1. 问题描述
目标:判断一棵二叉树是否是合法的二叉搜索树(Binary Search Tree, BST)。
验证 BST 的核心逻辑是:
- 左子树中所有节点的值都小于当前节点值
- 右子树中所有节点的值都大于当前节点值
- 左右子树本身也必须是 BST
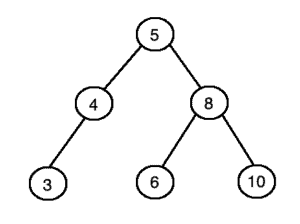
如下图所示,这是一个合法的 BST:
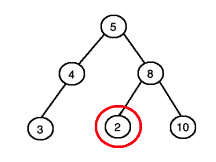
而下面这张图中,右子树中有一个节点值(红色圈出)小于根节点值,因此不是 BST:
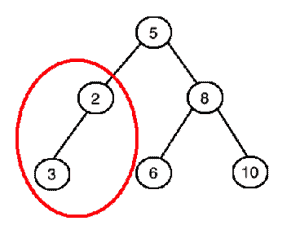
下图中,虽然根节点的左右子树满足大小关系,但左子树本身不是 BST(红色圈出),因此整棵树也不是 BST:
2. 算法思路
2.1. 简单暴力法(不推荐)
❌ 错误做法:只判断当前节点与其左右子节点的关系(左小右大)
⚠️ 问题:无法判断子树中是否存在非法节点,例如左子树中某个节点值大于根节点
✅ 正确做法:
- 遍历左子树,确认所有节点值都小于当前节点值
- 遍历右子树,确认所有节点值都大于当前节点值
- 递归检查左右子树是否也是 BST
时间复杂度:最坏情况下为 O(n²)
2.2. 高效方法:上下界限制法
核心思想:在递归过程中维护当前节点的取值范围(lowerLimit < val < upperLimit)
- 进入左子树时,upperLimit = 当前节点值
- 进入右子树时,lowerLimit = 当前节点值
boolean isValidBST(TreeNode node, Integer low, Integer high) {
if (node == null) return true;
if ((low != null && node.val <= low) || (high != null && node.val >= high)) {
return false;
}
return isValidBST(node.right, node.val, high) && isValidBST(node.left, low, node.val);
}
✅ 优点:每个节点只访问一次
✅ 时间复杂度:O(n)
✅ 空间复杂度:O(h),h 为树的高度(递归栈开销)
2.3. 中序遍历法
核心思想:BST 的中序遍历结果一定是升序排列
List<Integer> list = new ArrayList<>();
inorder(root, list);
return isSorted(list);
void inorder(TreeNode root, List<Integer> list) {
if (root != null) {
inorder(root.left, list);
list.add(root.val);
inorder(root.right, list);
}
}
boolean isSorted(List<Integer> list) {
for (int i = 1; i < list.size(); i++) {
if (list.get(i) <= list.get(i - 1)) return false;
}
return true;
}
✅ 优点:逻辑清晰
⚠️ 缺点:需要额外空间存储遍历结果
✅ 时间复杂度:O(n)
✅ 空间复杂度:O(n)
2.4. 优化版中序遍历法(空间优化)
核心思想:只记录前一个节点值,比较当前节点是否大于前一个节点
Integer prev = null;
boolean isValid = true;
boolean isValidBST(TreeNode root) {
inorder(root);
return isValid;
}
void inorder(TreeNode root) {
if (root == null) return;
inorder(root.left);
if (prev != null && root.val <= prev) {
isValid = false;
return;
}
prev = root.val;
inorder(root.right);
}
✅ 优点:无需额外列表存储
✅ 时间复杂度:O(n)
✅ 空间复杂度:O(h)
3. 复杂度分析对比
| 方法 | 时间复杂度 | 空间复杂度 | 是否推荐 |
|---|---|---|---|
| 暴力法 | O(n²) | O(n) | ❌ 不推荐 |
| 上下界法 | O(n) | O(h) | ✅ 推荐 |
| 中序遍历 + 列表 | O(n) | O(n) | ✅ 推荐 |
| 中序遍历 + 前值比较 | O(n) | O(h) | ✅ 推荐 |
4. 总结
验证 BST 的关键在于:
- 不能只看当前节点与子节点的大小关系
- 必须保证整个子树满足 BST 性质
- 使用上下界限制或中序遍历是高效做法
最优解法:使用上下界法或优化版中序遍历,时间复杂度为 O(n),空间复杂度为 O(h)(递归栈)
✅ 推荐使用上下界法,逻辑清晰且易于调试。
✅ 中序遍历法适合在需要获取遍历顺序的场景中复用。