1. 概述
在本文中,我们将介绍机器学习中的集成学习方法。
接着,我们会讲解集成学习的常见类型,并通过流程图帮助理解。最后,我们还会介绍集成学习在多个领域的实际应用。
2. 什么是集成学习
集成学习(Ensemble Learning)是一种通过组合多个模型来提升整体预测性能的机器学习技术。其核心思想是“众人拾柴火焰高”——多个模型的集体决策通常优于单一模型的结果。
集成学习可以用于分类、回归等任务,尤其在数据复杂、模型容易过拟合或欠拟合的情况下,集成方法往往能带来显著的性能提升。
3. 常见的集成学习方法
集成学习主要包括以下三类主流方法:
- Bagging(Bootstrap Aggregating)
- Boosting(提升法)
- Stacking(堆叠法)
下面我们分别介绍每种方法的核心思想和实现流程。
3.1. Bagging
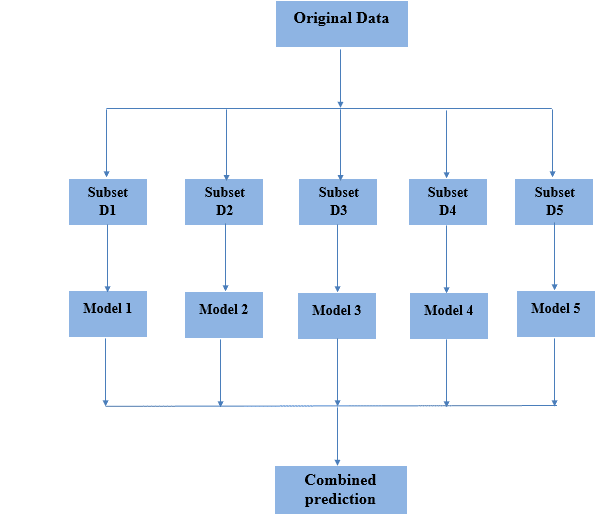
Bagging 是 Bootstrap Aggregating 的缩写,其核心思想是通过自助采样(Bootstrap)生成多个子数据集,然后分别训练多个基模型,最后通过投票或平均的方式融合结果。
核心步骤如下:
✅ 从原始数据集中有放回地随机抽样生成多个子数据集(每个子集大小与原始数据集相同)
✅ 每个子数据集独立训练一个基模型(如决策树)
✅ 所有模型的预测结果进行集成:分类任务用投票法,回归任务用平均法
优点:
- 减少模型方差(variance),防止过拟合
- 提高模型稳定性
- 适合不稳定的模型(如决策树)
Bagging流程图如下:
3.2. Boosting
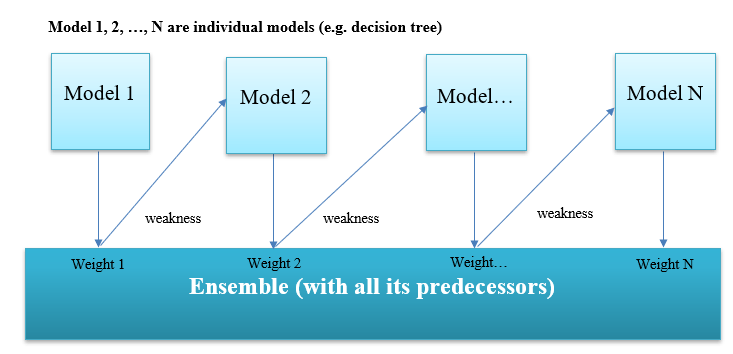
Boosting 是一种通过逐步训练多个弱模型,并根据前一个模型的错误不断调整样本权重,最终组合成一个强模型的方法。
核心思想:
✅ 弱模型在训练时关注之前模型预测错误的样本
✅ 每个模型的预测结果加权组合,形成最终输出
✅ 错误样本在后续模型中获得更高权重,以提升整体精度
Boosting流程图如下:
常见Boosting算法包括:
- AdaBoost
- Gradient Boosting
- XGBoost
- LightGBM
优点:
- 减少模型偏差(bias)
- 在数据复杂、特征关系不明显时表现优异
- 能有效处理高维数据
⚠️ 注意:Boosting模型容易过拟合,尤其在数据噪声较多时,需谨慎调参。
3.3. Stacking
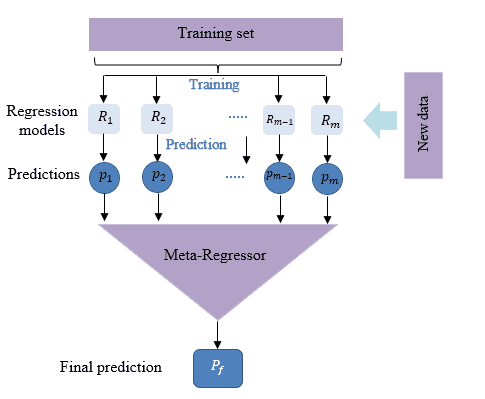
Stacking 是一种通过训练一个“元模型”(Meta-model)来整合多个基模型预测结果的方法。
核心流程如下:
✅ 多个基模型(level-1模型)分别对训练集进行预测
✅ 使用这些预测结果作为新特征,训练一个元模型(level-2模型)
✅ 最终模型由元模型输出最终预测结果
示例图如下:
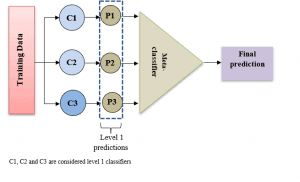
图中展示了三个基模型(C1、C2、C3)和一个元模型(Meta-classifier)。
Stacking的技巧:
- 基模型应尽量多样化,如使用不同算法或不同参数的模型
- 元模型建议使用泛化能力强的模型,如逻辑回归、神经网络等
- 避免元模型过拟合:使用交叉验证生成基模型预测结果
Stacking流程图如下:
优点:
- 可以融合不同模型的优势,提升整体性能
- 适用于分类和回归任务
- 模型结构灵活,可扩展性强
4. 集成学习的应用场景
随着计算能力的提升,集成学习在多个领域得到了广泛应用。以下是一些典型应用场景:
✅ 医疗领域
- 神经科学:使用MRI数据识别神经认知障碍
- 蛋白质组学:蛋白质功能分类
- 医学诊断:宫颈细胞学分类、癌症预测等
✅ 情感识别
虽然主流情感识别依赖深度学习,但集成学习在语音情感识别中也有良好表现,尤其适合数据量较小或特征维度较高的场景。
✅ 人脸识别
人脸识别是模式识别的热点方向之一。集成方法如AdaBoost、Random Forest等被广泛用于人脸检测和特征提取。
✅ 入侵检测系统(IDS)
入侵检测系统需要实时监控网络行为,识别异常模式。集成学习在提高检测精度、降低误报率方面表现优异。
✅ 其他应用
- 网络安全:恶意软件检测
- 遥感:遥感图像分类
- 金融风控:欺诈检测、信用评分等
5. 总结
集成学习的核心理念是通过组合多个模型来提升整体预测性能。与试图寻找一个“最优模型”不同,集成方法利用多个模型的协同决策,获得更稳定、更准确的结果。
本文我们介绍了集成学习的基本概念,以及三种主流方法:
- Bagging 通过自助采样减少模型方差
- Boosting 通过加权样本逐步提升模型精度
- Stacking 通过元模型融合多个模型的优势
集成学习在医疗、金融、图像识别、安全检测等多个领域都有广泛应用。对于有经验的开发者而言,掌握这些方法可以显著提升建模效果,是实战中不可或缺的利器。