1. 概述
在图论中,SSSP(Single Source Shortest Path,单源最短路径)算法用于解决这样一个问题:从一个起始节点(源节点)出发,找到到图中所有其他节点的最短路径。常见的 SSSP 算法包括 BFS(广度优先搜索) 和 Dijkstra 算法。
本文将对这两个算法进行简要说明,指出它们的异同点,并说明在什么场景下应使用哪个算法。
2. 通用算法框架
这两个算法的核心思想是一致的:从源节点出发,逐步探索整个图。每一步中,我们都优先访问距离源节点最近的节点。
下图展示了通用 SSSP 算法的流程:
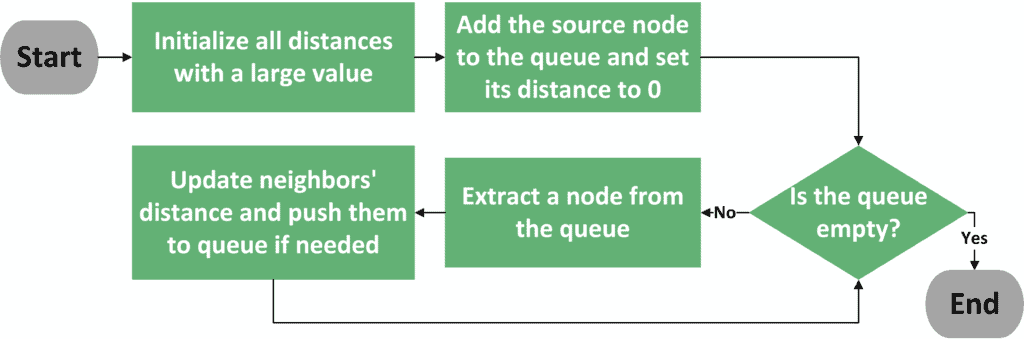
流程大致如下:
- 初始化所有节点的距离为一个极大值;
- 将源节点加入队列;
- 循环处理队列中的节点,直到队列为空;
- 每次从队列中取出一个节点,遍历其所有邻居;
- 如果发现更短的路径,就更新该邻居的距离,并将其加入队列;
- 最终,每个节点的距离即为从源节点出发的最短路径。
然而,由于图可以是无权图也可以是有权图,这个通用算法需要根据图的类型进行调整:
- BFS 用于无权图;
- Dijkstra 用于有权图。
3. BFS 算法
在无权图中,我们关心的是边数最少的路径。因此:
- 源节点的直接邻居距离为 1;
- 它们的邻居距离为 2;
- 以此类推。
一旦某个节点已经被访问过,我们就可以跳过它,因为我们已经找到了到达它的最短路径。
✅ 踩坑提醒:在 BFS 中,一旦节点被访问过,就不再处理,否则可能会导致重复计算或死循环。
实现要点
- 使用普通队列(FIFO);
- 时间复杂度为 **O(V + E)**,其中 V 为节点数,E 为边数。
4. Dijkstra 算法
在有权图中,最短路径不一定是由最少边数组成的路径。因此,Dijkstra 采用贪心策略:
- 每次选择当前距离源节点最近的节点进行处理;
- 使用优先队列(Priority Queue)来维护节点;
- 当发现更短路径时,更新节点的距离并重新加入队列。
⚠️ 踩坑提醒:同一个节点可能被多次加入队列,因为后续可能发现更短的路径。因此在取出节点时要判断当前距离是否已过时。
实现要点
- 使用优先队列来保证每次取出当前最短路径节点;
- 节点可能多次入队;
- 时间复杂度为 **O(V + E log V)**。
5. 示例对比
5.1 BFS 示例
以下是一个无权图的 BFS 示例:

节点按层级访问:
- 第一层:A、B、C;
- 第二层:D、E;
- 依此类推。
最终我们得到了从源节点 S 到所有节点的最短路径。
5.2 Dijkstra 示例
下图是同一图结构的有权版本,使用 Dijkstra 算法处理后的结果:
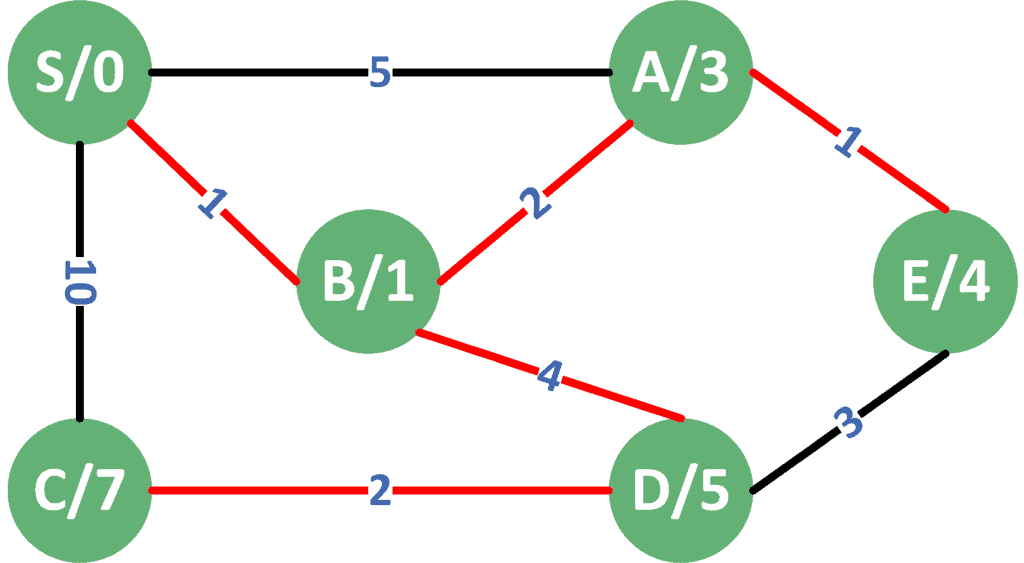
虽然 A 是 S 的直接邻居,但 Dijkstra 优先访问了 B,因为 S 到 B 的边权值最小。从 B 出发,又找到了到 A 的更短路径。
此外,虽然 C 是 S 的邻居,但由于边权值太大,最终是从其他路径到达 C 的。
6. 算法对比总结
| 特性 | BFS | Dijkstra |
|---|---|---|
| 核心思想 | 按层级访问最近节点 | 每次访问当前最短路径节点 |
| 是否最优 | 适用于无权图或边权相同的图 | 适用于有权图和无权图 |
| 使用队列类型 | 普通队列(FIFO) | 优先队列(Priority Queue) |
| 时间复杂度 | O(V + E) | O(V + E log V) |
7. 总结
本文介绍了 BFS 和 Dijkstra 算法的基本原理和实现思路,通过示例展示了它们在无权图和有权图上的行为差异,并对比了它们的优缺点和适用场景。
- ✅ BFS 更适用于无权图,效率高,实现简单;
- ✅ Dijkstra 更适用于有权图,能处理更复杂的情况,但实现稍复杂。
根据图的类型和实际需求,选择合适的算法是关键。