1. 概述
在信息安全领域,哈希(Hashing)和加密(Encryption)是两个最基础且关键的操作。它们都能将原始数据转换为另一种形式,但其工作机制和适用场景存在本质区别。
简单来说:
- 哈希:将任意长度的数据映射为固定长度的摘要值,不可逆
- 加密:将明文转换为密文,通过密钥可还原为原始数据,是可逆过程
本文将深入解析两者的原理、差异以及在实际开发中的应用。
2. 哈希(Hashing)
2.1 什么是哈希?
哈希是一种将任意长度的数据通过哈希函数转换为固定长度值的过程。这个值也被称为哈希值、摘要、校验和等。
常见用途包括:
- ✅ 验证数据完整性:例如文件传输时,发送方提供哈希值,接收方重新计算进行比对
- ✅ 哈希表实现:作为数据结构中键值对的索引
2.2 哈希函数的特点
- 单向性:只能从原始数据计算出哈希值,无法反向推导出原始数据
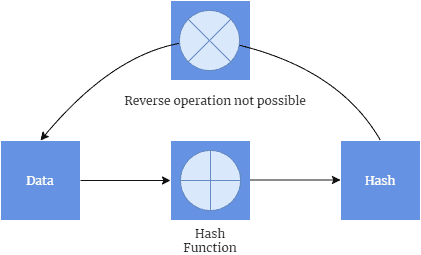
- 确定性:相同输入始终输出相同哈希值
- 均匀分布:哈希值在输出范围内分布均匀,减少冲突
- 抗碰撞性:尽量避免不同输入产生相同哈希值(即“哈希碰撞”)
2.3 常见哈希算法示例
- 除法哈希(Division Hashing):使用
h(k) = k mod m,其中 m 通常为质数 - 恒等哈希(Identity Hashing):数据本身即为哈希值,适合小数据类型如 Java 中的 Integer、Float
⚠️ 缺点:
- 除法运算在现代 CPU 上效率较低
- 相似输入可能生成相同哈希值,导致冲突
2.4 哈希冲突处理
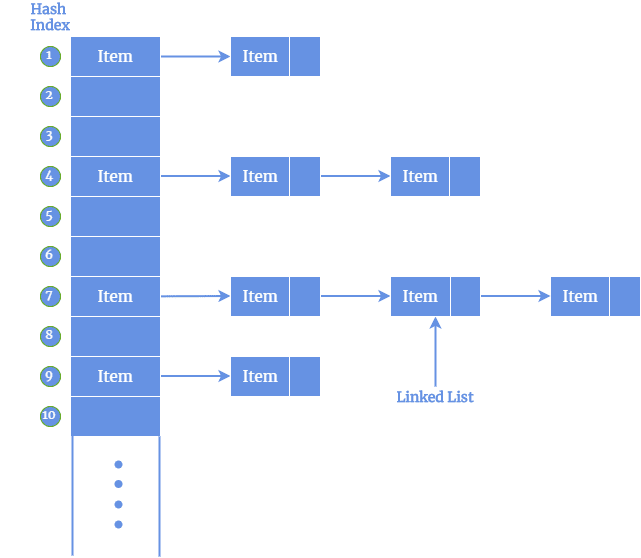
开放寻址(Open Hashing)
使用链表处理冲突,每个哈希桶存储多个值:
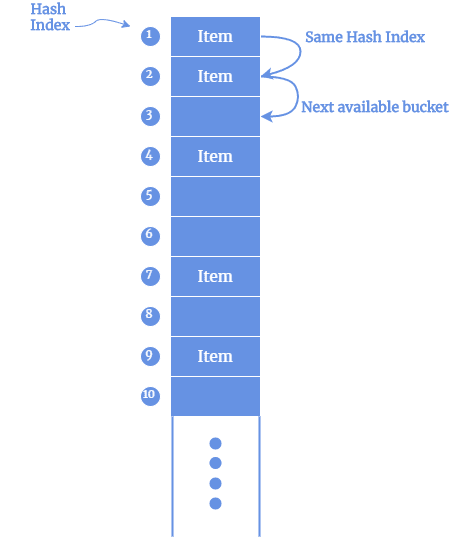
封闭寻址(Closed Hashing)
不使用额外结构,通过探测下一个空位解决冲突:
3. 加密(Encryption)
3.1 什么是加密?
加密是将明文(Plaintext)通过算法转换为密文(Ciphertext)的过程。只有拥有正确密钥的人才能解密还原原始数据。
3.2 加密的目的
- ✅ 数据保密性:防止未经授权的人读取数据
- ✅ 数据完整性:确保数据在传输中未被篡改
- ✅ 身份验证:确认消息来源
- ✅ 不可否认性:发送者不能否认已发送的数据
3.3 加密工作原理
加密 = 数据 + 加密算法 + 加密密钥 → 密文
解密 = 密文 + 解密算法 + 解密密钥 → 明文
根据密钥类型,加密分为两类:
3.4 对称加密(Symmetric Encryption)
- 使用相同密钥进行加密和解密
- ✅ 优点:速度快
- ❌ 缺点:密钥需安全传输,否则容易被窃取
常见算法:AES、DES、3DES
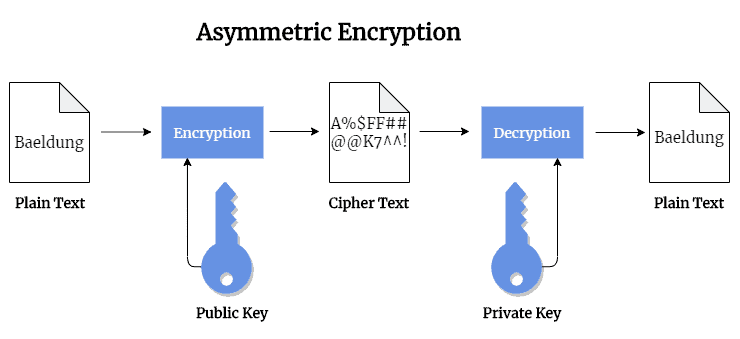
3.5 非对称加密(Asymmetric Encryption)
- 使用一对密钥:公钥加密,私钥解密
- ✅ 优点:无需共享私钥,安全性更高
- ❌ 缺点:计算开销大,速度慢
常见算法:RSA、ECC、DSA
RSA 示例图:
3.6 加密面临的挑战
- ✅ 暴力破解(Brute Force Attack):尝试所有可能密钥,直到找到正确密钥
- ✅ 侧信道攻击(Side-channel Attack):利用系统实现缺陷(如执行时间、功耗等)推测密钥
⚠️ 提示:即使是强加密算法,若实现不当,也可能存在漏洞。开发中应使用标准库而非自行实现加密逻辑。
4. 总结
| 特性 | 哈希(Hashing) | 加密(Encryption) |
|---|---|---|
| 是否可逆 | ❌ 不可逆 | ✅ 可逆 |
| 输出长度 | 固定长度 | 通常与输入长度相关 |
| 用途 | 数据完整性校验、哈希表索引 | 数据保密、身份验证 |
| 常见算法 | SHA-256、MD5、CRC32 | AES、RSA、DES |
| 安全性依赖 | 抗碰撞性、不可逆性 | 密钥长度、算法强度 |
在实际开发中:
- ✅ 使用哈希保护密码(如 BCrypt、PBKDF2)
- ✅ 使用加密保护敏感通信(如 HTTPS 使用 TLS,内部加密使用 AES)
- ⚠️ 切勿使用 MD5、SHA-1 等已被证明不安全的算法进行密码存储或签名验证
理解哈希与加密的区别,有助于我们在系统设计中做出更安全、合理的决策。