1. 概述
在设计或理解卷积神经网络(CNN)时,感受野(Receptive Field)是一个非常关键的概念。它帮助我们分析网络结构的内部机制,并为优化模型提供依据。
简单来说,感受野是指输入图像中影响某个卷积层输出特征的区域大小。这个概念在图像分割、目标检测等任务中尤为重要。例如在图像分割中,如果网络的感受野不够大,就可能无法完整识别大尺寸物体的边界,导致预测结果不完整。
2. 定义与理解
感受野可以理解为:某个卷积层中的一个输出特征值,是由输入张量中的哪一部分区域经过卷积运算得到的。
举个例子:
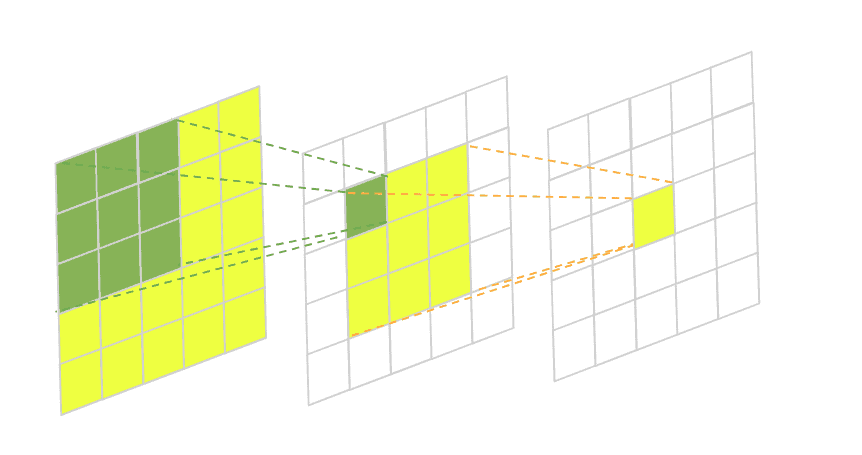
这是一个两层卷积网络的示意图。绿色区域是第二层中一个像素的感受野,黄色区域是第三层一个像素的感受野。可以看到,随着网络加深,感受野逐渐扩大。
我们通常最关心的是输入层的感受野大小,即最终输出特征所依赖的输入图像区域。这直接影响模型对输入信息的感知范围。
3. 计算原理
3.1. 符号说明
我们考虑一个全卷积网络(Fully Convolutional Network, FCN),共 L 层,记第 l 层的输出为 fₗ,输入图像为 f₀,最后一层输出为 fᴸ。
每层卷积操作有三个参数:
- kₗ:卷积核大小(kernel size)
- sₗ:步长(stride)
- pₗ:填充(padding)
我们的目标是计算输入层的感受野大小 r₀。
3.2. 递推公式
我们可以通过递归的方式从最后一层反推到输入层:
✅ 递推公式:
$$ r_{l-1} = s_l \cdot r_l + (k_l - s_l) $$
这个公式考虑了卷积核和步长之间的差异,当 kₗ > sₗ 时,卷积之间会有重叠;当 kₗ < sₗ 时,卷积之间会有空隙。
通过递归展开,最终可以得到输入层的感受野大小:
✅ 最终公式:
$$ r_0 = \sum_{l=1}^{L} \left( (k_l - 1) \cdot \prod_{i=1}^{l-1} s_i \right) + 1 $$
这个公式可以理解为每一层对感受野的“增量”之和。
3.3. 起始与终止位置计算
除了感受野的大小,我们有时也关心它在输入图像中的具体位置范围。我们可以使用如下公式计算起始和结束索引:
✅ 起始索引公式:
$$ u_{l-1} = -p_l + u_l \cdot s_l $$
✅ 结束索引公式:
$$ v_{l-1} = -p_l + v_l \cdot s_l + k_l - 1 $$
这些公式可以帮助我们定位感受野在输入图像中的确切区域,对于调试网络结构很有帮助。
4. 实现方法
4.1. 感受野大小计算伪代码
algorithm AnalyticalSolution(k, s, p, L):
// k = [k_1, k_2, ..., k_L]
// s = [s_1, s_2, ..., s_L]
// L = 网络层数
r <- 1
S <- 1
for l in 1 to L:
for i in 1 to l:
S <- S * s[i]
r <- r + (k[l] - 1) * S
return r
4.2. 起始与结束位置计算伪代码
algorithm RecursiveSolution(k, s, p, L):
// k = [k_1, ..., k_L]
// s = [s_1, ..., s_L]
// p = [p_1, ..., p_L]
u <- 0
v <- 0
for l in L downto 1:
u <- -p[l] + u * s[l]
v <- -p[l] + v * s[l] + k[l] - 1
return (u, v)
5. 小结
✅ 总结要点:
| 内容 | 说明 |
|---|---|
| 感受野定义 | 输入图像中影响某个特征输出的区域 |
| 感受野大小 | 反映网络对输入信息的感知范围 |
| 感受野位置 | 可通过递推公式定位其在输入图像中的具体区域 |
| 关键公式 | r₀ = ∑((kₗ-1)·∏sᵢ) + 1 |
| 应用场景 | 图像分割、目标检测、模型调试等 |
⚠️ 常见误区:
- 感受野越大越好 ❌。过大的感受野可能引入冗余信息,影响模型效率。
- 感受野大小等于输入图像尺寸 ❌。实际感受野可能远小于图像尺寸,尤其是在网络较浅时。
通过本文介绍的公式和方法,你可以准确计算任意 CNN 网络的感受野大小和位置,帮助你更好地理解和优化网络结构。