1. 概述
本文将介绍二叉搜索树(Binary Search Tree, BST)这种数据结构,重点讨论当节点中存储的键值为字符串时的应用场景与实现细节。
2. 简介
BST 是一种满足以下特性的二叉树:
- 每个节点的左子树中所有节点的键值都小于该节点的键值;
- 每个节点的右子树中所有节点的键值都大于该节点的键值;
- 左右子树本身也必须是二叉搜索树。
在实际开发中,我们经常遇到键值为字符串的情况。这时,我们需要先定义字符串之间的比较规则。
字符串比较规则
我们使用字典序(Lexicographic Ordering)来比较两个字符串。具体做法是从左到右依次比较字符,遇到第一个不同的字符时,根据 Unicode 编码顺序决定大小关系。
例如:
"apple" < "orange"因为'a'在'o'前面;"Orange" > "orange"因为大写字母 Unicode 编码小于小写;"apple" == "apple"因为所有字符都相同。
下图展示了两个字符串构成的二叉树:
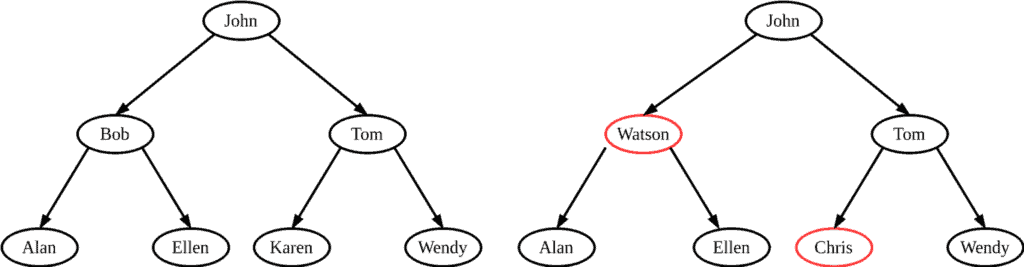
左边是合法的 BST,右边不是,因为红色节点破坏了 BST 的性质。
3. 基本操作
BST 最常见的操作包括:插入、查找、删除。对于字符串类型的键值,核心在于如何正确进行字符串比较。
3.1 插入操作
插入逻辑如下:
- 从根节点出发,向下查找插入位置;
- 每次比较当前节点字符串与目标字符串,决定是进入左子树还是右子树;
- 找到空位置后插入新节点。
插入伪代码如下:
algorithm BSTInsert(T, z):
y <- null
x <- T.root
while x is not null:
y <- x
if z.key < x.key:
x <- x.left
else:
x <- x.right
z.parent <- y
if y is null:
T.root <- z
else if z.key < y.key:
y.left <- z
else:
y.right <- z
3.2 删除操作
删除操作较为复杂,分为三种情况:
✅ 情况一:节点没有子节点 → 直接删除
✅ 情况二:节点只有一个子节点 → 用子节点替换该节点
✅ 情况三:节点有两个子节点 → 找到其后继节点(右子树中最小节点)替换当前节点
删除伪代码如下:
algorithm BSTDelete(T, z):
if z.left is null:
TRANSPLANT(T, z, z.right)
else if z.right is null:
TRANSPLANT(T, z, z.left)
else:
y <- TREE-MINIMUM(z.right)
if y.parent != z:
TRANSPLANT(T, y, y.right)
y.right <- z.right
y.right.parent <- y
TRANSPLANT(T, z, y)
y.left <- z.left
y.left.parent <- y
3.3 辅助函数 TRANSPLANT
TRANSPLANT 函数用于将一个子树替换另一个子树,是删除操作的核心部分。
algorithm TRANSPLANT(T, a, b):
if a.parent is null:
T.root <- b
else if a = a.parent.left:
a.parent.left <- b
else:
a.parent.right <- b
if b is not null:
b.parent <- a.parent
4. 时间复杂度分析
BST 中所有操作的时间复杂度均与树的高度有关。假设树高为 h,则各操作的时间复杂度如下:
| 操作 | 时间复杂度 |
|---|---|
| 查找 | ✅ O(h) |
| 插入 | ✅ O(h) |
| 删除 | ✅ O(h) |
⚠️ 注意:如果树退化为链表(例如插入顺序是有序的),则 h = n,此时时间复杂度变为 O(n)。为避免这种情况,通常会使用平衡树结构如 AVL 树、红黑树等。
5. 总结
本文介绍了在键值为字符串的情况下,如何使用二叉搜索树进行插入、查找和删除操作。核心在于理解字符串的比较规则(字典序)以及如何维护 BST 的结构。对于有经验的开发者来说,字符串 BST 是一个基础但实用的数据结构,尤其适用于字符串集合的有序管理场景。