1. Overview
In this tutorial, we’ll discuss two methods for splitting databases into parts to manage them efficiently: sharding and partitioning. Additionally, we’ll explore the basic concept of each method, along with an example. Furthermore, we’ll also list some advantages and disadvantages of each method.
Finally, we’ll highlight the core differences between them.
2. Database Sharding
2.1. Introduction
Database sharding is a technique for horizontally partitioning a large database into smaller and more manageable subsets. Additionally, each subset is called a shard. Furthermore, we can distribute them across multiple servers or nodes in a cluster. We can think of a shard as a little chunk of data. Moreover, the shards together make up the complete data set.
We often utilize sharding in large-scale distributed systems where traditional scaling methods, such as vertical scaling, may not be sufficient to handle the increasing data volume and traffic. Hence, by distributing the data across multiple servers, sharding can improve the performance, scalability, and availability of the database.
We can use different approaches to implement sharding. Furthermore, some popular strategies utilized in sharding are range-based sharding, hash-based sharding, and composite sharding.
In range-based sharding, we divide the data based on a range of values, such as a date range or alphabetical order. Furthermore, hash-based sharding involves dividing the data based on a hash function that maps the data to specific shards. Finally, composite sharding involves combining range-based and hash-based sharding techniques.
Let’s take a look at an example of hash-based sharding:
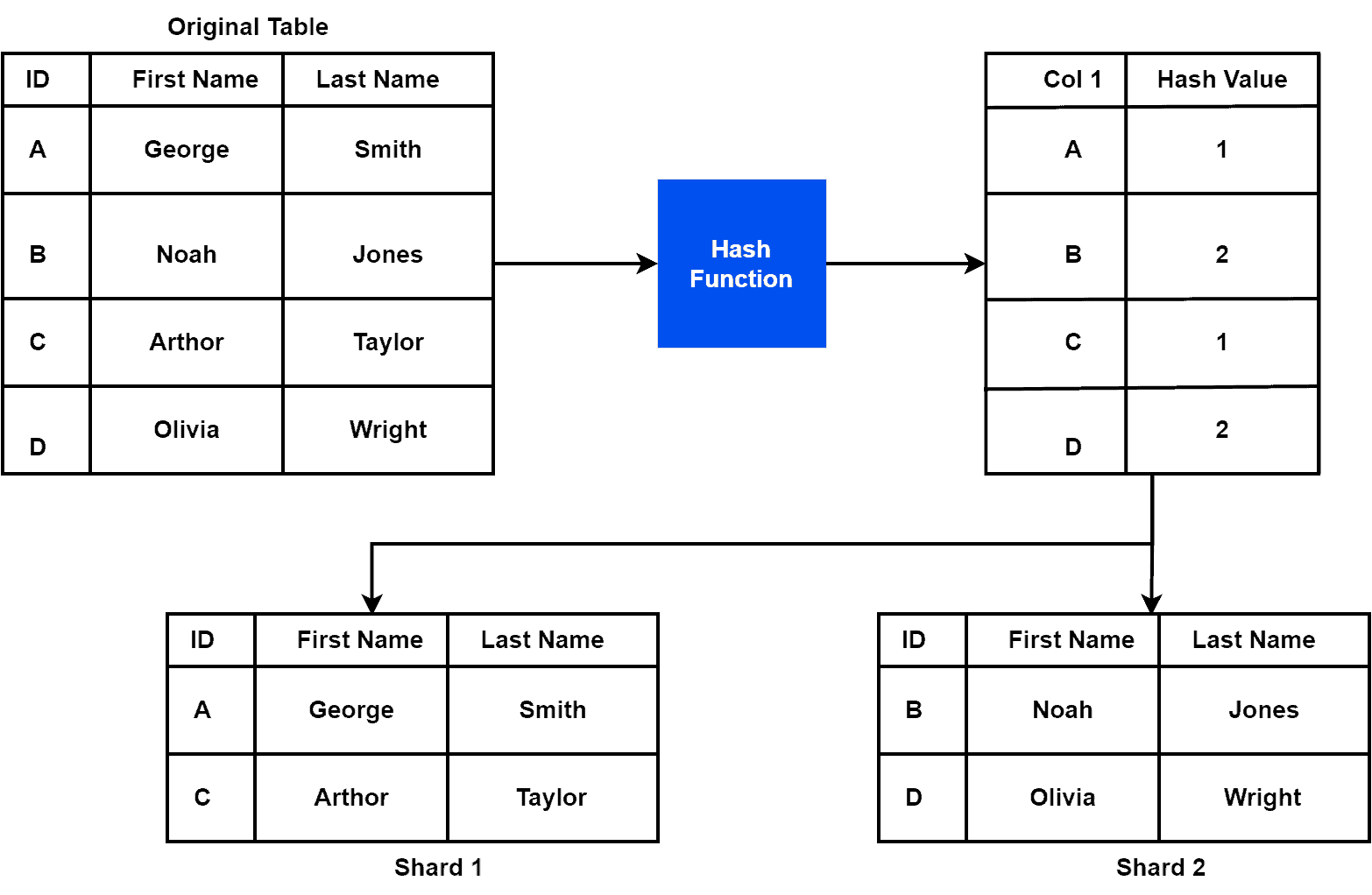
2.2. Advantages and Disadvantages
Let’s see some advantages and disadvantages of sharding:
Advantages
Disadvantages
By partitioning the data into smaller subsets and distributing it across multiple servers, sharding can improve the scalability of the database
Can introduce additional complexity to the database architecture
By spreading the workload among numerous servers, performance can be improved
Maintaining data consistency across the shards can be challenging
Reduces the risk of a single point of failure
Less flexible compared to other scaling methods
Cost-effective than traditional scaling methods
Challenging to manage the distribution and synchronization of the data across the shards
2.3. Applications
Database sharding is commonly used in large-scale, high-traffic web applications and distributed systems. Additionally, we use sharding when traditional scaling methods are insufficient to handle large databases. Let’s discuss some common applications of database sharding.
E-commerce websites use the sharding technique. Specifically, it distributes product catalogs, orders, and customer information across multiple servers. Hence, it helps in improving the performance and availability of e-commerce platforms.
Furthermore, social media platforms with millions of users generate massive amounts of data that need to be processed and stored. Therefore, we can use sharding to partition the data across multiple servers to improve performance and scalability.
Finally, we can use sharding in online gaming. Online games with large player bases generate significant data that needs to be stored and processed in real-time. Therefore, it can be used to distribute player profiles, game states, and scores across multiple servers to improve performance and availability.
3. Database Partitioning
3.1. Introduction
Partitioning is a method for breaking down a massive database into small subsets. Furthermore, each subset is known as a partition or segment. Additionally, each partition stores a subset of the data, and together they form the entire dataset.
Partitioning can improve the performance, scalability, and availability of the database by distributing the data across multiple servers or nodes. In addition, it may decrease the amount of data that must be processed to answer a certain query. Hence, it improves query response time.
Now, let’s discuss some techniques we can use to implement partitioning. There’re several different techniques for partitioning a database, including range partitioning, list partitioning, and composite partitioning.
Furthermore, range partitioning is the process of dividing data into partitions based on a specific range of values for a designated partitioning key. On the other hand, list partitioning is the method of splitting data into partitions based on a specific list of values for a designated partitioning key. Finally, composite partitioning divides data into partitions using a combination of range and list partitioning strategies.
Let’s take a look at an example of range-based database partitioning:
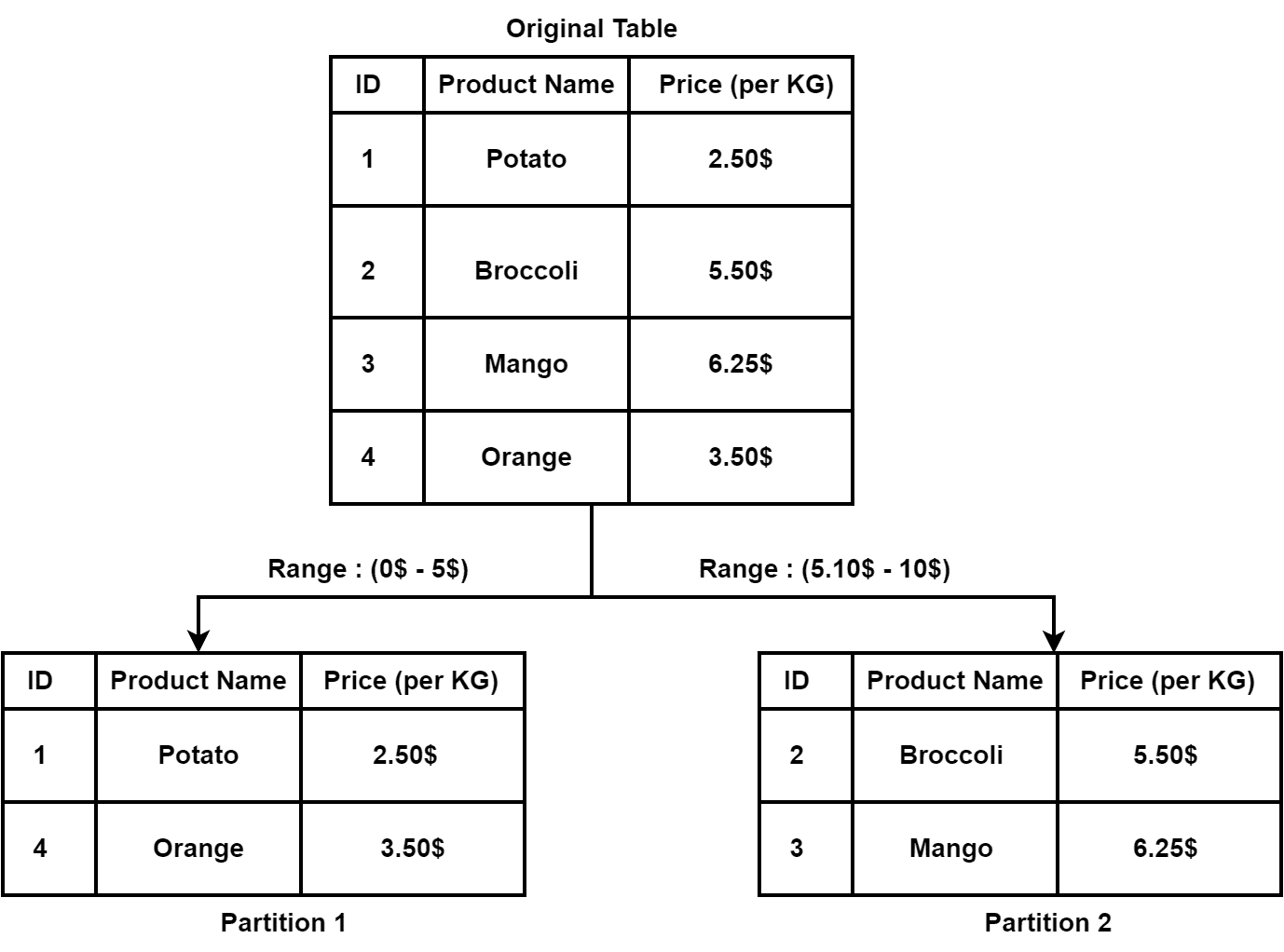
3.2. Advantages and Disadvantages
Let’s see some advantages and disadvantages of partitioning:
Advantages
Disadvantages
Can help queries run faster by limiting the amount of data searched in response to a certain query
Can increase the complexity of the database design and management, especially as the number of partitions grows
Improves the scalability of a database by distributing the data across multiple servers
Can result in data skew, where certain partitions contain a disproportionate amount of data compared to others
Improves the availability of a database by allowing individual partitions to be backed up or restored independently
Increases the overhead associated with managing the database
A cost-effective way to improve the performance and scalability of a database
May not provide significant performance or scalability benefits for small databases
3.3. Applications
Database partitioning is widely used in various applications, especially in large-scale data-intensive applications. Let’s discuss some of the major applications of the partitioning method.
We can use the partitioning technique in several financial services. Furthermore, financial services applications often handle large amounts of transactional data, which can be partitioned based on transaction attributes, such as date range, account type, or transaction amount.
IoT devices and applications utilize the partitioning technique. Additionally, IoT applications generate large amounts of sensor data, which can be partitioned based on sensor type, location, or time range.
Finally, healthcare applications often store large amounts of patient data. In order to analyze the data, we can partition based on patient attributes, such as geographic location, medical history, or treatment plan.
4. Differences
Now let’s discuss the core differences between sharding and partitioning:
Database Sharding
Database Partitioning
Typically used to distribute data across multiple servers or clusters
Typically used to divide data within a single database instance
Each shard may contain a duplicate copy of some data to ensure high availability
There’s no data redundancy within a partition
Requires more administrative overhead
Requires less administrative overhead
Offers less flexibility than database partitioning
Offers greater flexibility than database sharding
5. Conclusion
In this tutorial, we discussed two methods for splitting databases into parts to manage them efficiently: sharding and partitioning. Additionally, we explored the basic concept of each method, along with an example. Furthermore, we also listed some advantages and disadvantages of each method. Finally, we highlighted the core differences between them.