1. 概述
在本教程中,我们将介绍渐进符号(Asymptotic Notations)的基本概念,并为每种符号提供示例说明。我们将讨论 Big Θ(Theta)、Big Ω(Omega) 和 Big O 符号。
这些符号是分析算法时间复杂度和空间复杂度的核心工具,能帮助我们理解算法在输入规模增大时的表现。
2. 评估算法
在编程和计算机科学中,开发者常常面临代码效率的问题。渐进符号,特别是 Big O 符号,能帮助我们预测和分析算法的效率。 这些知识也会影响我们设计算法时的选择,特别是性能方面。
举个例子,假设我们有一段在小数据集上运行良好的代码,但未来数据量会显著增长,我们需要评估当前算法是否还能保持良好的性能。
以下是一个查找元素是否存在于列表中的伪代码示例:
algorithm FindElement(list, element):
// INPUT
// list = A list of elements
// element = The element to search for in the list
// OUTPUT
// true if the element is in the list, false otherwise
for listElement in list:
if listElement == element:
return true
return false
这段代码非常简单,它遍历整个列表查找目标元素。我们尝试评估它的性能。最直观的方式是用执行时间来衡量,但这种方式会受到硬件、输入规模、实现细节等因素的影响,不具备普适性。
另一种方法是统计执行步骤的数量。但这种方法仍然依赖于具体实现,比如多加一个判断语句,就会改变复杂度的统计结果。
因此,我们通常将每个元素的处理时间视为一个基本单位。 例如,如果我们要查找的元素位于列表中间,我们大概需要 n/2 个单位时间。
- 最佳情况:目标元素是第一个,只需检查一次。
- 最坏情况:目标元素不存在,必须遍历整个列表。
- 平均情况:如果元素分布随机,平均需要检查一半的元素。
3. Big O 表示法
回到上面的例子,查找元素所需的时间取决于它在列表中的位置。Big O 表示法用于描述算法的最坏情况下的性能。
3.1 正式定义
Big O 表示法定义了一个函数,它在某个点之后始终大于或等于原函数的值。我们只关心复杂度的增长趋势,而不是具体数值,因此可以忽略常数因子。
✅ 定义:
我们说 f(n) = O(g(n)),当且仅当存在两个正常数 c 和 n₀,使得对于所有 n ≥ n₀,都有 0 ≤ f(n) ≤ c·g(n)。
3.2 示例
考虑如下算法:
algorithm SortAndPrint(list):
// INPUT
// list = A list of elements
// OUTPUT
// Sorts the list, prints each element, and writes it to a file
bubbleSort(list)
for element in list:
print(element)
writeToFile(list)
我们可以分析它的复杂度:
bubbleSort(list)的复杂度为O(n²)print(element)是线性操作,复杂度为O(n)writeToFile(list)是常数时间操作,复杂度为O(1)
因此,整个算法的复杂度为:
O(n² + n + 1)
当 n 很大时,低阶项和常数项对整体影响极小,可以忽略。最终复杂度简化为:
✅ O(n²)
3.3 Big O 的图形表示
我们来看一个函数 y = n² + n + 3 的图像:
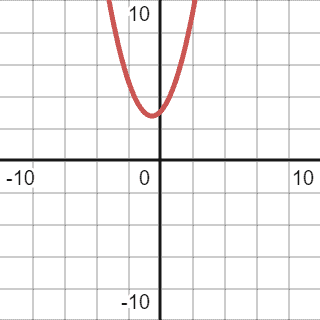
如果我们尝试用线性函数(如 x, 2x, 3x)去“包住”这个二次函数,会发现它无法覆盖整个函数曲线,因为二次函数增长得更快。
如果我们尝试用立方函数 y = x³ 来逼近,虽然在某些区间内可以覆盖,但这个逼近函数过于宽松,不是最优选择。
✅ **正确的做法是使用一个二次函数,比如 y = 1.2n²**,它在某个点之后始终高于原函数,且逼近程度最紧。
最终我们可以得出结论:
✅ 该算法的 Big O 表示为 O(n²)
4. Big Ω 表示法
Big Ω 表示的是算法的下界,也就是最佳情况下的性能。
回到上面的 SortAndPrint 示例:
- 如果列表已经排序完成,
bubbleSort只需遍历一次,复杂度为O(n) - 但这只是理想情况,实际中我们不能总是假设输入是完美的
✅ Big Ω 应该尽可能紧贴原函数,不能过于乐观。
对于 SortAndPrint:
- 最佳情况是线性复杂度
Ω(n) - 但考虑到
bubbleSort的最坏情况是O(n²),所以其 Big Ω 也应为 Ω(n²)
⚠️ 不能因为理想情况好就认为算法总是如此高效。
5. Big Θ 表示法
Big Θ 是 Big O 和 Big Ω 的结合体,表示算法的紧确界。
✅ 定义:
当存在两个常数 c1 和 c2,使得:
c1·g(n) ≤ f(n) ≤ c2·g(n)
则 f(n) = Θ(g(n))
示例
假设我们有两个函数:
f(n) = n² + n + 1g(n) = n²
我们可以找到两个常数(如 0.8 和 1.2)使得:
0.8n² ≤ n² + n + 1 ≤ 1.2n²
✅ 因此,f(n) = Θ(n²)
图形上表示如下:
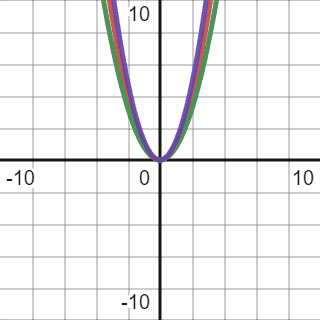
两个不同系数的二次函数夹住原函数,说明其复杂度为 Θ(n²)
6. 总结
本篇文章介绍了三种常见的渐进符号:
| 符号 | 含义 | 描述 |
|---|---|---|
| Big O | 上界 | 最坏情况下的性能 |
| Big Ω | 下界 | 最佳情况下的性能 |
| Big Θ | 紧确界 | 性能上下限一致时使用 |
这些符号帮助我们更系统地分析算法的效率,即使现代计算机的性能大幅提升,但数据规模也在指数级增长,因此我们仍需关注算法复杂度。
在实际开发中,通常只需关注 Big O,因为它代表了最坏情况下的性能边界,对系统设计和性能优化至关重要。
如果你对 Java 中算法复杂度的实际应用感兴趣,可以参考 这篇文章。