1. 概述
Beam Search 是一种常用于搜索最优路径的启发式算法,广泛应用于自然语言处理中的解码过程,如机器翻译、语音识别等。它本质上是一种改进的贪心搜索算法,结合了广度优先搜索(BFS)和最佳优先搜索(BeFS)的特点。
在本文中,我们将深入解析 Beam Search 的工作原理、伪代码实现、实际应用示例,以及 Beam Width(束宽)的作用和影响。
2. Beam Search 的工作原理
Beam Search 是一种启发式搜索算法,与广度优先搜索(BFS)和最佳优先搜索(BeFS)有相似之处。事实上,BeFS 和 BFS 可以看作是 Beam Search 的两种特例。
我们假设有一个图 G,目标是从起点出发,找到通往目标节点的最优路径。Beam Search 的核心思想是:在每一步扩展节点时,只保留最有希望的 β 个候选节点。这个 β 被称为 beam width(束宽)。
具体流程如下:
- 从根节点开始,扩展所有可能的子节点;
- 根据启发式函数(如路径代价、概率等)评估所有候选节点;
- 保留评估值最高的 β 个节点;
- 重复上述步骤,直到找到目标节点或达到序列结束。
📌 注意:
- 如果 β = 1,Beam Search 就退化为 BeFS;
- 如果 β = ∞,则相当于 BFS,因为此时会保留所有可能的扩展节点。
3. Beam Search 伪代码
以下是一个 Beam Search 的伪代码实现:
algorithm BeamSearch(G, s, g, β):
// G: 搜索图
// s: 起始节点
// g: 目标节点
// β: 束宽(beam width)
openList <- {s} // 待扩展节点集合
closedList <- empty // 已访问节点集合
path <- empty // 最终路径
while openList not empty:
b <- 从 openList 中选择最优节点
openList.remove(b)
closedList.add(b)
if b == g:
path.add(b)
return path
N <- b 的所有邻居节点
for n in N:
if n 未在 closedList 或 openList 中:
openList.add(n)
else if n 在 openList 中:
if 当前路径代价 <= 旧路径代价:
替换 n 的父节点
else if n 不在 closedList:
openList.add(n)
if openList.size > β:
openList <- 保留 openList 中最优的 β 个节点
return path
4. Beam Search 示例
Beam Search 在 NLP 领域中应用非常广泛,特别是在 Encoder-Decoder 模型中,比如机器翻译任务。在解码阶段,每一步都可能有多个候选词,Beam Search 通过保留 β 个最优路径来寻找整体最优解。
示例说明
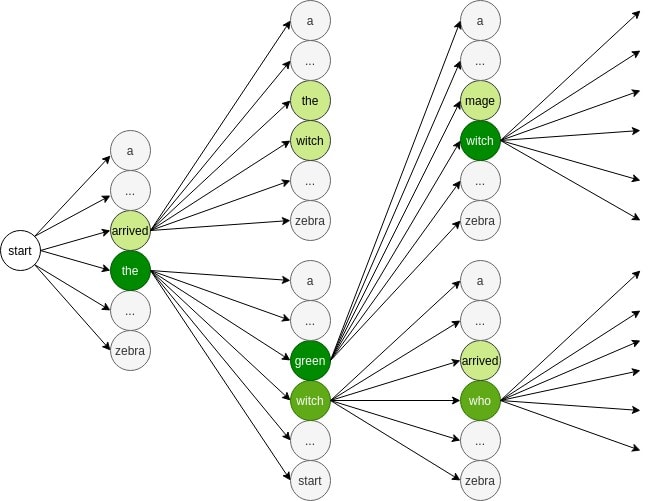
假设我们正在翻译一句话,词典中有如下候选词:arrived、the、green、witch、mage、who 等。
我们设定 β = 2,表示每一步保留两个最优路径:
- 初始阶段,选择概率最高的两个词:arrived 和 the
- 扩展这两个词,得到新的组合:arrived the、arrived witch、the green、the witch
- 再次选择概率最高的两个:the green、the witch
- 继续扩展,得到更多组合,如:the green witch、the witch who
- 最终选择概率最高的完整句子作为翻译结果
📌 踩坑提醒:
- 如果 β 设置过小,可能会遗漏真正最优的长依赖路径;
- 如果 β 设置过大,会显著增加内存和计算开销。
5. Beam Search 的特点
5.1 优缺点分析
✅ 优点:
- 相比 BeFS,内存占用更少,因为它只保留 β 个最优节点;
- 可控性高,通过调节 β 可在准确率与效率之间做权衡。
❌ 缺点:
- 不保证能找到最优解(非最优算法);
- 不保证能找到解(非完备算法);
- 依赖启发式函数的设计质量。
5.2 Beam Width 的作用
Beam Width 是 Beam Search 的关键超参数,直接影响搜索效果:
- β 越大:搜索路径更多,结果更优,但内存和计算开销更大;
- β 越小:速度快,内存占用低,但容易陷入局部最优。
📌 建议:
- 一般在实际项目中,β 设置为 5~10 是常见做法;
- 对于对翻译质量要求高的场景,可以适当调大 β;
- 对于资源受限的设备,可以调小 β。
6. 总结
Beam Search 是一种高效的启发式搜索算法,广泛应用于 NLP 领域的解码任务中。它通过保留每一步中最优的 β 个候选路径,平衡了搜索效率与结果质量。
关键点回顾:
- Beam Search 是 BeFS 和 BFS 的折中方案;
- 使用 Beam Width 控制搜索宽度;
- 适用于机器翻译、语音识别等需要序列生成的场景;
- 优点是内存效率高,缺点是不保证最优解;
- 调节 Beam Width 是优化 Beam Search 的关键。
在实际项目中,理解 Beam Search 的工作原理和参数影响,能帮助你更好地设计和优化模型解码策略。