1. 概述
机器学习(Machine Learning,简称 ML)是人工智能的一个分支,它使计算机能够在没有显式编程的情况下进行学习。在构建机器学习模型时,我们使用的输入变量被称为 特征(Features)。
本文将介绍 特征选择(Feature Selection),也称为属性选择(Attribute Selection),它是一组用于挑选出最有用、最关键特征的方法。
特征选择在很多领域都有广泛应用,比如遥感、图像检索、自然语言处理等。
2. 为什么需要特征选择?
在数据集中,对象通常通过特征进行描述。因此,大多数情况下数据是以表格形式存在的:行代表对象,列代表特征。
然而,如果特征过多,模型可能会学习到一些无效甚至误导性的模式。因为通常一些特征与目标变量无关,反而会引入噪声。如果模型基于这些特征进行预测,其准确性可能会大打折扣。此外,特征数量多也会显著增加训练时间。
因此,通常我们会选择使用部分特征来训练模型,以避免学习到噪声信息:

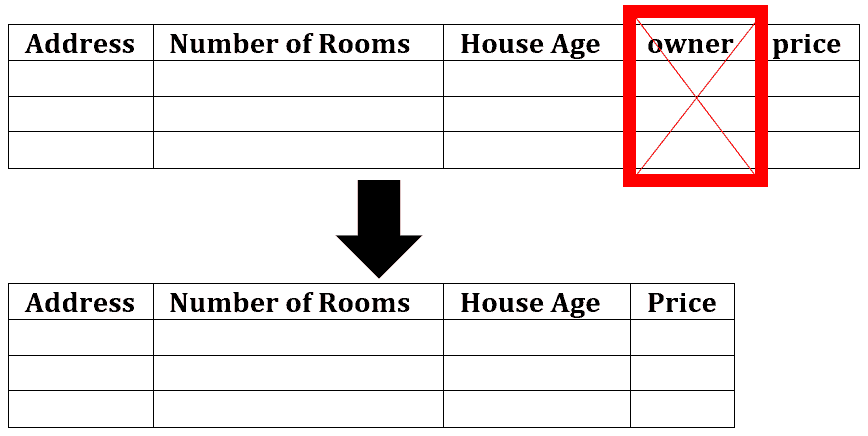
例如,在预测房屋售价时,“房间数量”和“地址”是有用的特征,而“当前房主姓名”则没有相关性。如果模型将房主姓名纳入考虑,可能会导致预测错误,使模型不准确。因此,我们可以删除这个列:
3. 特征选择方法
特征选择的目标是从原始特征集合中选择出最相关的子集,通过去除冗余、噪声和无关特征来提升模型性能。
常见的特征选择方法如下图所示:
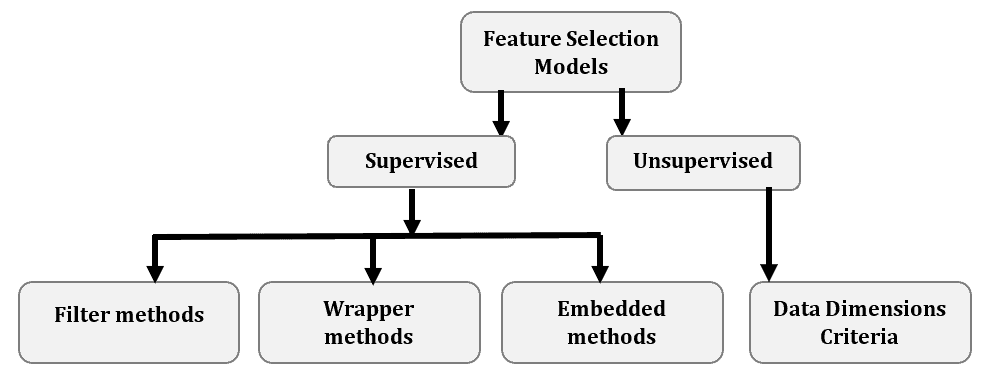
3.1 有监督 vs 无监督方法
- 无监督特征选择方法适用于无标签数据。它通过一些统计指标(如熵、方差、局部相似性保持能力等)对每个特征进行评分。
- 有监督特征选择方法用于有标签数据,通过评估哪些特征最有助于提升监督模型的性能。
有监督方法根据选择策略又可以分为三类:
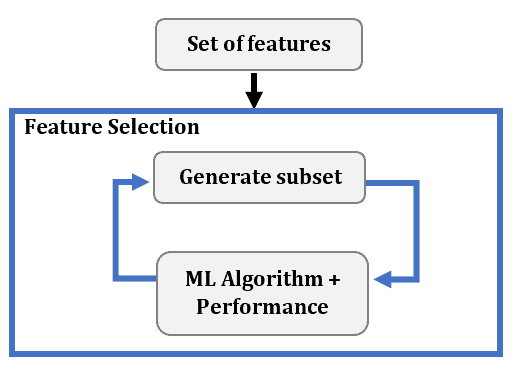
3.2 包装方法(Wrapper Methods)
包装方法是在选定机器学习算法之后使用的。 它通过训练和评估不同特征子集下的模型性能,来决定添加或移除哪些特征。这个过程是迭代的:
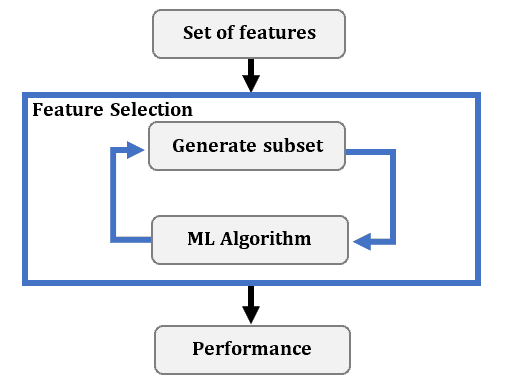
通常采用贪心策略来构建特征子集。
- 前向选择(Forward Selection):从空特征集开始,每次添加一个能使模型性能提升最大的特征,直到没有明显提升为止。
- 反向剔除(Backward Elimination):从所有特征开始,逐步剔除最不重要的特征。
- 逐步选择(Stepwise Selection):结合前向和反向策略,可以在每一步中添加或删除特征。
例如,如果有 n 个特征,前向选择会在第一轮构建 n 个模型,每轮选择表现最好的特征加入子集。
3.3 过滤方法(Filter Methods)
过滤方法通过统计方法来评估特征与目标之间的关系,从而筛选出相关性高的特征。这些方法通常在模型训练前进行特征选择:
常用统计指标包括:
- 卡方检验(Chi-Square Test)
- 信息增益(Information Gain)
- Fisher得分(Fisher’s Score)
- 皮尔逊相关系数(Pearson Correlation)
- 方差阈值(Variance Thresholding)
- ANOVA(方差分析)
这些方法计算效率高,适用于大规模数据集。
3.4 内嵌方法(Intrinsic / Embedded Methods)
内嵌方法在模型训练过程中自动完成特征选择,是模型自身机制的一部分:
例如:
- 决策树(Decision Tree)在分裂节点时会选择最优特征;
- Lasso 回归通过 L1 正则化自动将不重要的特征系数压缩为 0;
- 随机森林(Random Forest)等集成模型也会在训练过程中评估特征重要性。
这类方法结合了模型训练和特征选择,效率高且效果好。
4. 优缺点分析
✅ 优点:
- 减少过拟合:特征越少,模型越不容易学习到噪声;
- 提升准确性:去除误导性和不相关特征后,模型表现更稳定;
- 缩短训练时间:特征减少意味着数据量减少,训练速度提升。
❌ 缺点:
- 对高维数据处理效率低:特征越多,特征选择耗时越长;
- 小样本下容易过拟合:如果样本数量不足,特征选择过程本身也可能引入偏差。
⚠️ 踩坑提示:在使用 Wrapper 方法时,由于需要反复训练模型,计算开销很大,不适合特征维度特别高的场景。
5. 总结
特征选择是机器学习项目中非常关键的一步。通过去除无关或冗余特征,可以提升模型性能、缩短训练时间并减少过拟合风险。
根据数据是否有标签,可以选择有监督或无监督方法;根据实现方式,可以使用包装、过滤或内嵌方法。
在实际应用中,建议结合多种方法进行特征选择,以获得最佳效果。