1. 简介
候选消除算法(Candidate Elimination Algorithm,CEA)是一种监督学习方法,用于从数据中学习概念。它基于概念空间中的假设集,通过逐步缩小可能的假设范围,找到与训练数据一致的版本空间(Version Space)。
CEA 的核心思想是通过泛化(Generalization)和特化(Specialization)操作,维护两个边界:
- G 集合(General Boundary):最通用的假设集合
- S 集合(Specific Boundary):最具体的假设集合
这两个边界共同定义了当前可能的假设范围。随着新样本的加入,不断调整 G 和 S,最终收敛到一个版本空间。
✅ 适用于分类任务,尤其是布尔函数学习
❌ 不适用于连续输出或非监督任务
2. 概念学习基础
在机器学习中,“概念”是指一组具有共同特征的对象集合。例如,“鸟”是一个概念,它包含所有鸟类动物,但不包括爬行动物或鱼类。
在概念学习中,我们面对的是一个带标签的数据集:
- 正样本(Positive):属于目标概念
- 负样本(Negative):不属于目标概念
我们的目标是找出一个布尔函数,使得它对所有正样本返回 true,对所有负样本返回 false。
3. 示例:水上运动偏好学习
我们以一个天气数据集为例,看看 CEA 是如何工作的。
| Sky | AirTemp | Humidity | Wind | Water | Forecast | EnjoySport |
|---|---|---|---|---|---|---|
| Sunny | Warm | Normal | Strong | Warm | Same | Yes |
| Sunny | Warm | High | Strong | Warm | Same | Yes |
| Rainy | Cold | High | Strong | Warm | Change | No |
| Sunny | Warm | High | Strong | Cool | Change | Yes |
目标:学习一个布尔函数,当 EnjoySport = Yes 时返回 true。
我们定义假设空间 H 为:
- 每个属性可以是:
- 某个具体值(如
Sunny) ?表示任意值∅表示无值
- 某个具体值(如
例如:
- 假设
⟨Sunny, Warm, ?, ?, ?, ?⟩表示“晴天、气温温暖”的所有情况
4. 候选消除算法原理
CEA 通过维护两个边界(G 和 S)来逐步缩小假设空间,直到找到与训练数据一致的版本空间。
4.1 泛化与特化关系
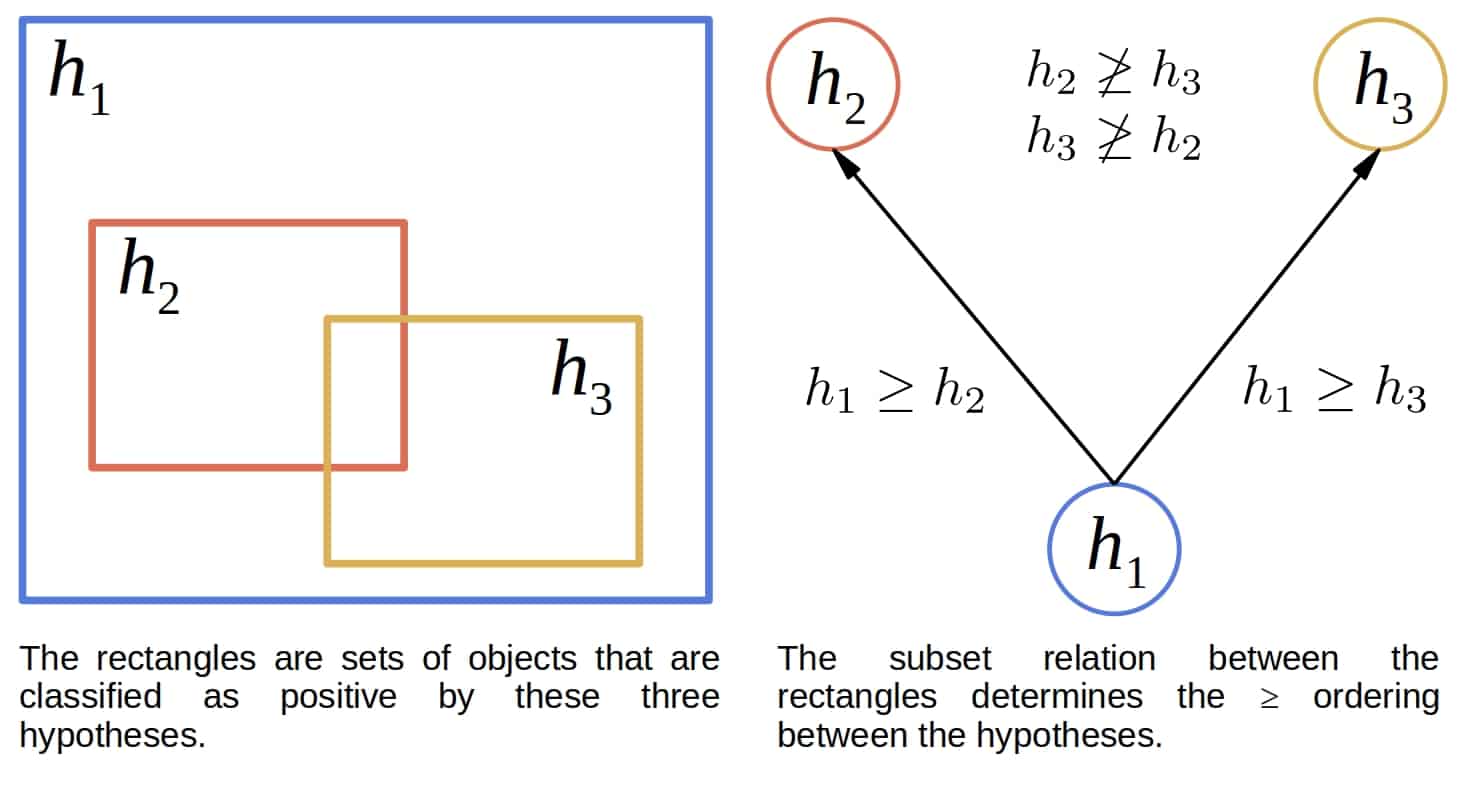
我们定义两个假设之间的“泛化”关系:
- 如果假设
h1对所有h2返回true的样本也返回true,那么h1 ≥ h2 >表示严格泛化<表示严格特化
这种关系在概念空间中形成一个偏序关系(Partial Order),可以形象地表示为:
4.2 算法流程
algorithm CandidateElimination(D):
Initialize G to the most general hypothesis
Initialize S to the most specific hypothesis
for each object x in D:
if x is positive:
remove from G any hypothesis inconsistent with x
remove from S any hypothesis inconsistent with x
generalize S to cover x
specialize G to exclude inconsistent hypotheses
else:
remove from S any hypothesis inconsistent with x
remove from G any hypothesis inconsistent with x
specialize G to exclude x
generalize S to include consistent hypotheses
return version space V(G, S)
5. 实例演示
我们用前面的水上运动数据来演示 CEA 的运行过程。
5.1 初始化
- G₀ = {⟨?,?,?,?,?,?⟩}
- S₀ = {⟨∅,∅,∅,∅,∅,∅⟩}
初始版本空间是整个假设空间。
5.2 处理第一个正样本
输入:⟨Sunny, Warm, Normal, Strong, Warm, Same⟩
- G₀ 中的假设仍然一致
- S₀ 中的假设太具体,无法覆盖该样本 → 用该样本泛化 S
更新后:
- G₁ = G₀
- S₁ = {⟨Sunny, Warm, Normal, Strong, Warm, Same⟩}
5.3 处理第二个正样本
输入:⟨Sunny, Warm, High, Strong, Warm, Same⟩
- G₁ 仍然一致
- S₁ 太具体 → 用该样本泛化 S₁
更新后:
- G₂ = G₁
- S₂ = {⟨Sunny, Warm, ?, Strong, Warm, Same⟩}
5.4 处理第一个负样本
输入:⟨Rainy, Cold, High, Strong, Warm, Change⟩
- S₂ 一致
- G₂ 太泛化 → 特化 G₂,排除该样本
更新后:
- G₃ = {⟨Sunny,?,?,?,?,?⟩, ⟨?,Warm,?,?,?,?,?⟩, ⟨?,?,?,?,?,Same⟩}
- S₃ = S₂
5.5 处理第三个正样本
输入:⟨Sunny, Warm, High, Strong, Cool, Change⟩
- S₃ 一致
- G₃ 中的 ⟨?,?,?,?,?,Same⟩ 不一致 → 移除
- S₃ 泛化为 ⟨Sunny, Warm, ?, Strong, ?, ?⟩
最终:
- G₄ = {⟨Sunny,?,?,?,?,?⟩, ⟨?,Warm,?,?,?,?,?⟩}
- S₄ = {⟨Sunny, Warm, ?, Strong, ?, ?⟩}
6. CEA 收敛性
- 如果假设空间 H 中存在一个假设能正确分类所有训练数据,且数据无误,则 CEA 能找到包含该假设的版本空间
- 如果最终版本空间只包含一个假设,则 CEA 收敛到该假设
- 如果数据有误或 H 中无一致假设,则版本空间为空
7. 加速 CEA
CEA 的收敛速度取决于样本的处理顺序。每次将版本空间缩小一半可以最快收敛。
一种有效方法是让 CEA 主动选择下一个要处理的样本,使得它能最大程度地缩小版本空间。
8. 部分学习的概念
如果版本空间中包含多个假设,则说明目标概念只是部分学习。
此时我们可以:
- 共识分类:所有假设一致时才分类
- 多数投票:按多数假设分类
- 概率分类:正样本比例作为概率
共识分类只需检查 G 和 S 边界即可,无需遍历所有假设。
9. 无限制假设空间
如果我们允许假设空间 H 包含所有可能组合(包括析取、合取、否定等),那么:
- 过拟合风险极高
- 版本空间会记住训练数据,无法泛化
- 新样本分类结果不确定(正负各占一半)
因此,必须对假设空间进行合理限制。
10. 归纳偏置与演绎推理
限制假设空间的过程称为归纳偏置(Inductive Bias)。它本质上是学习算法对数据的先验假设。
CEA 的归纳偏置可以表述为:
假设空间 H 包含目标概念
这是最弱的归纳偏置之一。只要这个假设成立,我们就可以用 CEA 推导出正确分类。
11. 小结
候选消除算法是一种基于泛化/特化机制的监督学习方法,适用于布尔函数学习任务。它的核心在于:
- 维护 G 和 S 边界
- 动态调整版本空间
- 收敛于一个或多个假设
虽然 CEA 在理论上非常优雅,但在实际应用中需要注意:
- 假设空间的设计至关重要
- 样本顺序影响收敛速度
- 不适合连续输出或高维数据
✅ 适合教学和理解概念学习机制
⚠️ 实际应用中需结合其他算法使用