1. 概述
在本篇教程中,我们将介绍对比学习(Contrastive Learning)的基本概念和核心思想。我们会从直觉出发,解释为什么对比学习能有效,接着介绍相关术语、常见的训练目标函数,以及对比学习在监督和无监督任务中的应用。
2. 直觉理解
我们先从一个孩子玩的“找相同”游戏入手:

这个游戏的目标是:在左侧的图片中识别出一个动物,然后在右侧的四张图中找出与之相同的动物。比如,孩子需要在四张图中找到狗。
为什么这种通过对比来学习的方式更有效?
✅ 因为对于没有先验知识的孩子来说,通过比较相似和不相似的样本更容易掌握新概念。一开始他可能认不出狗,但通过观察多个狗的图像,他学会了狗的共性,比如鼻子的形状、站姿等。
3. 术语解释
对比学习的核心思想是:通过对比相似和不相似的样本,学习低维特征表示。具体来说,就是让相似样本在特征空间中尽可能靠近,不相似样本尽可能远离。
举个例子,我们有三张图:
 :狗
:狗  :狗
:狗  :猫
:猫
目标是让  与  接近,与  远离。
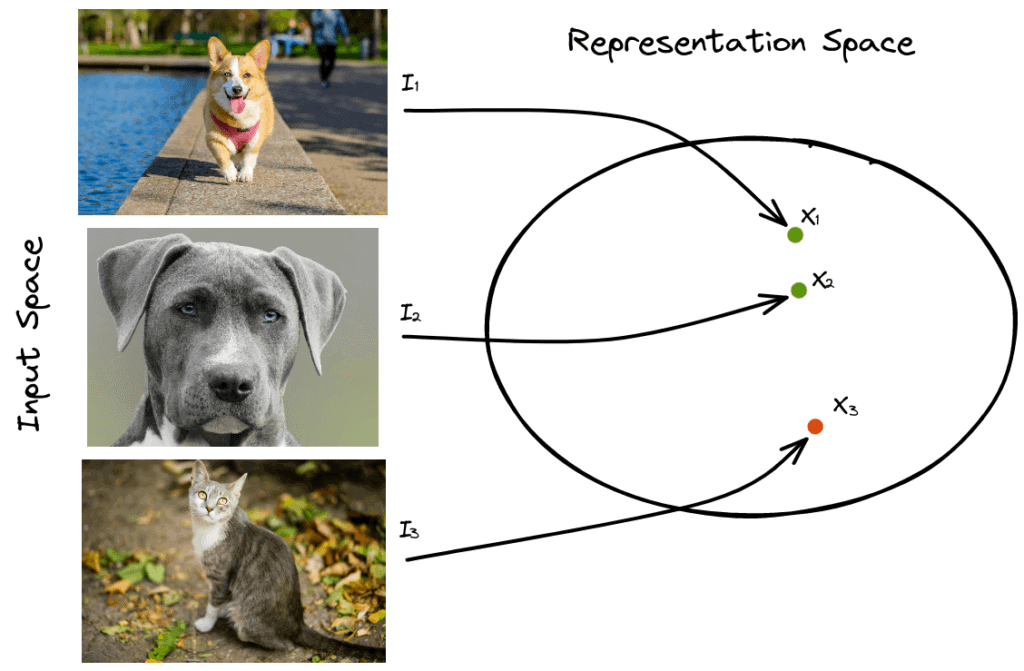
在对比学习中:
- ![I_1] 是 anchor(锚点)
- ![I_2] 是 positive(正样本)
- ![I_3] 是 negative(负样本)
4. 训练目标
训练目标是对比学习的核心,决定了模型如何学习特征表示。我们介绍两个最常用的对比损失函数。
4.1. Contrastive Loss
Contrastive Loss 是最早用于对比学习的损失函数之一。它接受一对样本作为输入,根据它们是否相似来拉近或推开它们的特征距离。
公式如下:
$$ \mathbf{L = (1-Y) \cdot ||x_i - x_j||^2 + Y \cdot \max(0, m - ||x_i - x_j||^2)} $$
其中:
- $ Y=0 $:表示这对样本相似
- $ Y=1 $:表示不相似
- $ m $:是一个超参数,表示不相似样本之间的最小距离
两种情况:
- 如果相似(Y=0):最小化欧氏距离
- 如果不相似(Y=1):最大化欧氏距离,但不超过 m
4.2. Triplet Loss
Triplet Loss 是 Contrastive Loss 的改进版。它使用三元组(anchor、positive、negative)进行训练,目标是使 anchor 与 positive 的距离小于 anchor 与 negative 的距离。
公式如下:
$$ \mathbf{L = \max(0, ||x - x^+||^2 - ||x - x^-||^2 + m)} $$
✅ 优势:使用三元组可以同时利用正负样本进行更新,收敛更快。
5. 对比学习的类型
对比学习可以用于监督和无监督任务。
5.1. 监督学习
在监督学习中,每张样本都有标签。我们可以根据标签生成正负样本对或三元组。
问题:
- 生成所有可能的对/三元组计算量大
- 很多负样本已经满足对比目标,训练效率低
解决办法:
- 生成 hard pairs/triplets(即损失值高的样本)
- 使用快速搜索算法在特征空间中挖掘 hard 负样本
例如在 NLP 中,可以通过在句子中加入否定词来构造 hard 负样本。
5.2. 无监督学习
在没有标签的情况下,通常使用自监督学习(Self-Supervised Learning)来生成伪标签。
一个经典的框架是 SimCLR。它的核心思想是:对同一张图像进行随机变换(如裁剪、翻转、颜色抖动),生成正样本对,因为这些变换不会改变图像语义。
示意图如下:

6. 总结
在本篇教程中,我们介绍了对比学习的基本概念、术语、训练目标函数(Contrastive Loss、Triplet Loss)以及其在监督和无监督场景下的应用。
✅ 对比学习通过对比相似与不相似样本,能有效学习高质量的特征表示。
✅ Triplet Loss 在训练效率和效果上优于 Contrastive Loss。
✅ SimCLR 等自监督方法为无监督学习提供了强大工具。
⚠️ 在监督任务中要注意 hard negative mining,提升训练效率。