1. 简介
本文介绍直接线性变换(Direct Linear Transform,简称 DLT),这是一种用于求解如下形式方程组的通用方法:
$$ \lambda\mathbf{x}_k = \mathbf{A} \mathbf{y}_k \quad \text{for } k=1, \ldots, N $$
这类问题在投影几何中非常常见。一个典型的例子是:如何将场景中的三维点投影到相机图像平面上。这也是我们选择相机模型作为背景来讲解 DLT 的原因。
2. 相机模型
最常用的数学相机模型是所谓的针孔相机模型(Pinhole Camera Model)。由于相机的核心功能是将现实世界中的物体映射为二维图像,因此该模型包含了多个坐标系统:
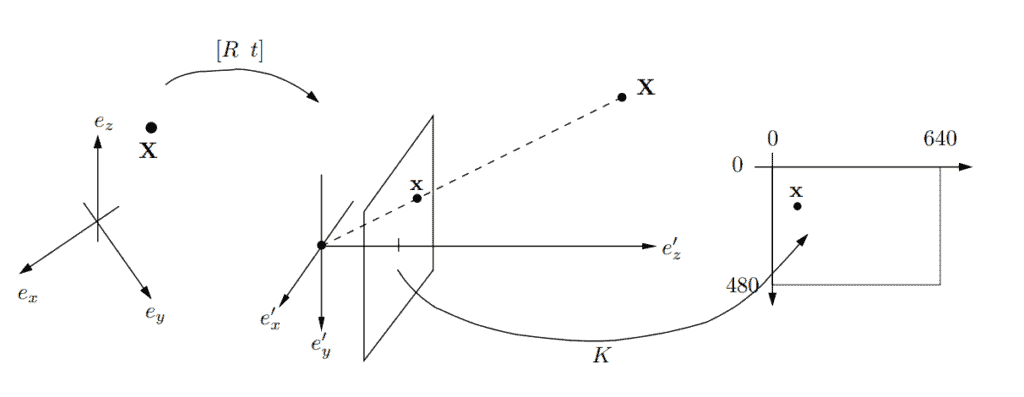
2.1. 全局坐标系
为了表示相机的位置和运动,我们使用参考坐标系 $\mathbf{{e_x, e_y, e_z}}$(图中左侧)。在这个坐标系中,相机可以进行平移和旋转。平移用向量 $t \in \mathbb{R}^3$ 表示,旋转用 $3\times3$ 的旋转矩阵 $R$ 表示。
通常,场景中所有点的坐标也都在这个全局坐标系下表示,并通过以下公式将它们转换到相机坐标系:
$$ \left(\begin{array}{l} X_1^{\prime} \ X_2^{\prime} \ X_3^{\prime} \end{array}\right) = R \left(\begin{array}{c} X_1 \ X_2 \ X_3 \end{array}\right)
- t $$
如果我们在向量末尾添加一个 1 作为齐次坐标,就可以用矩阵形式简洁表示:
$$ \left(\begin{array}{l} X_1^{\prime} \ X_2^{\prime} \ X_3^{\prime} \end{array}\right) = \left[\begin{array}{ll} R & t \end{array}\right] \left(\begin{array}{c} X_1 \ X_2 \ X_3 \ 1 \end{array}\right) $$
2.2. 相机坐标系
相机坐标系 $\mathbf{{e^\prime_x, e^\prime_y, e^\prime_z}}$(图中中间部分)的原点 $\mathbf{C = (0,0,0)}$ 表示相机中心(即针孔)。为了将场景点 $X = (X'_1, X'_2, X'_3)$ 投影到图像平面上,我们连接点 $X$ 和 $C$,并与图像平面 $Z = 1$ 相交,交点即为投影点 $x = (x_1, x_2, 1)$。
⚠️ 注意:与真实相机不同,图像平面在针孔“前面”,这是为了数学处理方便而设计的,因此图像不会上下颠倒。
2.3. 内参矩阵
在针孔模型中,图像平面位于 $\mathbb{R}^3$ 中,因此投影点的单位是物理长度。但在实际图像中,我们使用像素坐标(例如 640×480 像素)。
为了将物理坐标转换为像素坐标,我们需要一个内参矩阵(Intrinsic Matrix)$K$,它是一个可逆的上三角 $3\times3$ 矩阵,包含相机的内参,如焦距、主点、纵横比和轴偏斜。
2.4. 完整模型
综合以上三部分,我们可以写出完整的相机投影公式:
$$ \lambda \left(\begin{array}{l} x_1 \ x_2 \ 1 \end{array}\right) = K \left[\begin{array}{ll} R & t \end{array}\right] \left(\begin{array}{c} X_1 \ X_2 \ X_3 \ 1 \end{array}\right) $$
也可以简化为:
$$ \lambda x = PX $$
其中 $P$ 称为相机矩阵(Camera Matrix)。这个形式正是 DLT 可以求解的类型。
3. 相机标定
为什么我们需要求解这个问题?大多数情况下,我们关心的是 $P$ 中的内参矩阵 $K$。一旦 $K$ 已知,就说明相机已经标定完成 ✅。
有了标定好的相机,我们就可以进行:
- 镜头畸变校正(如鱼眼矫正)
- 图像中物体测量
- 从相机运动中估计三维坐标
要完成标定,我们首先需要至少 6 组人工测量的数据点,然后使用 DLT 方法求解相机矩阵 $P$,最后通过 RQ 分解将其分解为 $K\left[\begin{array}{ll}R & t\end{array}\right]$。
4. DLT 方法详解
DLT 方法的第一步是构建一个齐次线性方程组,并通过求其近似零空间来求解。
我们将相机矩阵 $P$ 表示为行向量形式:
$$ P = \begin{bmatrix} p_1^T \ p_2^T \ p_3^T \end{bmatrix} $$
于是相机方程可以写为:
$$ \mathbf{X}_i^T p_1 - \lambda_i x_i = 0 \ \mathbf{X}_i^T p_2 - \lambda_i y_i = 0 \ \mathbf{X}_i^T p_3 - \lambda_i = 0 $$
这些方程可以写成矩阵形式:
$$ \left[\begin{array}{cccc} \mathbf{X}_i^T & 0 & 0 & -x_i \ 0 & \mathbf{X}_i^T & 0 & -y_i \ 0 & 0 & \mathbf{X}_i^T & -1 \end{array}\right] \left(\begin{array}{l} p_1 \ p_2 \ p_3 \ \lambda_i \end{array}\right) = \left(\begin{array}{l} 0 \ 0 \ 0 \end{array}\right) $$
如果我们把所有测量点的投影方程堆叠起来,就能得到一个大型矩阵 $M$,使得:
$$ Mv = 0 $$
我们的目标是找到非零解 $v$,也就是 $M$ 的零空间中的向量。由于测量中存在噪声,通常没有精确解,因此我们转而求解一个最小二乘问题。
✅ 解决方法之一是使用奇异值分解(SVD):对 $M$ 进行 SVD 分解,取最小奇异值对应的右奇异向量作为解,从而得到相机矩阵 $P$。最后通过 QR 分解将 $P$ 分解为 $K\left[\begin{array}{ll}R & t\end{array}\right]$。
5. 总结
本文我们介绍了针孔相机模型,并通过求解相机内参的场景引出了 DLT 方法。我们展示了 DLT 的核心思想和实现步骤,包括构建线性系统、求解零空间、使用 SVD 和 QR 分解等。
虽然 DLT 本身是线性方法,但在实际应用中表现良好,尤其适用于有噪声的测量数据。它是计算机视觉中相机标定和三维重建的基础工具之一。