1. 引言
在本篇文章中,我们将深入探讨编译型语言和解释型语言之间的核心区别。
虽然现代编程语言种类繁多,但它们的执行方式大致可以归为两类:一种是通过编译器(Compiler)将源代码一次性转换为机器码;另一种是使用解释器(Interpreter)逐行执行源代码。理解它们之间的差异,有助于我们在实际开发中做出更合适的技术选型。
2. 为什么需要编译器和解释器?
计算机只能理解和执行二进制机器码(0 和 1 的组合),而程序员通常使用的是更接近人类语言的高级语言(如 Java、C、Python 等)来编写程序。
为了能让计算机运行这些高级语言编写的程序,我们必须将源代码转换成计算机可以理解的形式。这个转换过程,就是由编译器或解释器完成的。
- 编译型语言:源代码一次性被翻译成可执行的二进制文件,例如 C、C++。
- 解释型语言:源代码在运行时被逐行解析并执行,例如 Python、JavaScript。
3. 编译器的工作原理
编译器会一次性将整个程序转换为目标平台的二进制可执行文件,这个过程通常包括词法分析、语法分析、语义分析、代码生成等多个阶段。
✅ 优点:
- 编译后生成的二进制文件可以直接在目标平台上运行,效率高。
- 编译阶段可以检测出部分语法错误和类型错误,提前暴露问题。
❌ 缺点:
- 生成的二进制依赖于特定平台,不具备跨平台可移植性。
- 每次修改源码后都需要重新编译。
⚠️ 编译过程只在开发阶段进行一次,之后可以直接运行生成的可执行文件,无需再次编译。
4. 解释器的工作原理
解释器不生成可执行文件,而是逐行读取源代码并立即执行。每条指令在运行前都会被翻译成机器码并立即执行。
✅ 优点:
- 开发调试方便,修改代码后可立即运行查看结果。
- 更容易实现跨平台运行(只要目标平台有对应的解释器)。
❌ 缺点:
- 运行效率通常低于编译后的程序。
- 所有错误都在运行时才被发现,不利于早期排查。
⚠️ 解释器必须在程序运行时始终存在于内存中,而编译器只需在编译阶段使用一次。
5. 示例对比:编译 vs. 解释
我们来看一段简单的伪代码示例:
a := 1;
b := 2;
c := a + b;
print(c);
✅ 编译过程示意
编译器会一次性将上述代码转换为机器码:
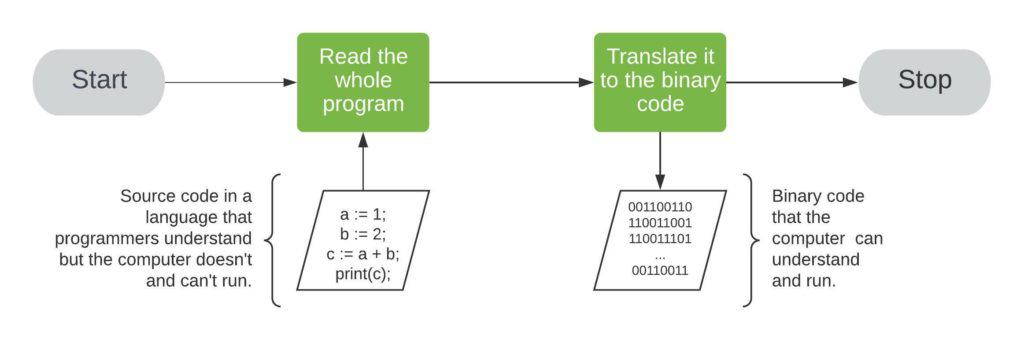
这些二进制指令会告诉计算机如何操作 CPU 寄存器、如何将数据写入内存等。编译完成后,生成的可执行文件可以在目标平台上直接运行。
✅ 解释过程示意
解释器则会逐条读取并执行:
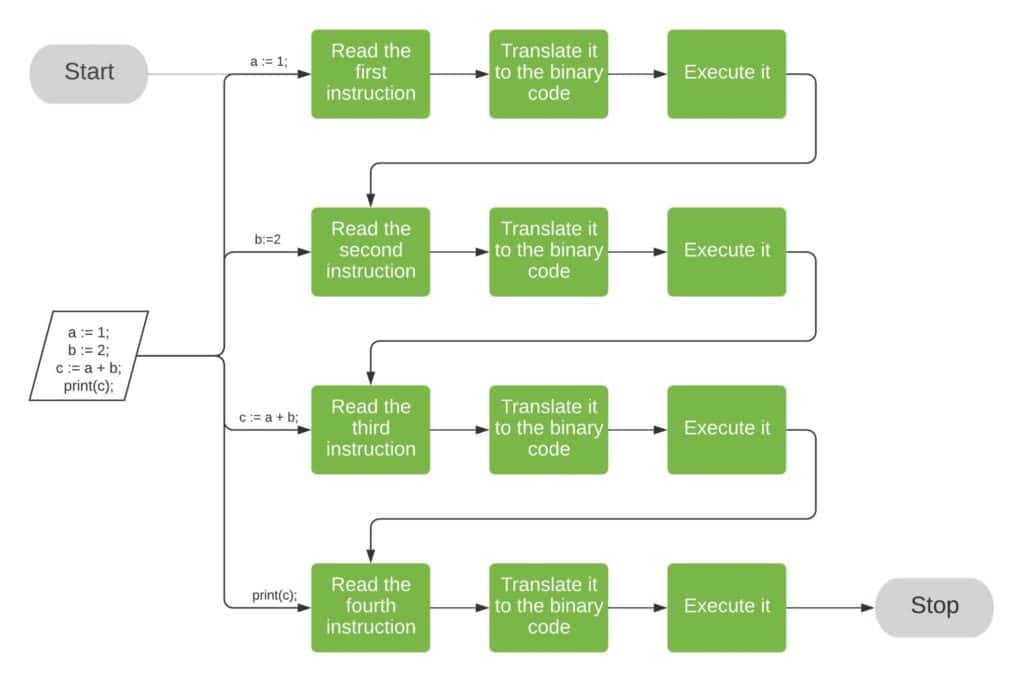
每条语句都会被即时翻译并执行,这意味着翻译和执行是交织进行的。
6. 编译器与解释器的对比总结
| 特性 | 编译器 | 解释器 |
|---|---|---|
| 处理方式 | 一次性处理整个程序 | 逐行处理程序指令 |
| 输出结果 | 生成可执行的二进制文件 | 不生成可执行文件 |
| 使用时机 | 编译阶段使用一次 | 每次运行程序都需要 |
| 错误检测 | 编译阶段即可发现语法和类型错误 | 所有错误在运行时才发现 |
| 内存占用 | 运行时不需编译器存在 | 运行时必须在内存中 |
| 执行效率 | 通常更快 | 通常更慢 |
⚠️ 虽然我们通常把某些语言归类为“编译型”或“解释型”,但现代语言往往结合了两者的特点。例如:
- Java:先编译成字节码(bytecode),再由 JVM 解释执行。
- Python:也有如 Nuitka 这样的编译器,可以将 Python 编译成 C 代码。
- **C/C++**:也有解释器实现,如 Ch,可以用于脚本编程。
7. 结语
本文我们深入分析了编译器和解释器的工作机制及其主要区别。虽然它们的目标都是将高级语言转换为计算机可执行的代码,但在实现方式、性能表现、错误检测时机等方面存在显著差异。
在实际开发中,选择哪种方式取决于项目需求、性能要求和开发效率。理解这些底层机制,有助于我们更好地使用编程语言,避免一些常见的“踩坑”场景,比如:
- 误以为 Python 一定慢(其实可以通过 JIT、编译等方式优化)。
- 认为编译型语言就一定快(忽略了运行时环境的影响)。
掌握这些底层知识,是成长为高级开发者的必经之路 ✅