都小于当前节点中对应的键。
2.1 B 树的性质
一个树要被称为 B 树,必须满足以下条件:
✅ 所有叶子节点都在同一层
✅ 每个节点最多有 m 个子节点
✅ 每个非叶子节点至少有 ⌈m/2⌉ 个子节点
✅ 根节点除外,所有非叶子节点至少有两个子节点
✅ 每个节点中的键按升序排列
✅ 对于任意节点内的键 k,其左子节点中的所有键都小于 k,右子节点中的所有键都大于 k
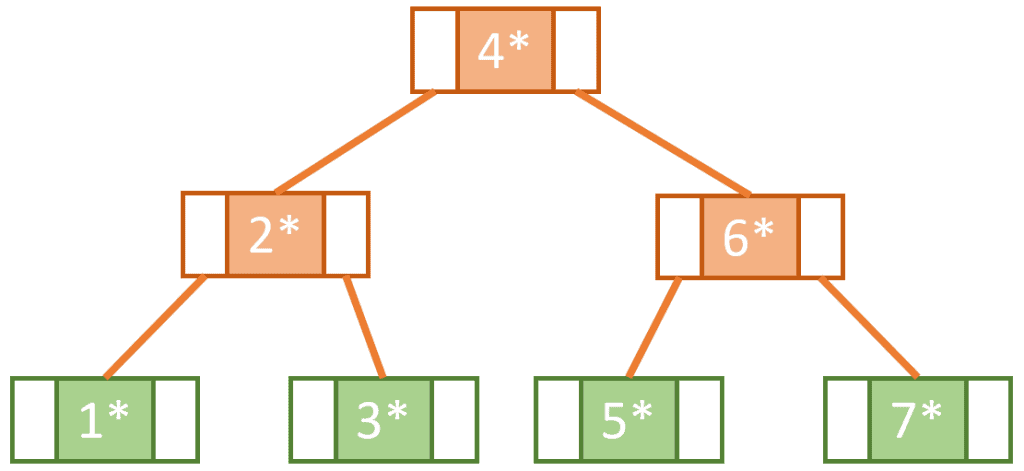
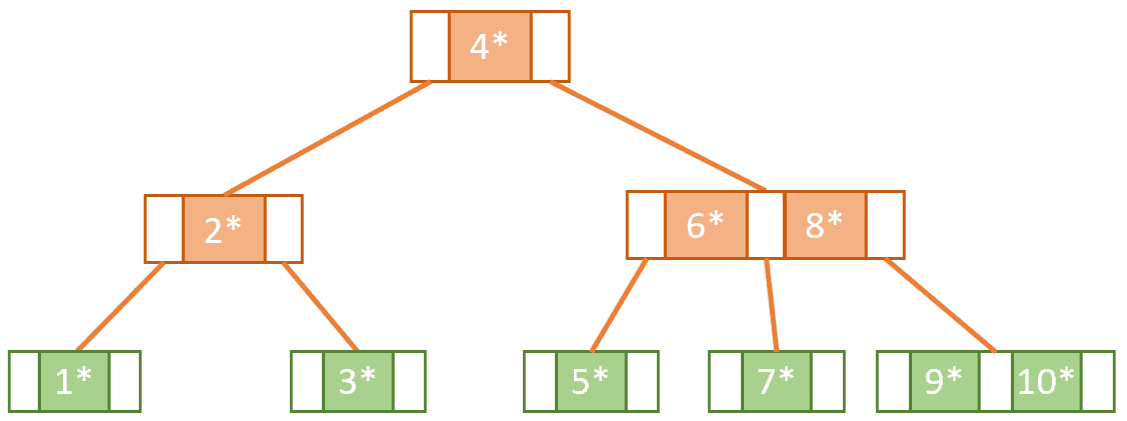
下图展示了一个 B 树示例。该树最多允许 3 个子节点,因此它是 3 阶 B 树。所有叶子节点位于同一层,根节点和中间节点都至少有两个子节点,满足 B 树的所有条件:


2.2 构建一个 B 树
我们从头开始构建一个 B 树,来看看它是如何插入新节点并保持平衡的。
初始状态下,树是空的。插入第一个元素后,它将成为根节点,包含一个 key/value 对。例如 key 为 1,value 用星号表示,表示它是一个记录引用:
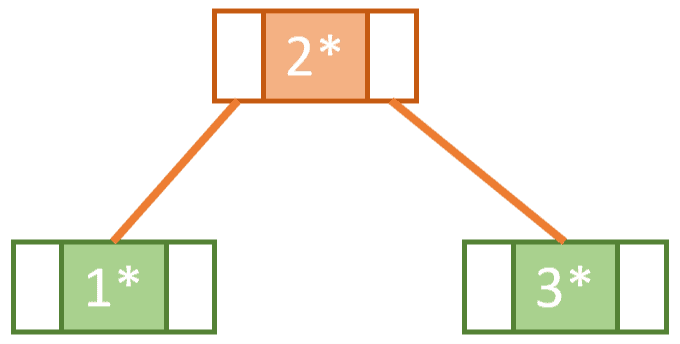
接着我们插入 key 为 3 的记录。此时节点已满,我们需要执行 split 操作来保持平衡。
我们选择中间 key 作为分割点。在这个例子中,中间 key 是 2。因此,左边是 1,右边是 3,中间 key 2 被提升到新的根节点中:
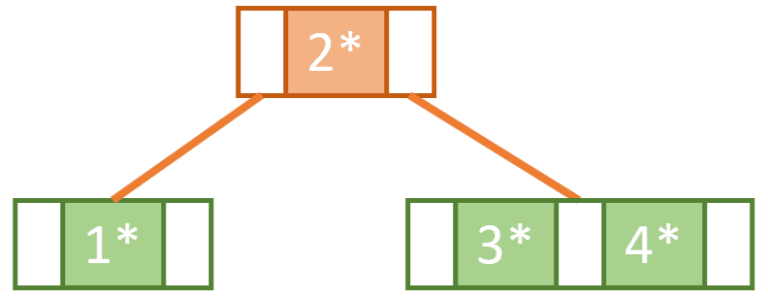
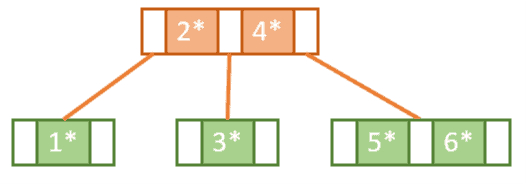
继续插入 key 为 7 的记录。此时右侧节点已满,需要再次 split。同时根节点也满了,因此也需要被拆分。
这个过程分为两步:
- 拆分右子树中的节点 5 和 6,7 放在右边,5 放在左边,6 被提升到父节点
- 根节点拆分,6 成为新的根节点,原根节点的左右子树分别作为其子节点
最终结构如下:
3. 什么是 B+ 树?
B+ 树是 B 树的变种,结构上做了优化,更适合磁盘读取和范围查询。
它的主要特点包括:
✅ 所有数据都只保存在叶子节点中
✅ 叶子节点之间通过指针连接,形成链表结构
✅ 非叶子节点只保存索引信息(key 和子节点指针)
✅ 所有查询最终都落到叶子节点
这种结构使得 B+ 树更适合用于数据库索引,尤其是在进行范围查询时效率更高。
3.1 B+ 树的性质
与 B 树相比,B+ 树具有以下特点:
✅ 叶子节点保存完整数据记录
✅ 所有叶子节点在同一层
✅ 叶子节点之间有指针连接
✅ 非叶子节点只包含 key 和子节点指针
✅ 每个节点最多有 m 个子节点,最少有 ⌈m/2⌉ 个
3.2 构建一个 B+ 树
构建 B+ 树的过程与 B 树类似,但有几个关键区别:
- 所有插入操作都发生在叶子节点
- 内部节点只保存 key,用于导航
- 插入时如果叶子节点满了,则进行 split,并将中间 key 向上传播到父节点
- 所有叶子节点之间保持双向链表连接
下图展示了一个 B+ 树的构建过程:
4. B 树 vs B+ 树:对比分析
| 特性 | B 树 | B+ 树 |
|---|---|---|
| 数据存储位置 | 所有节点都可存储数据 | 数据只在叶子节点 |
| 范围查询效率 | 较低,需中序遍历 | 高,支持链表遍历 |
| 叶子节点链接 | 无 | 有,形成链表 |
| 插入和删除复杂度 | 更复杂 | 相对简单 |
| 磁盘访问效率 | 一般 | 更高 |
| 非叶子节点内容 | key + value + 子节点指针 | key + 子节点指针 |
| 查询路径长度 | 不一定都到叶子节点 | 所有查询都到叶子节点 |
5. 应用场景对比
✅ B 树适合的场景:
- 数据量适中,且经常需要随机访问某些 key
- 希望数据尽可能靠近根节点,减少访问层级
- 实现文件系统等低层存储结构时
✅ B+ 树适合的场景:
- 数据量非常大,需要频繁范围查询(如 SELECT * FROM table WHERE id BETWEEN 100 AND 200)
- 数据库索引结构实现(如 MySQL 的 InnoDB 引擎)
- 需要高效的磁盘 I/O 操作(叶子节点连续、链表结构)
6. 总结
| 关键点 | B 树 | B+ 树 |
|---|---|---|
| 数据分布 | 分布在所有节点 | 仅在叶子节点 |
| 范围查询 | 不友好 | 非常友好 |
| 插入删除 | 更复杂 | 更简单 |
| 磁盘访问效率 | 一般 | 更高 |
| 实现复杂度 | 较高 | 相对简单 |
| 适用场景 | 文件系统、小型数据库 | 大型数据库索引 |
一句话总结:B+ 树是 B 树的增强版,更适合数据库索引的构建和范围查询,是大多数现代数据库的首选索引结构。
💡 踩坑提醒:在做索引设计时,如果你的查询场景中包含大量范围查询或排序操作,一定要优先考虑使用 B+ 树索引,否则可能会出现严重的性能瓶颈。
💬 小贴士:MySQL 的 InnoDB 引擎使用的就是 B+ 树来实现主键索引(聚簇索引),这也是为什么它在处理范围查询时表现优异的原因之一。