1. 概述
在本教程中,我们将研究暴力搜索算法(Brute-force Algorithm)的基本原理及其在字符串搜索和网络安全中的常见应用场景。
我们会先从组合问题的角度出发,定义暴力搜索的基本思路;随后,我们再将其简化为字符串子串查找的实现方式。
学习完本教程后,你将理解:
- 暴力搜索算法的工作原理
- 为什么它在某些场景下效率极低
- 如何在实际中实现一个字符串暴力匹配算法
2. 什么是暴力搜索算法?
暴力搜索是一种通过穷举所有可能解来解决问题的算法策略。它不依赖任何启发式信息,也不做任何优化,只是简单地尝试所有可能性,直到找到目标为止。
2.1. 针对已知长度序列的暴力搜索
假设我们有一个字符集合 $ S = {s_1, s_2, ..., s_k} $,以及目标序列的长度 $ n $。我们可以按以下步骤尝试生成所有可能的组合:
- 先尝试全由 $ s_1 $ 构成的序列
- 若失败,将第一个字符依次替换为 $ s_2, s_3, ..., s_k $
- 若仍失败,将第二个字符设为 $ s_2 $,并重新开始替换第一个字符
- 依此类推,直到遍历完所有字符组合
✅ 举例:字符集为 {a, b},长度为 2,则可能的组合为:
aa
ab
ba
bb
2.2. 时间复杂度分析
暴力搜索的最坏时间复杂度为:
✅ **$ O(k^n) $**,其中 $ k $ 是字符种类数,$ n $ 是序列长度
⚠️ 这个复杂度增长非常快。例如:
- 长度为 8,字符集为 26 个字母:$ 26^8 \approx 2 \times 10^{11} $
- 长度为 10,字符集为 ASCII(128 个字符):$ 128^{10} \approx 10^{21} $
如果每秒能尝试 $ 10^9 $ 次组合,那破解一个 10 位 ASCII 密码需要约 $ 10^5 - 10^6 $ 年!
2.3. 未知长度序列的暴力搜索
如果目标序列长度未知,但已知是有限的,我们可以通过逐步增加长度的方式尝试:
- 先尝试长度为 1 的组合
- 再尝试长度为 2 的组合
- 依此类推,直到找到匹配
✅ 最终时间复杂度依然为 $ O(k^n) $,因为最后一步是主导项
3. 字符串暴力搜索算法
暴力搜索在字符串匹配中也有广泛应用,例如在文本中查找某个子串的位置。
3.1. 示例:在文本中查找 "truth"
我们来看一个字符串匹配的示例:在以下句子中查找 "truth" 子串:
“It is a truth universally acknowledged, that a single man in possession of a good fortune, must be in want of a wife.”
算法流程如下:
- 从第一个字符开始,逐个字符比较
- 若不匹配,整体向右移动一位
- 直到完全匹配或遍历完整个字符串
3.2. 算法流程图
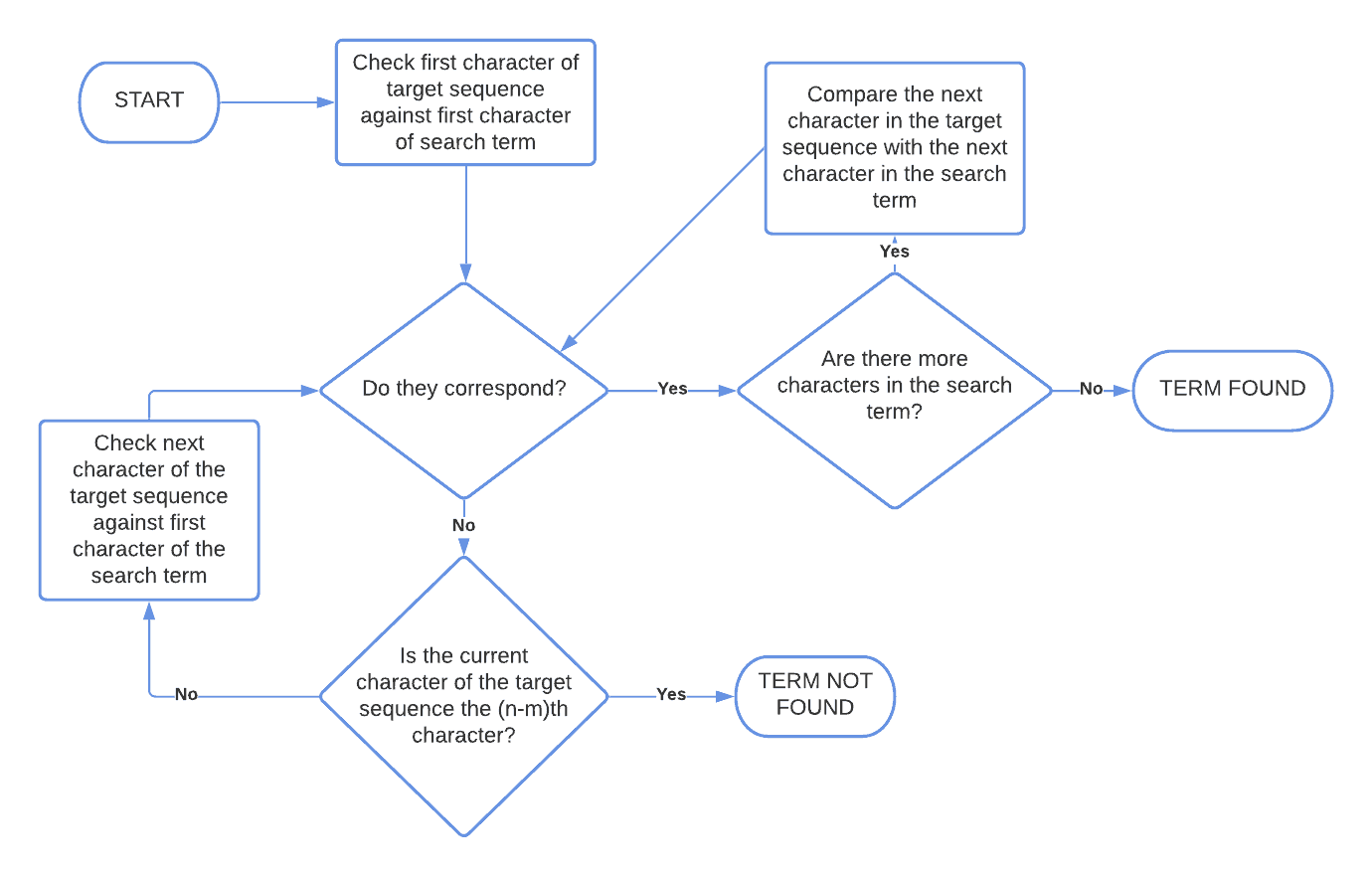
3.3. 时间复杂度分析
- 最好情况:子串在开头就匹配,时间复杂度为 $ O(m) $
- 最坏情况:每次都要比较到子串末尾才失败,时间复杂度为 $ O(nm) $
- 平均情况下,比较次数约为 $ 2n $ 次字符比较
4. 总结
✅ 本文我们学习了:
- 暴力搜索算法的基本原理
- 它在组合问题和字符串搜索中的应用
- 时间复杂度分析及实际场景中的效率问题
❌ 暴力搜索虽然简单直观,但效率低下,不适合大规模数据匹配。
✅ 实际开发中应优先考虑更高效的算法如 KMP、Boyer-Moore 等,但在某些小规模或安全性测试场景中,暴力搜索仍有其价值。
如果你正在开发一个密码强度检测系统或进行安全渗透测试,了解暴力搜索的原理和性能表现是非常有必要的。