1. Overview
In computer science, we might encounter the lost update problem in a system with high concurrency. It occurs when multiple operations attempt to modify the same resource simultaneously without proper concurrency control, leading to unhandled exceptions or data inconsistencies.
In this tutorial, we’ll look at the lost update problem, its causes, and its main approaches.
2. What Is the Lost Update Problem
The lost update problem is a concurrency issue that arises when multiple processes or threads concurrently access and modify the same data, resulting in some updates unintentionally overwriting others. This problem is significant in any system where concurrent modifications are possible, such as collaborative applications, financial systems, or any scenario involving shared resources.
We can give an example of a database scenario in which two or more transactions concurrently access and modify the same data:
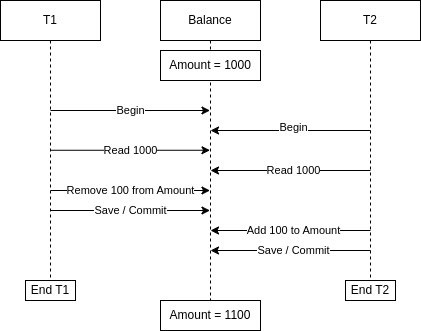
We have two concurrent transactions (T1 and T2), adding and subtracting, for example, from a stock or bank balance. They both read the same initial balance. However, T1 removes some amount from the balance while T2 adds. Eventually, one of the two transactions will happen at the end, overwriting the other transaction’s change. While the final amount should acknowledge both updates, one lost update will occur if no concurrency strategies exist.
3. What Causes the Lost Update Problem
This issue usually happens in systems with high concurrency where multiple threads or processes access resources in a single or distributed workload.
3.1. Multi-Threading and Multi-Processing
In a multi-processing or multi-threading system, lost updates can occur when accessing or modifying shared resources. These resources might be files, databases, or shared data types that threads or processes can access concurrently.
Therefore, issues usually happen at a low software level:
- Race Conditions: Threads or processes compete for access to shared resources without coordination, leading to inconsistent data states
- Lack of Synchronization: Concurrent entities may overwrite each other’s changes without synchronization mechanisms
- Atomicity Violations: Operations that appear atomic at a high level may not be atomic at the CPU instruction level, making intermediate states visible to other threads
For multi-processing, we might face issues with inter-process communication and shared memory access.
For multi-threading, the lost update is a recurrent issue in database concurrency or any programming language that supports multi-threading itself.
3.2. Distributed Systems
In distributed systems, the lost update problem arises when multiple nodes or services in a network attempt to update the same piece of data concurrently. The lack of a centralized control mechanism and inherent network delays can result in conflicting updates.
Therefore, issues are more about how the system connects and reacts in different nodes:
- Network Latency: Delays in communication between nodes can cause inconsistent states as updates are not synchronized
- Lack of Coordinated Locks: Multiple nodes can modify shared data simultaneously without global locks, resulting in overwrites
4. Isolation Level
To solve the lost update problem, we must understand how the isolation levels work. We can apply isolation levels to any system where multiple processes or threads access shared resources. However, we often refer to them in a database context and MVCC models where we can have different versions or read states of records.
Isolation levels refer to the degree of visibility different processes or transactions have over shared resources during concurrent execution. These levels help manage how operations interact with each other to prevent conflicts or inconsistencies.
Let’s illustrate key concepts of reading concurrent data so we can understand the different types of isolation:
- Dirty read when we read data modified by others but not yet saved
- Non-repeatable read when we read the same data multiple times and get different results because it has been modified and saved between reads
- Phantom read when, for example, a database transaction executes a query that returns a set of rows. Still, subsequent execution of the same query within the transaction returns a different set of rows because another transaction has inserted, deleted, or modified rows
Given the states of the data we might find during concurrency, let’s examine the most common isolation levels.
4.1. Read Uncommitted
It allows processes or transactions to read data modified by others that have not yet been committed. For example, one transaction can see uncommitted or partial changes made by another, leading to potential inconsistencies. We have the highest concurrency level with the read uncommitted level, but there is no guarantee of an execution order.
The read uncommitted level can be beneficial in specific scenarios where performance is a priority and data accuracy is less critical. However, we want to avoid it for a lost update problem.
4.2. Read Committed
It allows processes or transactions only to read data others have committed, ensuring they do not see intermediate states. In this case, only committed data is read, but the order of reads and writes is not entirely controlled. With a read committed level, we have moderate concurrency, and the data might change between reads, leading to non-repeatable reads.
A read committed level is typical in systems or any environment where real-time data visibility is more important than ensuring the data remains unchanged throughout a transaction. It is the default isolation level, for example, in many databases. However, it doesn’t guarantee handling lost updates in a high-concurrency scenario.
4.3. Repeatable Read
This isolation level ensures that if we read a piece of data, we will see the same data if we reread it within the same transaction or process. With the repeatable read level, we still have a moderate concurrency. However, a lock applies to the specific data we want to modify to allow repeatable reads.
Therefore, we might be able to verify if a stock or account balance gets updated during a process because we still read the initial value. However, phantom reads can still occur.
A repeatable read level is ideal for scenarios where data consistency is relevant, but full serialization (which would prevent any concurrent changes) is too restrictive.
4.4. Serializable
Serializable is the highest isolation level, ensuring complete isolation between transactions or processes. It achieves this by treating them as if they are executed serially, one after another, rather than concurrently.
This level prevents dirty, non-repeatable, and phantom reads. However, it can significantly impact performance. By locking whole resources, such as database tables, we get a low concurrency level with the serializable level. We also achieve a sequential order of transaction execution, preventing all types of anomalies.
A serializable level is most appropriate in scenarios where we need the highest data consistency and integrity and the risk of concurrency leading to errors is too significant. For instance, preventing issues like overselling is crucial in a stock trading system.
5. Locking
Locking is a technique used in databases and concurrent systems to enforce isolation. Therefore, the chosen isolation level determines the type and extent of locking.
There are two types of locks:
- Read Lock (Shared Lock): Multiple transactions or processes can read the data but not modify it. Concurrency can acquire read locks but not write locks until all read locks are released
- Write Lock (Exclusive Lock): A transaction or process can read and modify the data. While a write lock is happening, no concurrency can acquire any locks (read or write) on the same data
5.1. Optimistic Locking
Optimistic locking assumes that conflicts are rare and does not lock data during a read. Instead, it verifies if conflicts have occurred before committing changes.
The following steps apply:
- Read Data: Retrieve the data along with a version number or timestamp
- Modify Data: Perform updates based on the read data
- Validate and Commit: Check if another concurrent transaction or process has changed the data before committing. If so, handle the conflict (e.g., retry). If not, commit the changes
Optimistic locking reduces lock contention and allows higher concurrency. However, it requires handling conflicts, which can add complexity.
For example, we might look at optimistic locking in Java using JPA.
5.2. Pessimistic Locking
Pessimistic locking assumes that conflicts are likely and locks data at the beginning of a transaction to prevent other transactions from accessing it.
The following steps apply:
- Acquire Lock: Lock the data when starting a transaction or process
- Access and Modify: Perform operations on the locked data
- Release Lock: Release the lock after completing
Pessimistic locking prevents conflicts by ensuring exclusive access to the data. However, it can lead to decreased concurrency and performance due to lock contention and the potential for deadlocks.
For example, we might look at how to use locks in Java.
6. Using Streams and Aggregations
Using streams and aggregations can be effective strategies for addressing the lost update problem.
Streams provide a way to handle data sequentially and efficiently by processing it in a controlled sequence. By combining them with aggregations, we summarize or combine multiple data points to produce a single result and ensure that concurrent updates are correctly incorporated into the final result.
For example, we can look at frameworks like Apache Kafka to stream data in time windows or partitions and aggregate updates to ensure that all relevant changes are processed together. Therefore, the stream will process our data similarly to a queue while applying complex logic such as validations, transformations, and aggregation.
Let’s look at how a transaction processing would be:
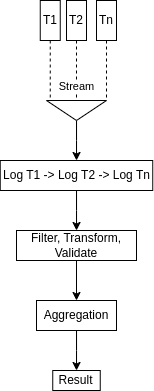
A log trace shows how a stream creates a data sequence in real-time as it flows through the system. Logs, unlike queues, persist and can be reused. We can filter, transform, and aggregate our data depending on the business logic.
Frameworks such as Kafka offer a scalable method for maintaining data consistency and integrity, even in the face of concurrent updates, by combining streaming and aggregation. Thus, they effectively solve the lost update problem.
7. Distributed Systems
A distributed system is a collection of independent nodes communicating over a network, sharing resources, and coordinating actions to perform tasks. Although it provides higher availability and scalability, solving the lost update problem looks more complex due to even higher concurrency. We might also have network latency and potential system partitioning challenges.
7.1. Extend Rules of Single Node Applications
However, most practices we have seen earlier can apply to a distributed system. For example, streams and partitions can scale and adapt to many instances while maintaining the same data processing order.
Like the approach in a single node instance, distributed systems can track changes to data using version numbers and optimistic concurrency control (OCC). When a process attempts to update a piece of data, it checks the version against the current version in the system. Likewise, pessimistic locking and atomic operations ensure, for example, that only one user can modify a cache entry at a time.
7.2. Strong or Eventual Consistency
Whether we work with strong or eventual consistency in our system, we can extend the concurrency features that frameworks or databases provide from a single node to a larger system.
For example, with NoSql databases, we might get temporary data inconsistencies. However, that shouldn’t refer to the order in which we acquire the sequence of our events. For example, we can look at how software, such as databases or event-driven architectures, implements CQRS and event sourcing to distribute and synchronize data over multiple nodes.
Still, with databases, quorum-based consistency ensures that updates are propagated to most nodes before being considered successful.
8. Best Practises
There are possible ways to limit or avoid the lost update problem:
- Rely on programming languages or specific software, like databases, that allow concurrency configurations to help us with the lost update problem. Then, we should be able to choose the most appropriate isolation level or locking mechanism for our use case
- Always choose or design data structures that can handle concurrent updates, such as maps, sets, or counters
- For a high-concurrency system, we might want to implement some middleware logic to aggregate data in specific time frames so we can later process using batch or stream processing
- Design a system with strong consistency and proper transaction use, but avoid extensive locking
- Do not delegate concurrency issues completely to low-level software. Sometimes, we might want to design our logic, for example, to prompt a user to choose how to merge or solve conflicts by providing a user interface interaction
As we have seen, we can handle the lost update problem in many ways. First, we should not assume the error of building full custom strategies. Then, we should master and understand tools and basic concepts, keeping user interaction in mind, so we do not rely entirely on intricate system settings.
9. Conclusion
In this tutorial, we examined the lost update problem and its causes. We started by analyzing the isolation levels and locking mechanisms, which provided a solid foundation for understanding this problem. We also saw how streams and aggregations can offer a clean solution. Finally, we saw how, in the distributed system, we should still be able to apply the solutions of a single-node application.