1. 简介
灰狼优化算法(Grey Wolf Optimization, GWO)是一种受自然界启发的元启发式优化算法,其灵感来源于灰狼群体的捕猎行为和等级制度。与遗传算法、萤火虫算法等其他仿生优化算法类似,GWO 通过在解空间中进行搜索,以期找到最优解。
✅ 核心思想:GWO 是一种迭代优化方法,适用于解决各类优化问题。
它通过模拟灰狼群体中不同角色(Alpha、Beta、Delta 和 Omega)之间的协作与捕猎行为,来引导搜索过程逐步逼近最优解。
2. 灵感来源
GWO 的核心灵感来自灰狼的群体行为,尤其是:
- 社会等级制度
- 捕猎机制
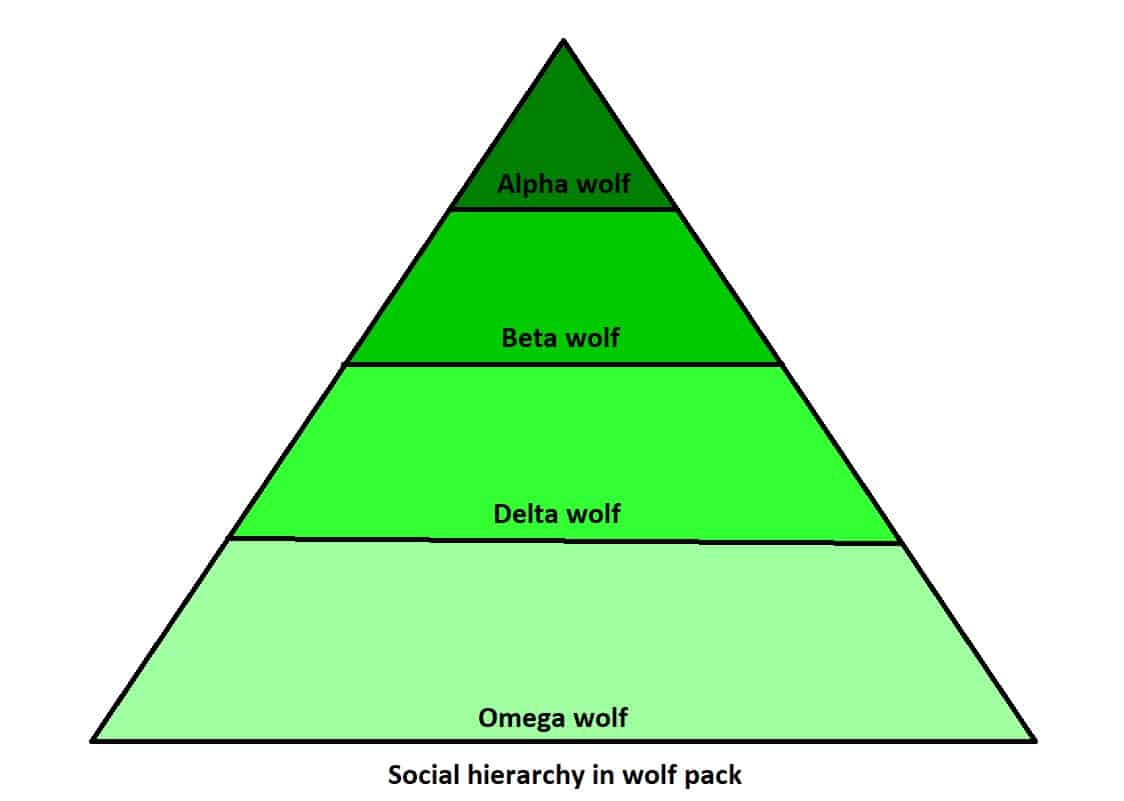
灰狼是高度社会化的动物,其群体内部存在清晰的等级结构:
- Alpha:狼群的首领,拥有最高决策权。
- Beta:协助 Alpha 管理狼群,是潜在的继任者。
- Delta:等级低于 Beta,通常具备较强能力但缺乏领导力。
- Omega:等级最低,通常负责照顾幼狼。
在捕猎过程中,灰狼群体会协同合作,采用以下策略:
- 接近、追踪并包围猎物
- 围追堵截直至猎物停止移动
- 最后发起攻击
这种行为被抽象为数学模型,用于指导算法中个体(“狼”)的更新策略。
3. 算法定义
在 GWO 中,将当前最优的三个解分别定义为 Alpha、Beta 和 Delta,其余解为 Omega。算法通过这三个最优解引导整个种群向最优解逼近。
核心公式如下:
位置更新公式:
(1) 
(2) 
其中:
t表示当前迭代次数A和C是控制探索与开发的系数向量Xp是猎物的位置(即最优解)X是狼的位置
系数计算方式如下:
(3) 
(4) 
其中:
a从 2 线性递减到 0r1和r2是 [0,1] 区间内的随机向量
为了更新每个狼的位置,使用以下公式:
(5) 
(6) 
(7) 
⚠️ 注意:虽然看起来像是取三个最优解的平均值,但由于 C 的存在,实际更新中引入了随机扰动,从而避免陷入局部最优。
算法伪代码如下:
algorithm GreyWolfOptimizer(max_iterations):
// INPUT
// n = the number of wolves in the pack
// max_iterations = the maximum number of iterations for the optimization process
// OUTPUT
// X_alpha = the best found agent
X <- Initialize the grey wolf population with n agents
Initialize a, A, and C
Calculate the fitness of each search agent
X_alpha <- the best search agent
X_beta <- the second best search agent
X_delta <- the third best search agent
t <- 0
while t < max_iterations:
for each search agent in X:
Randomly initialize r1 and r2
Update the position of the current search agent by the equation (7)
Update a, A, and C
Calculate the fitness of all search agents
Update X_alpha, X_beta, and X_delta
t <- t + 1
return X_alpha
✅ 时间复杂度约为 O(k·n),其中 k 是迭代次数,n 是种群数量。
4. 示例演示
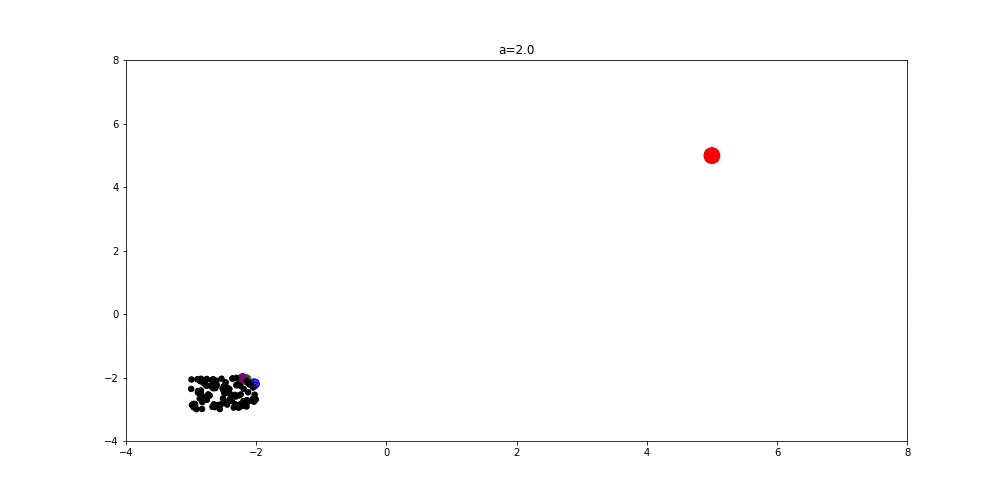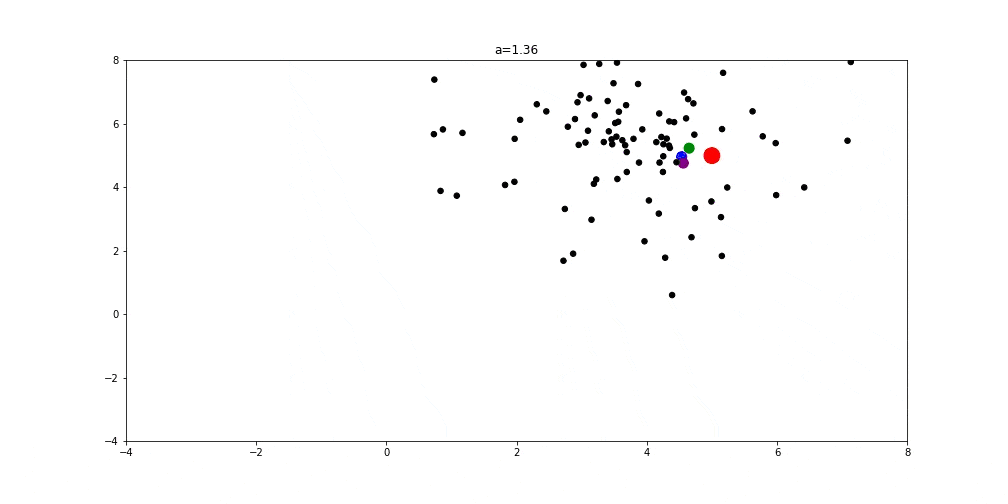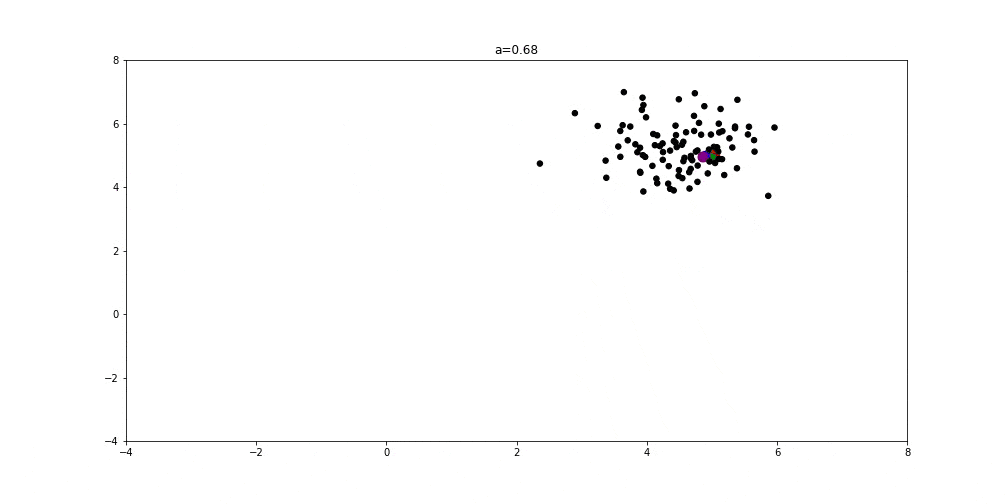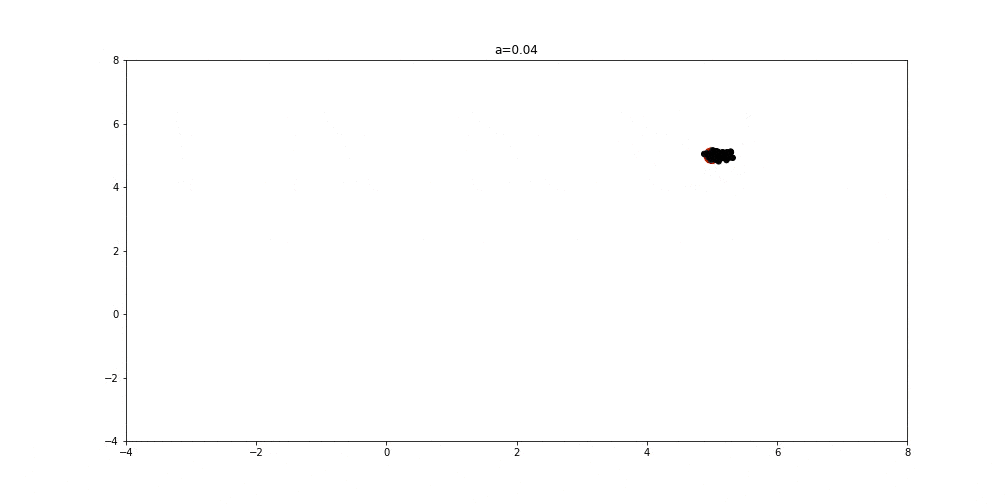
以下图示展示了 GWO 在二维空间中搜索最优解的过程:
- 初始状态:红点为最优解,绿、蓝、紫分别为 Alpha、Beta、Delta,黑点为其他狼(Omega)
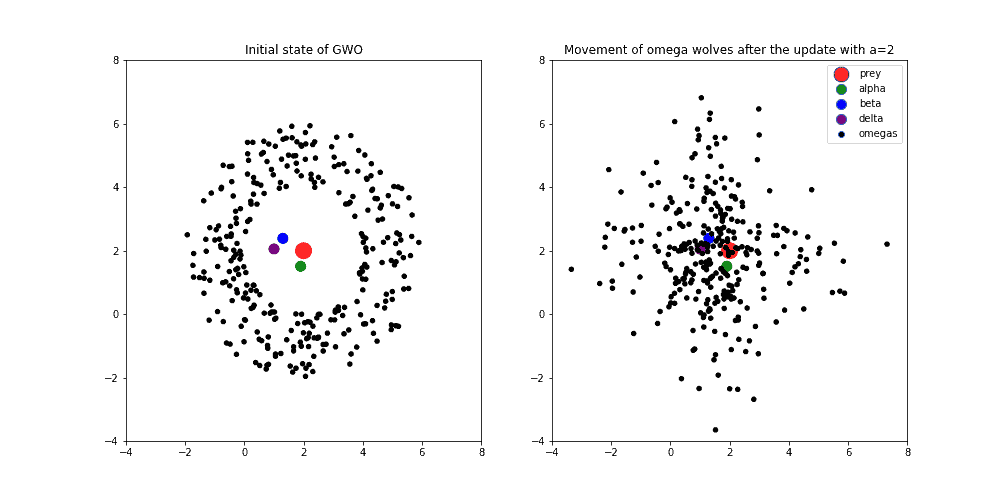
- a = 2 时:算法偏向探索,狼群在解空间中广泛搜索
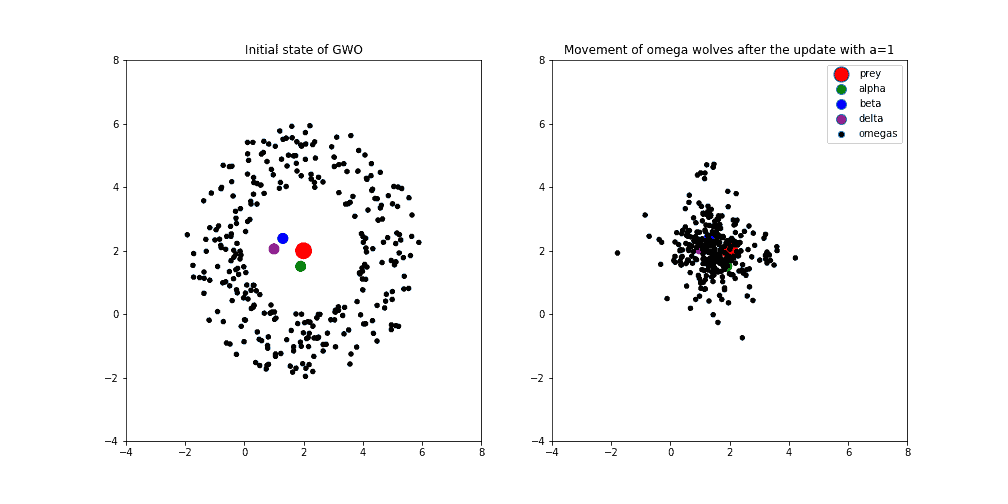
- a = 1 时:探索与开发平衡,狼群开始收敛
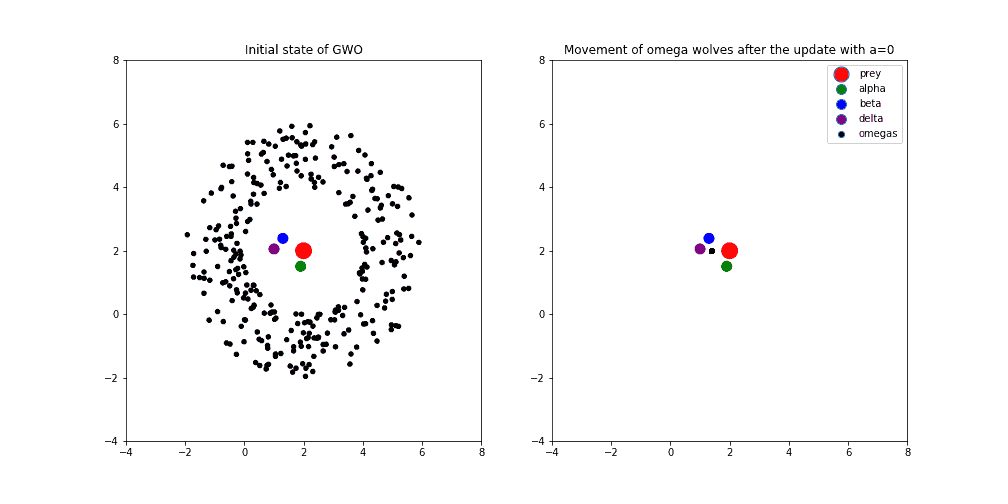
- a = 0 时:算法进入开发阶段,所有狼向最优解靠拢
最终,狼群的收敛过程如下动图所示:
5. 应用场景
GWO 可广泛应用于各种优化问题,尤其在机器学习领域表现良好。
5.1 超参数调优
GWO 可用于机器学习模型的超参数调优。例如优化梯度提升树(Gradient Boosting)的超参数组合:
X = [learning_rate, num_trees, max_depth]
每个狼代表一个参数组合,适应度函数可以是模型在验证集上的准确率。
5.2 特征选择
特征选择是另一个重要应用。假设我们有 30 个特征,直接枚举所有子集组合(2³⁰)是不可行的。
✅ GWO 解决方案:将特征集表示为长度为 30 的二进制向量,1 表示选择该特征,0 表示不选。
X = [1, 0, 1, ..., 0]
适应度函数可以是模型在特定特征子集下的性能指标(如 AUC、准确率等)。
5.3 其他应用场景
GWO 还成功应用于:
- 旅行商问题(TSP)
- 最小生成树问题
- 非线性方程组求解
- 电力系统潮流优化
6. 总结
灰狼优化算法(GWO)是一种简单而有效的元启发式优化方法,具有以下优点:
✅ 模拟自然行为,易于理解
✅ 无需梯度信息,适用范围广
✅ 收敛速度快,稳定性好
⚠️ 缺点:在高维空间中易陷入局部最优,需结合局部搜索或其他策略改进。
在实际应用中,GWO 可用于解决机器学习中的超参数调优、特征选择等关键问题,同时也适用于多种组合优化和工程优化任务。
如果你正在寻找一个直观、高效、可扩展的优化算法,GWO 是一个非常值得尝试的选择。