1. 计算机内存基础
现代计算机内存通常按照一个五层的金字塔结构进行组织。每一层在以下三个关键指标上有所不同:
- 访问时间:从请求数据到接收到数据所经历的时间
- 存储容量:内存设备可保存的最大数据量
- 每比特成本:每比特内存的平均成本
下图展示了经典的内存层次结构:
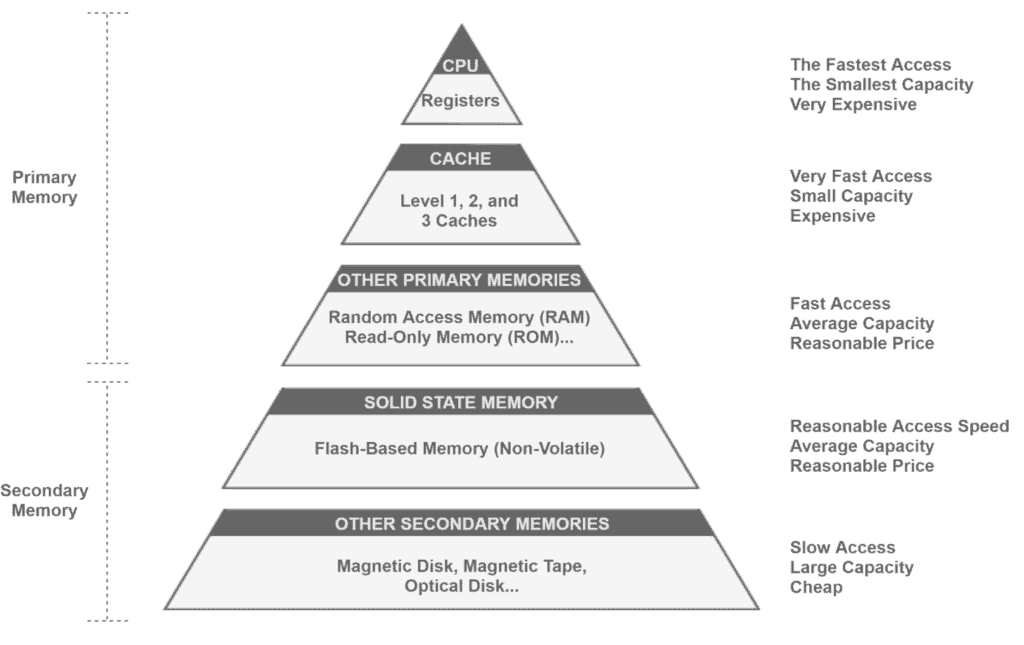
要理解内存层次结构,首先要区分主存(Primary Memory) 和 辅存(Secondary Memory)。主存是 CPU 可以直接访问的内存,而辅存中的数据必须先加载到主存中才能被 CPU 使用。主存通常是易失性的(如 RAM),而辅存是非易失性的(如硬盘)。不过也有例外,比如 ROM(只读存储器)就是非易失性主存。
1.1 内存层次结构层级
- 寄存器(Registers):位于 CPU 内部,访问速度最快,但容量极小,成本极高。
- 高速缓存(Cache):紧邻 CPU,通过专用总线连接,容量大于寄存器,速度仅次于寄存器。
- 主存(RAM、ROM 等):常见的如随机访问存储器(RAM),用于临时存储 CPU 需要的数据和指令。
- 固态辅存(SSD 等):没有机械结构,读写速度快,能耗低,价格高于传统硬盘。
- 传统辅存(HDD、光盘、磁带等):容量大、成本低,但访问速度慢。
2. 缓存内存概述
CPU 的运行速度远高于主存的访问速度,这就导致了性能瓶颈。为缓解这个问题,缓存作为 CPU 和主存之间的一层高速存储,通过专用总线与 CPU 连接,提前加载 CPU 可能需要的数据和指令。
缓存的设计目标是结合小容量高速存储(如寄存器 + 缓存)和大容量低速存储(如 RAM),从而在整体上实现接近高速内存的性能,同时具备大容量内存的实用性。
2.1 局部性原理(Principle of Locality)
缓存之所以有效,是因为程序访问内存时存在局部性特征,分为:
- ✅ 时间局部性(Temporal Locality):刚被访问的数据很可能在短时间内再次被访问。
- ✅ 空间局部性(Spatial Locality):访问某个内存地址后,其附近的地址也很可能被访问。
缓存利用这两个特性,提前加载数据,提高命中率,减少访问主存带来的延迟。
2.2 缓存层级结构
现代 CPU 通常采用多级缓存结构,常见的有:
- L1 缓存:速度最快,容量最小(通常为 16KB ~ 512KB),通常分为指令缓存和数据缓存。
- L2 缓存:速度稍慢于 L1,容量更大(128KB ~ 24MB),通常由两个 CPU 核心共享。
- L3 缓存:速度最慢,容量最大(2MB ~ 32MB),由多个 CPU 核心共享。
某些高端处理器(如 Intel 的 Haswell、Broadwell)还引入了 L4 缓存,用于连接 CPU 和 GPU。
2.3 缓存命中与未命中
当 CPU 请求数据时,会依次从 L1 → L2 → L3 → 主存中查找:
- ✅ 缓存命中(Cache Hit):所需数据在当前缓存中。
- ❌ 缓存未命中(Cache Miss):所需数据不在当前缓存中。
命中率是衡量缓存性能的重要指标,计算公式如下:
$$ \text{Hit Ratio} = \frac{\text{Hit}{\text{total}}}{\text{Hit}{\text{total}} + \text{Miss}_{\text{total}}} $$
命中率越接近 1,说明缓存效率越高。
⚠️ 注意:即使硬件完全相同的缓存系统,因缓存写入策略不同,也可能导致性能差异。
2.4 上下文切换对缓存的影响
在多任务操作系统中,CPU 会频繁进行上下文切换(Context Switching),即中断一个进程并切换到另一个进程。
每个进程在运行时都会有一组活跃的数据和指令,称为工作集(Working Set)。缓存会尽可能加载这些数据。但在上下文切换后,缓存中可能残留的是前一个进程的数据,导致新进程开始运行时出现大量缓存未命中。
⚠️ 影响因素:
- 缓存容量
- 缓存写入策略
- 进程的内存访问模式
因此,频繁的上下文切换会显著降低缓存效率,增加 CPU 等待时间。
3. 总结
缓存是现代计算机系统中至关重要的组成部分。它通过局部性原理和多级缓存结构,在成本与性能之间取得了良好平衡。
虽然缓存不能直接提升 CPU 的计算能力,但它能显著减少 CPU 等待数据的时间,从而提升整体系统性能。
✅ 关键点总结如下:
| 层级 | 类型 | 特点 |
|---|---|---|
| L1 | 最快、最小 | 每个核心独享 |
| L2 | 中等速度、中等容量 | 两个核心共享 |
| L3 | 最慢、最大 | 多个核心共享 |
| L4(可选) | 连接 CPU 与 GPU | 特殊用途 |
缓存性能受上下文切换影响较大,因此在高并发或频繁切换进程的场景中,应特别关注缓存利用率和命中率。
💡 踩坑提醒:
- 频繁的上下文切换会导致缓存污染(Cache Pollution),进而影响性能。
- 不同的缓存写入策略(如 Write-Through 与 Write-Back)会影响命中率与一致性。
缓存机制看似简单,但其背后涉及复杂的硬件设计与调度策略,理解其工作原理有助于编写更高效的程序,减少性能瓶颈。