1. 引言
在计算机科学中,混淆(Obfuscation) 是一种隐藏实现细节的技术。它通过让信息的含义变得模糊,从而增加理解的难度。因此,代码混淆(Code Obfuscation) 指的就是任何让代码或其编译后的对象更难阅读和理解的做法。
那么,为什么要这样做呢?
一些人支持“通过隐藏实现来获得安全”的理念,认为增加攻击者理解代码的成本可以起到一定的防御作用。这种观点听起来有一定道理,但在实践中我们发现,它并不能真正阻止攻击。虽然对于技术水平较低的攻击者来说可能是个障碍,但如今攻击者的技能也在不断提升。混淆的主要作用,其实是提高攻击门槛。
当然,从开发和维护的角度来看,代码越清晰越容易理解越好。清晰的代码有助于新成员快速上手,也便于排查错误和添加功能。
因此,在实际使用中,代码混淆通常只在发布生产版本时进行。自动化工具会分析源码或字节码,并对其进行混淆处理。
当然,也有开发人员会手动混淆关键逻辑。例如,把简单的逻辑写得非常复杂,以增加反编译的难度。
2. 代码混淆的使用场景
代码混淆可以应用于源码本身,也可以用于编译后的目标代码(如字节码)。后者更为常见。常见的应用场景包括:
✅ 保护商业机密:关键算法更难被提取和逆向分析
✅ 防止绕过机制:软件更难被分析,攻击者需要更多时间去破解
✅ 优化加载速度:移除调试信息、注释、多余空格等,并缩短变量名。某些工具还能移除未使用的库调用,大幅减少构建包体积。这类工具被称为“最小化工具(Minimizer)”,比如 WebPack,广泛用于 ReactJs 和 VueJs 等前端框架中。混淆后的应用资产更少、体积更小,自然加载更快
❌ 作为安全防护手段,效果有限:已有自动化工具能简化对混淆代码的逆向分析。因此,切勿依赖“混淆”作为唯一的安全措施。
⚠️ 此外,混淆还会带来其他问题,比如缺陷堆栈信息难以分析、构建流程复杂化等。
3. 逆向工程概述
在了解混淆原理之前,我们先来看看它试图对抗的是什么:逆向工程(Reverse Engineering)
逆向工程是指通过分析一个产品来了解其结构和功能。在软件领域,它可以做到从二进制或字节码还原出接近原始的源码,甚至能用于修改和重建系统。
这在分析恶意软件或破解勒索软件的加密机制时非常常见。
逆向工程主要有两种方式:
- 静态分析:将二进制或字节码转换为可读形式,如汇编语言或高级语言(如 Java、C#)
- 动态分析:模拟程序运行,观察其系统调用、输入输出等行为
目前,很多反编译工具(如 Java 反编译器)结合这两种方式,提高逆向效率。
4. 混淆示例
我们来看一个简单的 Java 类,使用以下工具进行演示:
- ProGuard:一个开源的 Java 字节码混淆和优化工具,可集成进构建流程
- Jad:一个开源 Java 反编译器,可将 JVM 字节码还原为 Java 源码
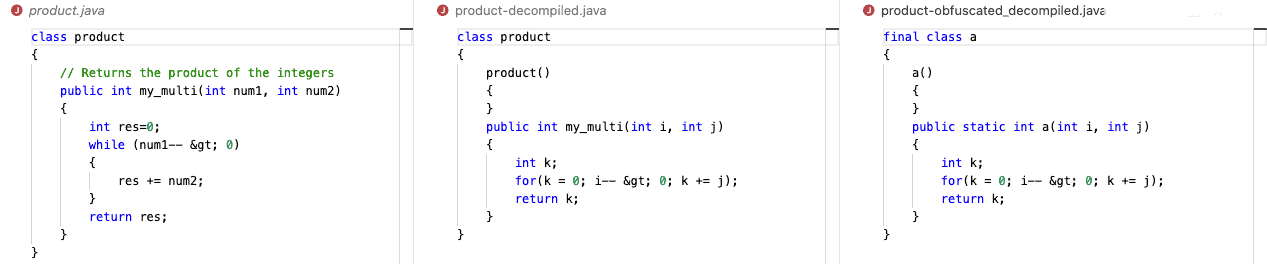
从图中可以看出:
- 反编译后的代码保留了类名,但变量名和注释丢失了
- 原始的
while循环被 Java 编译器优化为更简单的for循环 - 还可以看到一个空的构造方法,这是编译时自动生成的
而在混淆后的版本中:
- 类被标记为
final - 类名被替换为无意义名称(如
a、b等) - 混淆器可以配置为生成更长、更复杂的类名,甚至在不同作用域中复用变量名,利用多态性增加理解难度
尽管代码结构仍可读,但在复杂项目中,要搞清楚每个类、方法和变量的含义,仍然非常耗时。
5. 混淆真的能提升安全性吗?
在基于字节码的平台(如 Java 或 .Net)中,现代反编译工具(如 JD-GUI)可以自动将混淆后的类名和变量名映射回有意义的名称,从而大幅降低混淆带来的保护效果。
也就是说,混淆确实提高了逆向难度,但无法真正阻止逆向行为。因此,它的安全价值非常有限。
有些开发者尝试通过加密整个程序来加强保护。但问题是,程序运行时必须解密,攻击者可以先逆向解密逻辑,或直接在内存中抓取解密后的代码。
6. 总结
本文我们探讨了代码混淆的工作原理,以及它在 Java 中的应用。我们还分析了混淆对逆向工程的影响,并讨论了其安全收益的局限性。
尽管有些人认为代码混淆可以提升安全性,但事实并非如此。无论代码是否混淆,软件工程本身都是耗时的。只要攻击者有足够的动机和资源,混淆并不能真正阻止他们。
当然,对于生成机器码的编译型语言(如 C++)来说,逆向难度要大得多。通常需要使用反汇编工具(如 IDA)进行分析,得到的汇编代码不仅冗长,而且难以理解。一个简单的 C++ 函数,可能就会生成上百页的汇编代码。
✅ 混淆的价值更多体现在优化构建体积、保护商业逻辑不被轻易复制等方面,而不是作为安全防护的核心手段。
⚠️ 所以,请勿将混淆作为唯一的防护手段,应结合其他安全机制(如签名验证、运行时检测、服务端校验等)共同构建安全防线。