1. Hash 简介
Hash(哈希)是一种将任意长度的数据输入转换为固定长度输出的机制,输出结果通常被称为哈希值或摘要。现代计算中,从数据库中存储密码到网络通信中的数据签名,Hash 有着广泛的应用。
然而,由于 Hash 的工作原理,哈希碰撞(Hash Collision)是可能发生的。简单来说,就是不同的输入产生了相同的哈希输出。因此,哈希算法在设计时通常会考虑避免碰撞的能力,这被称作弱抗碰撞(Weak Collision Resistance)和强抗碰撞(Strong Collision Resistance)。
本文将带你深入了解这两个概念。我们会先回顾一下 Hash 的基本原理,接着介绍哈希碰撞的机制,再分别解释弱抗碰撞与强抗碰撞的定义与区别,最后结合实际应用场景说明它们的重要性。
2. Hash 的基本原理
简单来说,Hash 是一种将任意数据映射为固定长度编码的过程。整个过程是:将原始数据作为输入传入一个哈希函数,函数对其进行处理后输出一个哈希值。
下图展示了 Hash 的高层次流程:
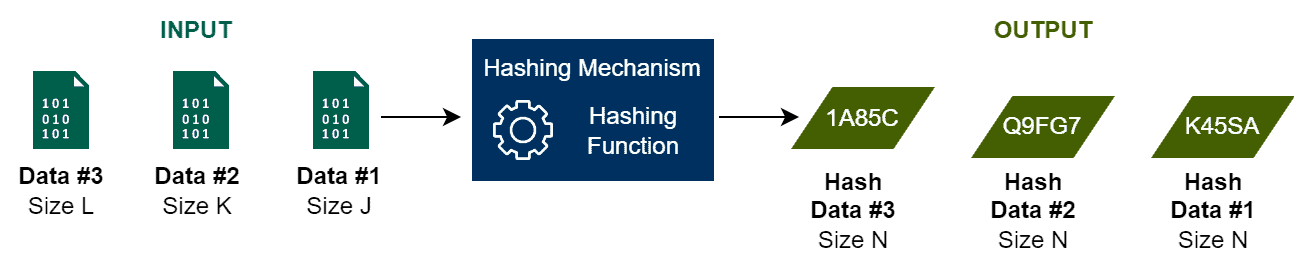
需要注意的是,Hash 函数是单向的,即可以从原始数据生成哈希值,但不能通过哈希值还原原始数据。
Hash 在计算机领域有多种用途,其中比较重要的包括:
- ✅ 密码存储:数据库通常不会直接存储明文密码,而是存储其哈希值。这样即使数据库泄露,攻击者也无法直接获取密码
- ✅ 数据完整性验证:通过公开的哈希算法生成数据的哈希值,接收方可以重新计算哈希并与原值对比,以确认数据是否被篡改
- ✅ 键值结构:如 Java 中的 HashMap、HashSet 等基于哈希表实现的数据结构,通过哈希函数快速定位数据
虽然 Hash 有诸多优点,但也存在一个固有挑战 —— 哈希碰撞。
3. 哈希碰撞(Hash Collision)
当两个不同的输入经过哈希函数处理后得到相同的输出值时,就发生了哈希碰撞。
哈希碰撞是哈希机制的固有特性,而非错误。其根本原因是:哈希函数将无限长度的输入映射到有限长度的输出空间中。因此,理论上总会存在多个输入对应同一个输出的情况。
如下图所示:
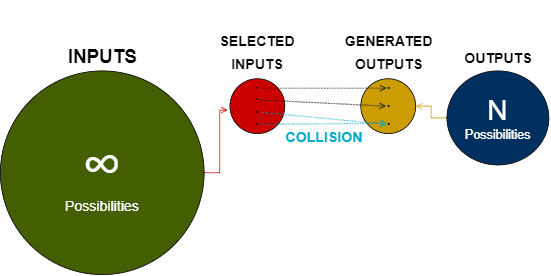
虽然碰撞不可避免,但可以通过一些技术手段缓解,例如:
- 使用链表或开放寻址法处理哈希冲突(常见于哈希表实现)
- 多层哈希机制:当发生碰撞时,使用另一个哈希函数重新计算
不过,与其事后处理,不如事先避免。这就引出了哈希函数设计中的一个关键特性:碰撞抵抗能力。
4. 碰撞抵抗能力
哈希函数的设计目标之一就是尽可能减少碰撞的可能性。具体来说,我们关注两个方面:
- 哈希值的总数是否足够多以支持唯一映射
- 哈希值的分布是否足够均匀,避免某些值被频繁生成
根据应用场景不同,碰撞抵抗可以分为两种类型:
4.1 弱抗碰撞(Weak Collision Resistance)
定义:**给定一个输入 X 和哈希函数 H(),要找到另一个输入 X’,使得 H(X) = H(X’)**,这在计算上是不可行的。
换句话说,如果你知道某个输入 X,想要找到另一个能生成相同哈希值的输入 X’,难度非常大。
这个特性在密码学中非常重要。比如,当用户设置密码时,系统存储的是密码的哈希值。攻击者即使获得了哈希值,也无法轻易找到一个能生成相同哈希值的密码(即原密码或等价密码)。
4.2 强抗碰撞(Strong Collision Resistance)
定义:对于任意两个输入 X 和 Y,H(X) = H(Y) 的概率极低。
与弱抗碰撞不同的是,强抗碰撞并不要求已知其中一个输入。也就是说,即使你不知道任何输入,也很难找到任意两个不同的输入,使得它们的哈希值相同。
这个特性在需要验证数据完整性的场景中尤为重要。比如在数字签名中,签名的是文件的哈希值。如果攻击者能构造出另一个文件,其哈希值与原文件相同,那么数字签名就失去了意义。
5. 实际应用场景
不同场景对碰撞抵抗能力的要求不同:
✅ 弱抗碰撞适用场景
- 密码存储:用户注册时系统会计算密码的哈希值并存储。即使攻击者获取了哈希值,也很难找到另一个密码能生成相同的哈希值(即无法伪造登录)
✅ 强抗碰撞适用场景
- 数据完整性验证:比如下载软件时,网站通常会提供该文件的哈希值。用户下载后重新计算哈希并与网站提供的值对比,确保文件未被篡改
- 数字签名:签名的是文件的哈希值。如果攻击者能构造出另一个文件生成相同的哈希值,签名就不再可信
⚠️ 踩坑提醒:如果你在做数字签名或文件校验,一定要使用具有强抗碰撞能力的哈希算法(如 SHA-256),否则可能会被攻击者利用碰撞漏洞伪造数据。
6. 总结
哈希是一种基础而强大的工具,在现代软件系统中无处不在。但其本质决定了哈希碰撞不可避免。因此,我们在选择和设计哈希算法时,必须关注其碰撞抵抗能力。
- 弱抗碰撞:已知一个输入,难以找到另一个输入生成相同哈希值
- 强抗碰撞:任意两个输入生成相同哈希值的概率极低
在实际开发中,应根据应用场景选择合适的哈希算法。例如:
- 密码存储 → 选择支持弱抗碰撞的算法(如 bcrypt、scrypt、PBKDF2)
- 数字签名 / 文件校验 → 必须选择支持强抗碰撞的算法(如 SHA-256)
选择合适的哈希算法,是保障系统安全性和数据完整性的关键一步。