1. 概述
在本教程中,我们将介绍遗传算法中一种常用的交叉操作:顺序交叉(Order One Crossover, OX1)。我们会通过示例来讲解其具体操作流程,并分析其优缺点。
2. 简介
遗传算法(Genetic Algorithms, GAs) 是一种基于自然选择和遗传机制的优化算法,广泛用于解决复杂的优化问题。在遗传算法中,交叉(Crossover) 是生成新个体的关键步骤之一。
在交叉过程中,算法会从当前种群中选择两个父代个体,通过某种策略组合它们的基因信息,生成两个子代个体。常见的交叉策略包括:
- 顺序交叉(Order One Crossover)
- 均匀交叉(Uniform Crossover)
- 双点交叉(Two-Point Crossover)
其中,顺序交叉(OX1) 特别适用于排列型问题(Permutation Problems),例如旅行商问题(TSP)等。它的核心思想是:在两个父代个体之间交换部分基因,并保留未交换部分的顺序信息,从而生成新的子代个体。
3. 工作流程
OX1 的执行流程主要包括以下三个步骤:
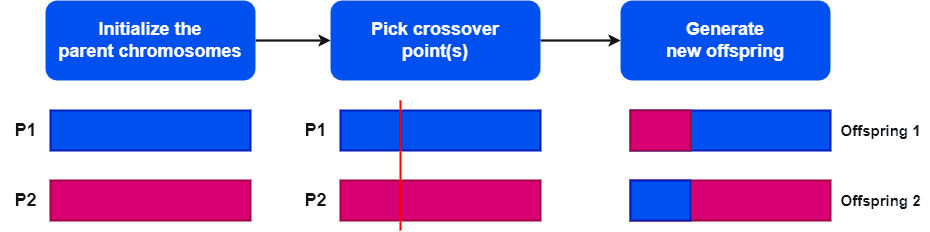
- 选择两个父代个体:从当前种群中选择两个父代染色体。
- 随机选择交叉点:通常选择一个随机位置作为交叉点,将染色体分为两段。
- 生成两个子代个体:
- 子代1的后半部分从父代1复制,前半部分从父代2选取未重复的元素填充。
- 子代2的后半部分从父代2复制,前半部分从父代1选取未重复的元素填充。
整个过程中,每个子代个体的长度与父代个体保持一致,并且不允许出现重复元素(前提是父代本身没有重复)。
4. 示例说明
我们以两个父代个体为例来演示 OX1 的执行过程:
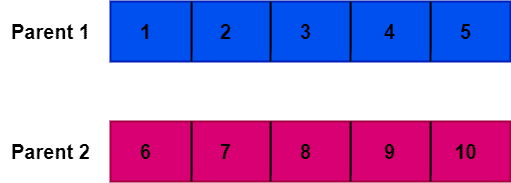
假设我们选择交叉点为索引2:
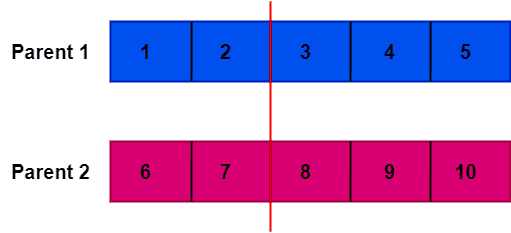
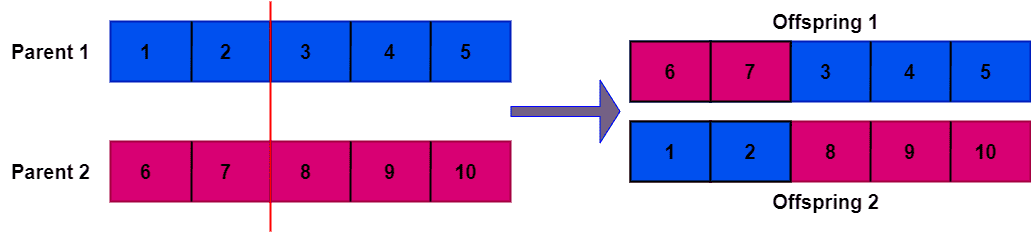
接下来:
- 子代1的后半部分从父代1复制,前半部分从父代2中选取未出现在后半部分的元素。
- 子代2的后半部分从父代2复制,前半部分从父代1中选取未出现在后半部分的元素。
最终生成的两个子代个体如下:
⚠️ 注意:如果父代个体中存在重复元素,那么子代个体也可能出现重复元素,如下图所示:
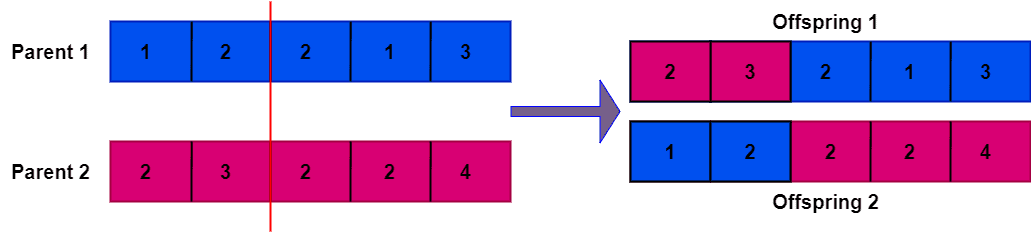
5. Python 实现
5.1 引入依赖
import random
5.2 定义主函数
我们定义一个函数 order1_crossover,接受两个父代个体和一个交叉点作为输入,返回两个子代个体:
def order1_crossover(p1, p2, cross_point):
...
5.3 函数内部逻辑
首先检查两个父代个体长度是否一致:
if len(p1) != len(p2):
raise ValueError("父代个体长度不一致")
初始化两个子代个体:
newp1 = [0] * len(p1)
newp2 = [0] * len(p2)
从交叉点开始复制后半部分:
for i in range(cross_point, len(p1)):
newp1[i] = p1[i]
newp2[i] = p2[i]
然后从前半部分开始填充未重复的元素:
for i in range(cross_point):
if p1[i] not in newp1:
newp1[i] = p2[i]
if p2[i] not in newp2:
newp2[i] = p1[i]
最后返回两个新个体:
return newp1, newp2
5.4 完整代码
import random
def order1_crossover(p1, p2, cross_point):
if len(p1) != len(p2):
raise ValueError("父代个体长度不一致")
newp1 = [0] * len(p1)
newp2 = [0] * len(p2)
for i in range(cross_point, len(p1)):
newp1[i] = p1[i]
newp2[i] = p2[i]
for i in range(cross_point):
if p1[i] not in newp1:
newp1[i] = p2[i]
if p2[i] not in newp2:
newp2[i] = p1[i]
return newp1, newp2
# 示例调用
p1 = [1, 2, 3, 4, 5]
p2 = [6, 7, 8, 9, 10]
cross_point = random.randint(1, len(p1) - 2)
try:
child1, child2 = order1_crossover(p1, p2, cross_point)
print("子代1:", child1)
print("子代2:", child2)
except ValueError as e:
print(e)
输出示例:
子代1: [6, 7, 3, 4, 5]
子代2: [1, 2, 8, 9, 10]
6. 优点
✅ 维护种群多样性:OX1 通过交叉两个父代个体生成新的子代,有助于保持种群多样性,避免陷入局部最优。
✅ 实现简单:只需一个交叉点,逻辑清晰,易于实现。
✅ 保留关键信息:OX1 保留了父代个体的部分顺序结构,有助于保留关键基因信息。
7. 缺点
❌ 探索能力有限:由于只在现有种群内交叉,缺乏引入新基因的能力,搜索空间探索受限。
❌ 容易早熟收敛:如果初始种群相似度高,可能导致早熟收敛,难以跳出局部最优。
❌ 仅适用于排列问题:OX1 主要适用于排列型问题,对于实数编码、二进制编码等问题不适用。
8. 总结
本文介绍了遗传算法中的一种经典交叉操作——顺序交叉(Order One Crossover, OX1)。我们通过示例详细讲解了其工作流程,并给出了 Python 实现代码。
✅ OX1 在排列型问题中表现良好,能有效保留父代信息并生成多样化的子代个体。
⚠️ 但也要注意其局限性,如探索能力有限、不适用于非排列型问题等。
在实际使用中,应根据问题类型和种群特性选择合适的交叉策略,或结合多种交叉方式提高算法性能。