1. 简介
有向图在现实应用中广泛用于表示依赖关系。例如,课程安排中的前置课程关系就可以用有向图建模。
如果图中存在环,则可能意味着死锁。换句话说,完成第一个任务需要等待第二个任务完成,而第二个任务又依赖第一个任务的完成。因此,检测环的存在至关重要,能有效避免这种死锁情况的发生。
2. 问题说明
在有向图中,我们希望找出其中的环。这些环可以很简单,例如一个顶点连接自己,或者两个顶点相互指向:
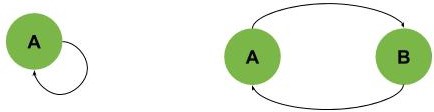
也可以是更复杂的环,比如下图中的 B-C-D-E 环:
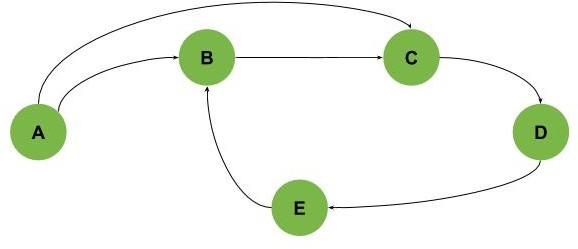
此外,还可能存在多个相互交叉的环结构,如下图所示(包含三个环:A-B-C-E-D、B-C-E-D 和 E-D-F):
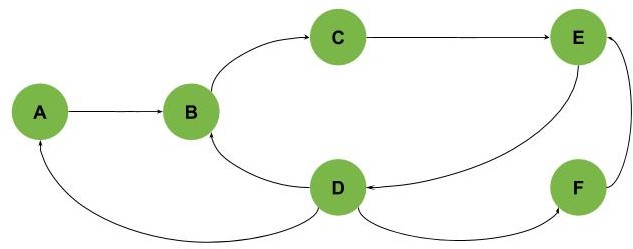
需要注意的是,并非所有图都能通过任意起点遍历找到所有环。有些图需要从多个未访问的点开始遍历才能完整检测,如下图所示(环为 C-D-E 和 G-H):
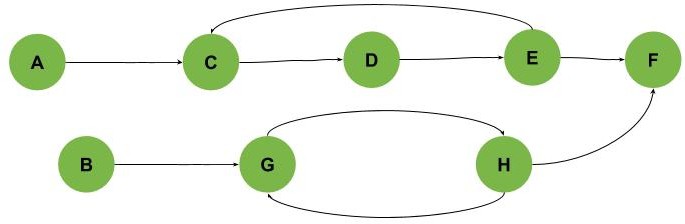
3. 算法思路
在简单图中,我们可以直接遍历所有顶点来判断是否存在环。但在复杂图中,这种方法显然不适用。
✅ 常用方法是使用深度优先搜索(DFS)。通过 DFS 遍历图,可以构建出 DFS 树,并对边进行分类:
- 树边(Tree Edges):DFS 遍历过程中实际走过的边。
- 前向边(Forward Edges):从父节点指向其非直接子节点的边。
- 回边(Back Edges):从一个节点指向其祖先节点的边。
- 交叉边(Cross Edges):连接不同 DFS 树或不同分支之间的边。
其中,回边是判断图中是否存在环的关键。只要有回边存在,就说明图中存在至少一个环。
举个例子,在下图中 E-B 就是一条回边:
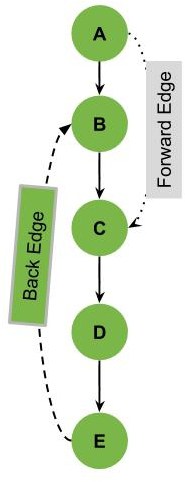
再看另一个例子,图中有多条回边:
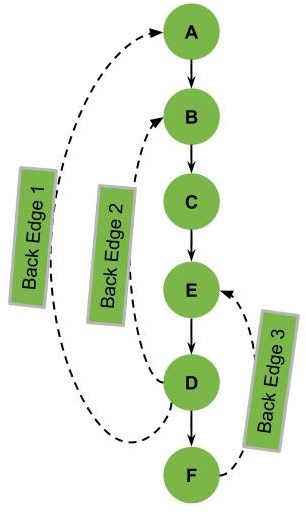
如果我们去掉所有回边,就能得到一个无环图(DAG,有向无环图)。
最后一个例子说明了交叉边的情况:
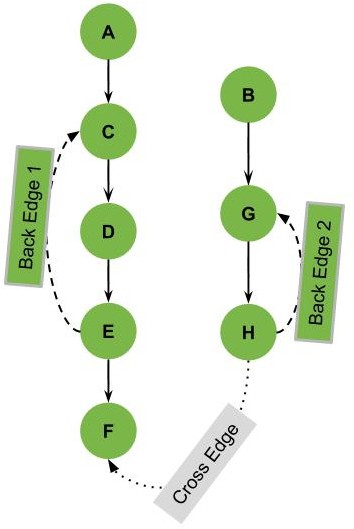
如果从 A 开始 DFS,无法访问到 B、G、H。因此,我们需要重新从这些未访问的节点开始 DFS,从而形成多个 DFS 树。
交叉边可能连接不同的 DFS 树,也可能在同一个树的不同分支之间。
⚠️ 总结:我们主要关注回边,因为它们是图中存在环的标志。
4. 流程图
检测环的流程本质上是 DFS 的扩展。我们需要:
- 遍历所有未访问的节点作为 DFS 起点。
- 在 DFS 过程中维护一个栈,记录当前路径。
- 每次遇到一个已经在栈中的节点时,说明发现了回边,即发现了环。
流程图如下:
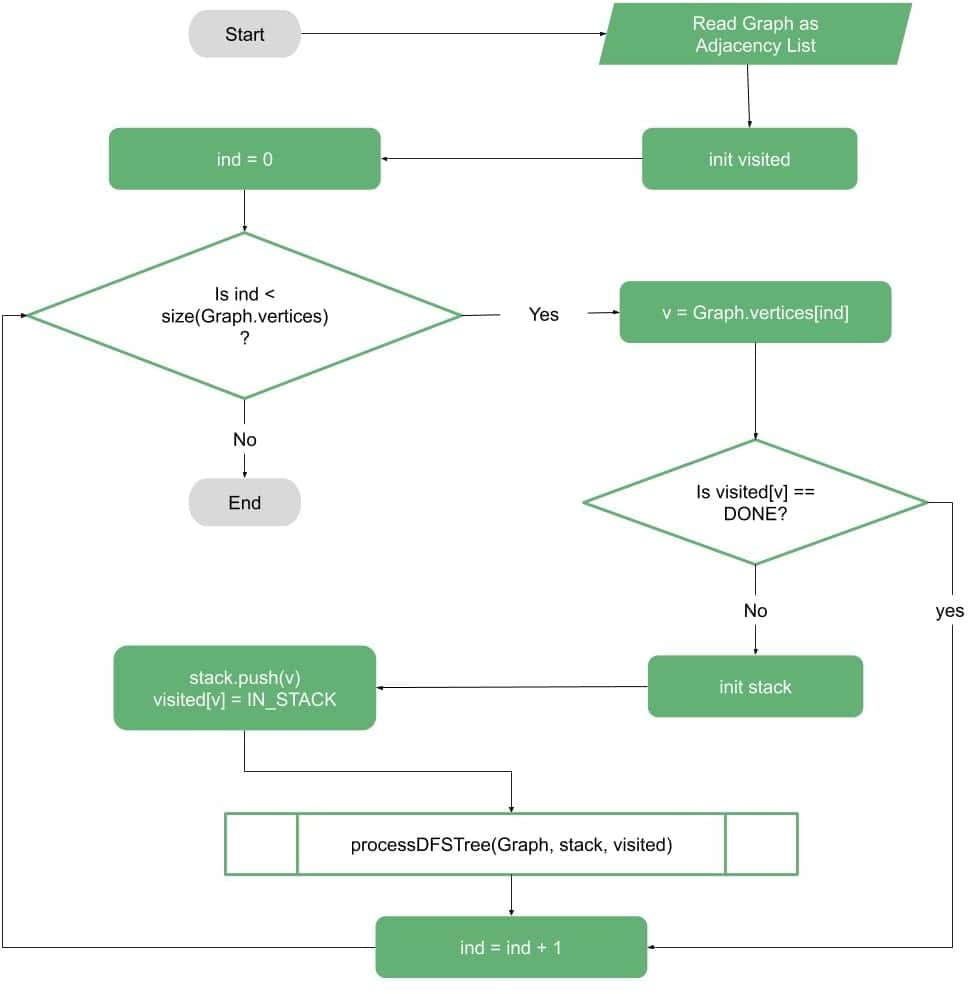
DFS 处理流程如下:
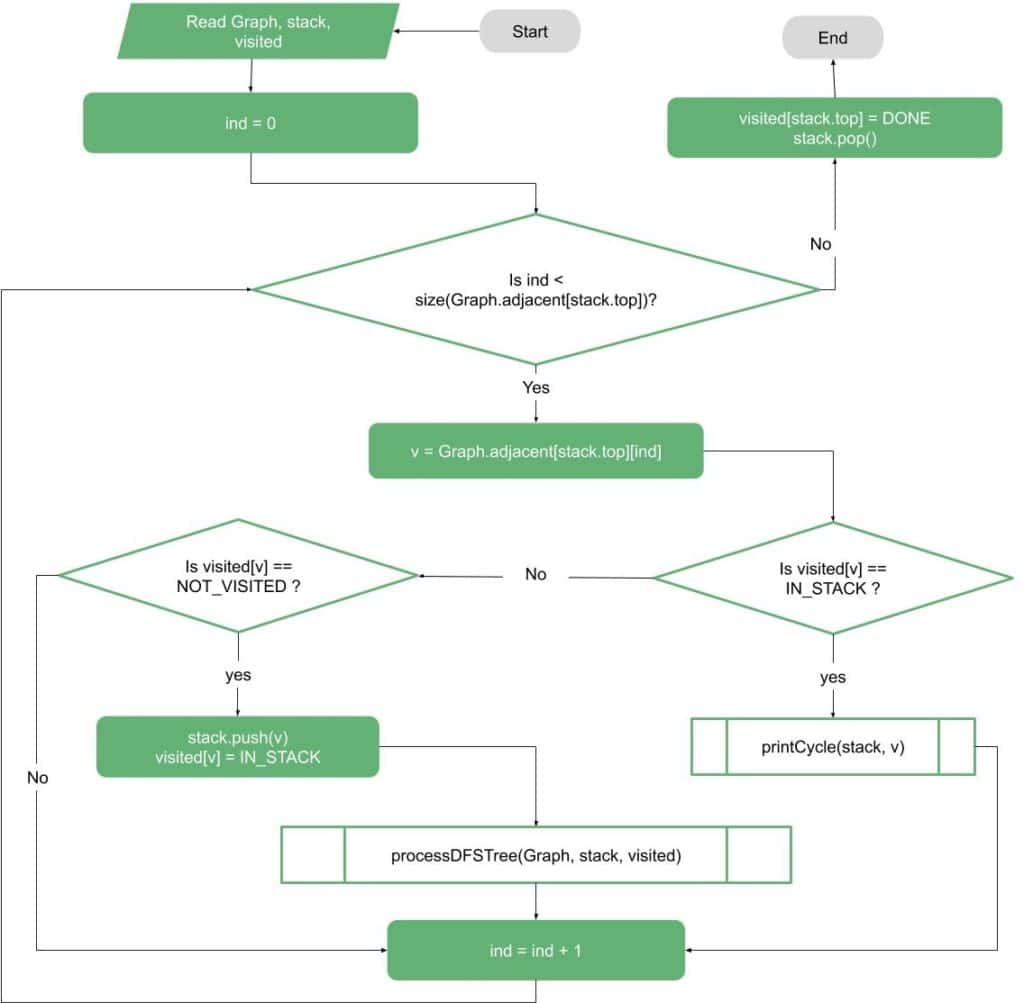
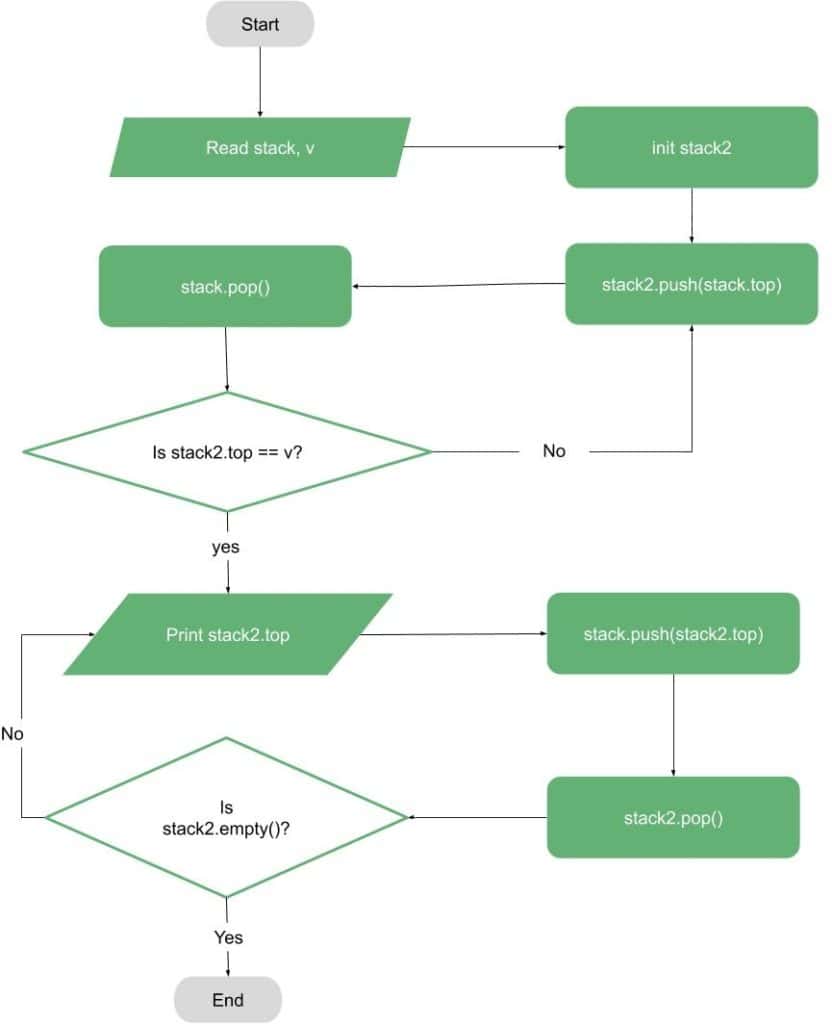
如果目标是打印第一个环,可以通过栈和临时栈实现:
如果目标是移除所有环,则只需标记所有回边并删除即可,无需打印所有环(打印所有环是 NP-Hard 问题)。
5. 伪代码
主算法
该算法基于邻接表表示图,使用 visited 数组标记节点状态(未访问、栈中、已处理):
algorithm findCycles(Graph):
// INPUT
// Graph = a graph
// OUTPUT
// Print all cycles in the graph
visited <- array of NOT_VISITED for each vertex in Graph
for each vertex v in Graph.vertices:
if visited[v] == NOT_VISITED:
stack <- empty stack
stack.push(v)
visited[v] <- IN_STACK
detectedCycles <- empty list
processDFSTree(Graph, stack, visited, detectedCycles)
DFS 处理函数
algorithm processDFSTree(Graph, Stack, visited, detectedCycles):
// INPUT
// Graph = a graph
// Stack = current path
// visited = a visited set
// detectedCycles = a collection of already processed cycles
// OUTPUT
// Print all cycles in the current DFS Tree
for each vertex v in Graph.adjacent[Stack.top]:
if visited[v] == IN_STACK:
printCycle(Stack, v, detectedCycles)
else if visited[v] == NOT_VISITED:
Stack.push(v)
visited[v] <- IN_STACK
processDFSTree(Graph, Stack, visited, detectedCycles)
visited[Stack.top] <- DONE
Stack.pop()
打印环函数
algorithm printCycle(Stack, v, detectedCycles):
// INPUT
// Stack = current path
// v = current node
// detectedCycles = a collection of already processed cycles
// OUTPUT
// Print the cycle that lives in the stack starting from vertex v
cycle <- empty list
cycle.push(Stack.top)
Stack.pop()
while cycle.top != v:
cycle.push(Stack.top)
Stack.pop()
if cycle not in detectedCycles:
detectedCycles.push(cycle)
print(cycle)
6. 时间与空间复杂度
打印所有环的复杂度:
- 时间复杂度:✅ O(V!)(因为需要枚举所有可能的环)
- 空间复杂度:✅ O(V!)(需要保存所有发现的环)
仅判断是否存在环的复杂度:
- 时间复杂度:✅ O(V + E)
- 空间复杂度:✅ O(V)
⚠️ 如果你只需要判断图中是否存在环,而不是打印所有环,建议使用后者,性能更优。
7. 总结
本文介绍了使用 DFS 检测有向图中环的算法:
- 利用 DFS 构建 DFS 树,并通过回边判断是否存在环。
- 提供了完整的伪代码实现。
- 分析了两种场景下的复杂度:
- 打印所有环:O(V!)
- 仅判断是否有环:O(V + E)
该算法在实际中广泛用于依赖检测、死锁预防等场景。掌握其原理和实现方式,有助于解决图结构中的复杂依赖问题。