1. 引言
“猜猜我是谁”(Guess Who?)是朋友聚会中最简单也最受欢迎的互动游戏之一。每位玩家在额头上贴一张名人卡片,但自己看不到,只能通过提问来猜测自己的身份。
这些问题只能用“是”或“否”来回答。有些变种规则还会包括物品或引入计分系统。
现在我们也可以通过手机 App 或网站来玩这个游戏。
在本教程中,我们将重点讲解“20个问题”(20 Questions)这个游戏的 AI 实现原理。它通过算法和学习策略来猜测玩家心中的对象(人物或物品)。
2. 历史背景
像许多传统游戏一样,很难确定这个游戏的确切起源时间。但我们知道它在19世纪的美国新英格兰地区开始流行,是一种口头游戏。
最初,游戏的开场问题是:“它是动物、植物还是矿物?”这个游戏之所以流行,是因为它规则简单、无需练习,任何人都可以参与,且不同水平的人都能玩得开心。
2.1. 竞猜节目
“20个问题”曾在加拿大、匈牙利、挪威等国家的电视和广播节目中广受欢迎。
在广播中,听众会提交一些名字,由主持人来猜。
值得一提的是,随着主持人的经验积累,他们能在更少的问题内缩小可能的答案范围。这种人类行为后来被程序员尝试用算法来模拟。
2.2. 人工智能方法
1988年,Robin Burgener 开始尝试用计算机实现“20个问题”游戏。
在这个版本中,计算机通过最多20个“是/否”问题来猜测玩家心中所想的对象。如果第一次猜测错误,它还可以再提出最多5个问题。
作者为其策略申请了专利,其核心是一个对象-问题矩阵,通过权重连接输入(问题答案)和输出(目标对象)。虽然还有第二种模式,但为了简化说明,我们只讨论第一种方法:
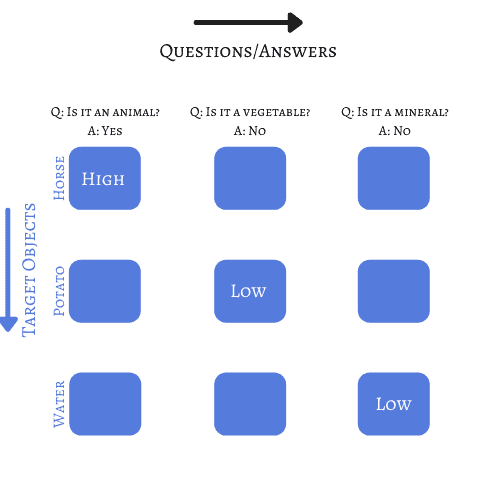
在后续步骤中,对象会根据每个答案的权重进行排序。
答案还可以包括“通常”、“有时”、“可能”等选项,每种回答都可以赋予相应的权重。
我们可以在这里玩这个游戏的在线版本。它每次游戏后都会学习,因此即使玩家答错了一个问题,也能正确猜出答案。
3. 理论基础
在深入理解软件如何正确猜测答案之前,我们需要了解一个常用于解决此类问题的策略:决策树(Decision Trees)。
根据学习参数的方式,方法可以分为参数方法和非参数方法。
- 参数方法:模型在整个输入空间中学习参数,基于全部训练数据构建模型。
- 非参数方法:将输入空间划分为多个区域,每个区域内使用局部模型,仅基于该区域内的训练数据。
3.1. 决策树
决策树是一种非参数的分层模型,采用“分而治之”(divide-and-conquer)的策略。它可以用于回归和分类任务。
在监督学习中,我们通过递归划分区域来构建决策树。模型中包含两种元素:决策节点(decision nodes)和叶节点(terminal leaves)。
每个决策节点包含一个函数  ,其输出决定了分支方向。我们从根节点开始,依次在决策节点计算
,其输出决定了分支方向。我们从根节点开始,依次在决策节点计算  ,决定走向哪个分支。
,决定走向哪个分支。
我们递归地执行这个过程,直到到达叶节点。一旦到达叶节点,该节点的值就是最终输出。
假设我们有一个包含圆形和方形的虚拟数据集,其对应的决策树如下图所示,椭圆表示决策节点,矩形表示叶节点:
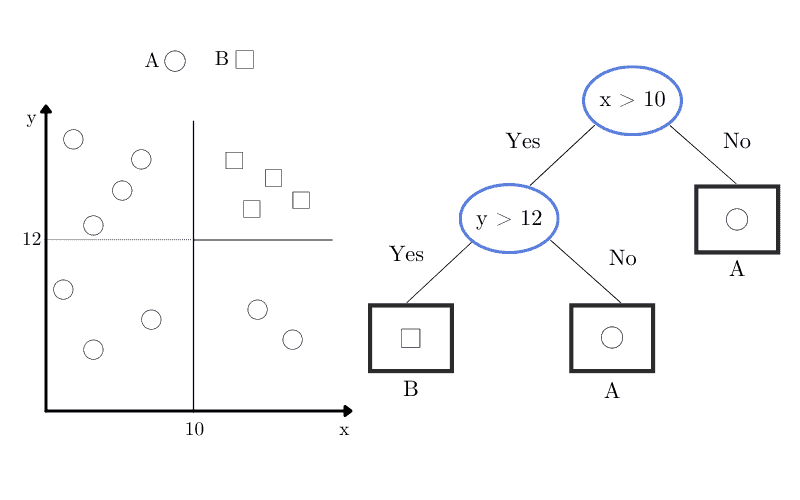
另一个支持我们将决策树归为非参数模型的理由是:我们不预先设定树的结构或类别分布,这些内容是在训练阶段根据问题复杂度动态决定的。
3.2. 分类树
如果我们的决策树有多个类别标签,我们称之为分类树。
我们可以计算划分的不纯度(impurity)。如果某个划分的所有分支都只包含一个类别,那么我们认为这个划分是纯净的。
假设我们有一个节点  ,那么
,那么  表示到达该节点的样本数量,
表示到达该节点的样本数量, 是属于类别
是属于类别  的样本数。我们可以计算该节点中 的概率:
的样本数。我们可以计算该节点中 的概率:
(1) 
如果在节点 中,所有  的
的  都为 0 或 1,则我们认为该节点是纯净的。也就是说,所有样本都属于 类别,或者都不属于。
都为 0 或 1,则我们认为该节点是纯净的。也就是说,所有样本都属于 类别,或者都不属于。
此时我们应停止划分,因为已经到达叶节点。所有 类别中 为 1 的样本应标记为 。
但如果节点不是纯净的,我们如何衡量其不纯度呢?这就需要引入信息论中的“熵”(Entropy)概念。
3.3. 熵
如 Quinlan 在 1986 年定义的,熵是衡量编码一个实例类别所需的比特数。
我们可以用以下公式计算熵:
(2) 
举个例子,假设我们只有两个类别:
- 如果
 且
且  ,那么熵为 0,因为所有样本都属于类别 1。
,那么熵为 0,因为所有样本都属于类别 1。 - 如果
 ,那么熵为 1,因为两个类别出现的可能性相同,需要 1 bit 来编码。
,那么熵为 1,因为两个类别出现的可能性相同,需要 1 bit 来编码。
我们也可以推广到多个类别的情况,当所有类别出现概率相等时,即  ,熵为:
,熵为:
(3) 
这个公式可以用来计算编码所有类别所需的比特数。
4. 示例
虽然上述方法可以实现高准确率,但也可以尝试其他策略来解决“20个问题”挑战。
我们还可以结合多种策略来提升模型表现。
4.1. 决策树在 20 个问题游戏中的应用
在这个场景中,我们使用的是分类树,因为我们要从多个选项中找出正确的标签。
叶节点代表我们要猜测的对象,分支代表问题的答案。
为了说明决策树的原理,我们考虑一个简化版的游戏:只有四个可能的答案:狗(dog)、猫(cat)、胡萝卜(carrot)、叉子(fork)。
如果我们精心选择问题,只需两个问题就能准确猜出答案:
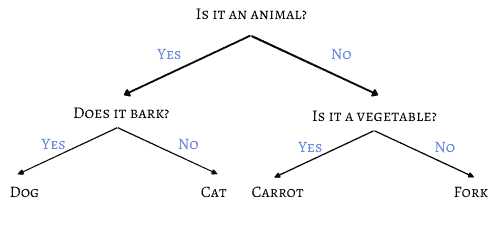
数学上,我们可以用以下公式来定义问题数量:
(4) 
反过来,如果我们知道问题数量,也可以计算能猜出的类别数:
(5) 
因此,在 20 个问题游戏中,我们能识别的类别数为:
(6) 
仅需 20 个问题,我们就能识别超过一百万个对象,这充分说明了决策树在这个任务中的高效性。
需要注意的是,这些计算的前提是我们要有一组最优问题,能逐步缩小范围。这种最优问题集合可以通过学习策略来实现。
理想情况下,每个问题都能将可能答案分成两半,找到最能区分对象的特征。
这样,我们的学习树就能像二分查找一样工作,每次游戏后都记录结果,学习哪些问题最有效。
4.2. 随机样本一致性(RANSAC)
除了使用决策树,我们还可以结合 RANSAC(Random Sample Consensus)策略来提高准确性。
RANSAC 的做法是:随机选取 20 个问题中的一部分,而不是全部,然后验证输出是否一致。
我们重复这个过程多次,使用不同的子集进行验证。
✅ 优点:这种方法可以减少玩家答错问题对最终结果的影响,因为 RANSAC 是一种异常值检测方法。
❌ 缺点:需要多次运行,增加了计算成本。
⚠️ 注意:适合用于对抗玩家故意答错或误答的情况。
5. 总结
在本文中,我们探讨了如何使用一种非参数模型——决策树,来实现“20个问题”游戏。
我们不仅介绍了决策树的基本原理,还通过数学公式证明了问题数量与可识别类别之间的关系,并讨论了如何结合其他策略(如 RANSAC)来提升模型准确性。
✅ 关键点:
- 决策树是分类和回归任务的有力工具
- 每个问题理论上可以将可能答案减半
- 结合 RANSAC 可以提高抗干扰能力
掌握这些原理后,我们就可以构建一个智能的“20个问题”AI系统,甚至将其扩展到其他更复杂的分类任务中。