1. 概述
本文将介绍机器学习中的“维度灾难(Curse of Dimensionality)”现象。我们会先解释这个概念,然后讨论它在实际应用中带来的挑战,并提供一些应对策略。
2. 什么是维度灾难?
维度灾难是指在高维空间中进行数据分析时出现的一系列问题。这个术语最早由数学家 Richard E. Bellman 在1957年提出,用来描述在欧几里得空间中增加维度时,空间体积迅速膨胀的现象。
在机器学习中,数据的维度通常对应于特征的数量。当特征数量达到上百甚至更多时,我们就称其为高维数据。维度增加后,空间的体积呈指数级增长,而数据点却变得稀疏,导致模型训练变得更加困难。
✅ 关键点:
- 数据稀疏:高维空间中,样本点之间距离变大,难以形成有效的聚类或分类边界。
- 过拟合风险:特征过多可能导致模型过于复杂,从而在训练集上表现很好但在测试集上表现差。
- 计算成本:训练时间变长,模型复杂度增加。
这些问题统称为“维度灾难”。
3. Hughes 现象
维度灾难与 Hughes 现象密切相关。该现象指出:在训练样本数量固定的情况下,随着特征数量的增加,分类器的性能会先提升,达到一个峰值后开始下降。
换句话说,并不是特征越多越好!
如下图所示,随着特征数量增加,分类器性能先上升后下降:
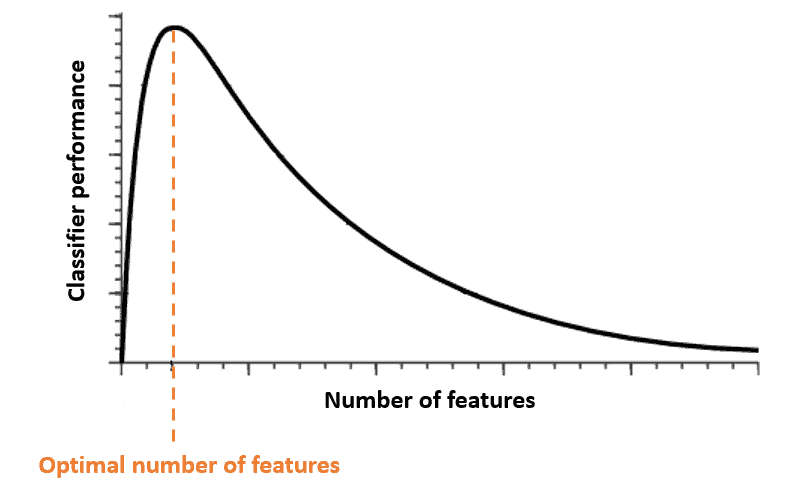
4. 如何应对维度灾难?
4.1. 特征选择技术
特征选择是从原始特征中挑选出最有代表性和区分能力的特征,去掉冗余或无关的特征。常用方法包括:
✅ 常用方法:
- 低方差过滤(Low Variance Filter):删除在训练集中方差较低的特征,因为它们变化不大,区分能力弱。
- 高相关性过滤(High Correlation Filter):计算特征之间的相关性,若两个特征高度相关,可删除其中一个。
- 特征排序(Feature Ranking):使用如决策树等模型对特征进行评分,保留排名靠前的特征。
4.2. 特征提取技术
特征提取是将原始高维数据映射到低维空间,同时尽可能保留原始信息。这些方法会生成新的特征,而不是直接选择原始特征。
✅ 常见方法:
| 方法 | 描述 |
|---|---|
| PCA(主成分分析) | 最常用的降维方法。通过线性变换找到方差最大的方向,将数据投影到低维空间,保留最多信息。 |
| LDA(线性判别分析) | 与 PCA 类似,但目标是最大化类间差异、最小化类内差异。需要有标签数据。 |
⚠️ 注意:
- PCA 是无监督方法,适用于无标签数据。
- LDA 是有监督方法,适合分类任务。
5. 总结
维度灾难是机器学习中一个常见但容易被忽视的问题。高维数据会带来数据稀疏、模型过拟合和计算开销大等挑战。面对这些问题,我们可以通过特征选择和特征提取技术来降低维度,提升模型性能。
✅ 应对维度灾难的关键策略:
- 使用特征选择方法剔除冗余特征
- 利用特征提取技术降维,保留关键信息
- 控制特征数量,避免盲目增加维度
通过合理选择和处理特征,我们可以有效缓解维度灾难带来的负面影响,从而构建更鲁棒、高效的机器学习模型。