1. 概述
本文将讨论如何统计一个字符串 T 作为子序列在另一个字符串 S 中出现的次数。
我们将依次介绍以下内容:
- 问题定义与示例
- 递归解法
- 动态规划解法
- 动态规划空间优化版本
- 总结
2. 问题定义
给定两个字符串 S 和 T,我们要统计 T 在 S 中作为子序列出现的次数。
子序列是指从原字符串中删除若干字符(也可以不删除),但不改变剩余字符顺序所形成的新序列。
示例
假设:
S = "ababc"T = "abc"
那么我们希望找出 T 在 S 中作为子序列的出现次数。如下图所示,共有 3 个匹配的子序列:
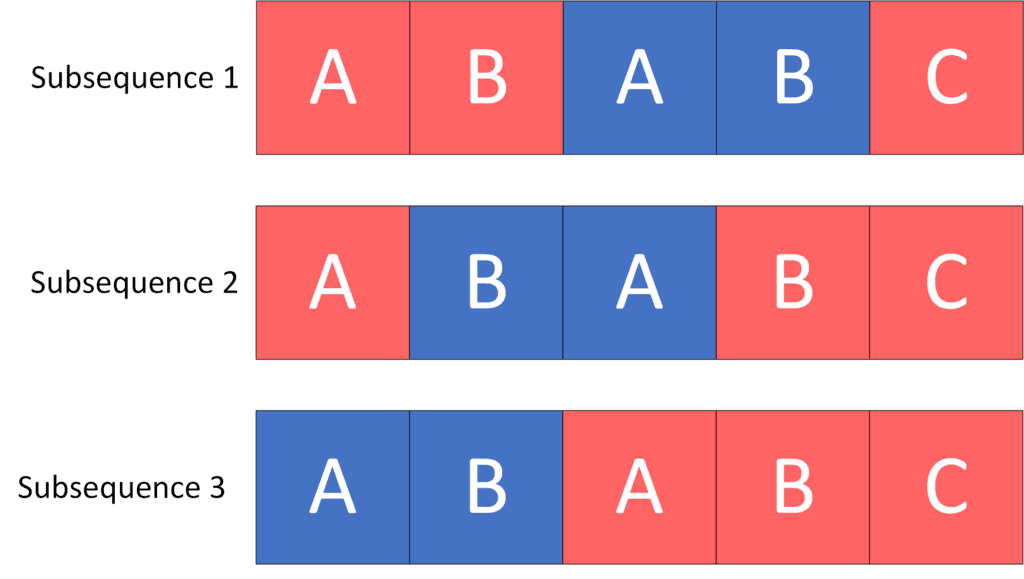
因此,示例的输出应为:3
3. 递归解法
3.1 思路
我们可以使用递归来尝试所有可能的子序列组合,判断是否匹配 T。
对于 S 中的每一个字符,我们有两个选择:
- 保留该字符:如果它与当前
T[j]匹配,则继续匹配下一个字符 - 跳过该字符
递归终止条件:
- 如果
j == T.length(),说明找到了一个匹配的子序列,返回1 - 如果
i == S.length()但j < T.length(),说明没有匹配完成,返回0
3.2 代码实现
int countSubsequences(String S, String T, int i, int j) {
if (i == S.length() && j == T.length()) return 1;
if (i == S.length()) return 0;
int count = 0;
// Pick current character
if (j < T.length() && S.charAt(i) == T.charAt(j)) {
count += countSubsequences(S, T, i + 1, j + 1);
}
// Leave current character
count += countSubsequences(S, T, i + 1, j);
return count;
}
调用方式:
int result = countSubsequences(S, T, 0, 0);
3.3 时间复杂度分析
- 时间复杂度:
O(2^min(N,M)),其中N = S.length(),M = T.length() - 空间复杂度:
O(N),递归栈的最大深度
⚠️ 该解法在 S 或 T 较长时会超时,不适合实际使用。
4. 动态规划解法
4.1 思路
使用动态规划优化递归重复计算的问题。
我们定义一个二维数组 dp[i][j],表示从 S[i...] 中找到 T[j...] 的子序列数量。
状态转移:
- 如果
S[i] == T[j],可以选择匹配该字符,此时dp[i][j] += dp[i+1][j+1] - 无论是否匹配,都可以跳过当前字符,
dp[i][j] += dp[i+1][j]
初始化:
dp[S.length()][T.length()] = 1,表示完全匹配- 其余
dp[i][T.length()] = 1,表示T已匹配完成
4.2 代码实现
int countSubsequencesDP(String S, String T) {
int n = S.length(), m = T.length();
int[][] dp = new int[n + 1][m + 1];
// 初始化:当 T 已匹配完成,无论 S 剩余多少,都算 1 种情况
for (int i = 0; i <= n; i++) {
dp[i][m] = 1;
}
for (int i = n - 1; i >= 0; i--) {
for (int j = m - 1; j >= 0; j--) {
if (S.charAt(i) == T.charAt(j)) {
dp[i][j] += dp[i + 1][j + 1];
}
dp[i][j] += dp[i + 1][j];
}
}
return dp[0][0];
}
4.3 时间复杂度分析
- 时间复杂度:
O(N * M) - 空间复杂度:
O(N * M)
✅ 适用于大多数场景,但仍有优化空间。
5. 动态规划空间优化
5.1 思路
观察状态转移方程可以发现,dp[i][j] 只依赖于 dp[i+1][j] 和 dp[i+1][j+1]。
因此,我们只需保留两行即可完成状态更新,使用滚动数组技巧将空间复杂度优化为 O(M)。
5.2 代码实现
int countSubsequencesDPOptimized(String S, String T) {
int n = S.length(), m = T.length();
int[][] dp = new int[2][m + 1];
// 初始化:T 已匹配完成时,返回 1
dp[n % 2][m] = 1;
for (int i = n - 1; i >= 0; i--) {
for (int j = m - 1; j >= 0; j--) {
dp[i % 2][j] = 0;
if (S.charAt(i) == T.charAt(j)) {
dp[i % 2][j] += dp[(i + 1) % 2][j + 1];
}
dp[i % 2][j] += dp[(i + 1) % 2][j];
}
}
return dp[0][0];
}
5.3 时间复杂度分析
- 时间复杂度:
O(N * M) - 空间复杂度:
O(M),只使用了两行存储
✅ 空间优化明显,适合大规模输入。
6. 总结
| 方法 | 时间复杂度 | 空间复杂度 | 是否推荐 |
|---|---|---|---|
| 递归 | O(2^min(N,M)) |
O(N) |
❌ 不推荐 |
| 动态规划 | O(N * M) |
O(N * M) |
✅ 推荐 |
| 动态规划优化 | O(N * M) |
O(M) |
✅✅ 推荐 |
小贴士(踩坑提醒)
- ✅ 不要使用递归:递归在大输入下容易栈溢出或超时
- ✅ 优先使用空间优化版动态规划:节省内存且性能稳定
- ✅ 注意字符比较时的边界条件:避免越界错误
通过上述三种方法,我们可以灵活应对不同规模的数据需求。在实际开发中,建议优先使用空间优化的动态规划方案。