1. 概述
在训练和评估机器学习模型(包括神经网络)时,我们通常会使用损失(代价)函数来衡量模型的性能。选择合适的损失函数对任务的成功至关重要,而 Hinge Loss 和 Logistic Loss 是两种广泛使用的分类损失函数。
本文将深入分析它们的定义、数学表达、特性及其适用场景,并对比它们的优劣。
2. Hinge Loss
Hinge Loss 常用于二分类问题,尤其在支持向量机(Support Vector Machines, SVM)中被广泛使用。它的核心思想是通过最大化类别之间的边界(margin)来提高分类的鲁棒性。
2.1. 定义
假设:
- 样本的真实标签为 $ y \in {-1, +1} $
- 模型预测值为 $ f_w(x) = w^T x $
则 Hinge Loss 定义如下:
$$ L(x, y, w) = \max(1 - y w^T x, 0) $$
其中 $ m = y w^T x $,表示预测值与真实标签的乘积。
当 $ m \geq 1 $ 时,损失为 0,表示样本被正确分类且远离边界。
当 $ 0 \leq m < 1 $ 时,虽然分类正确,但由于靠近边界,仍会受到惩罚。
当 $ m < 0 $,说明分类错误,损失随 $ m $ 减小而线性增长。
下面是 Hinge Loss 的图形表示:
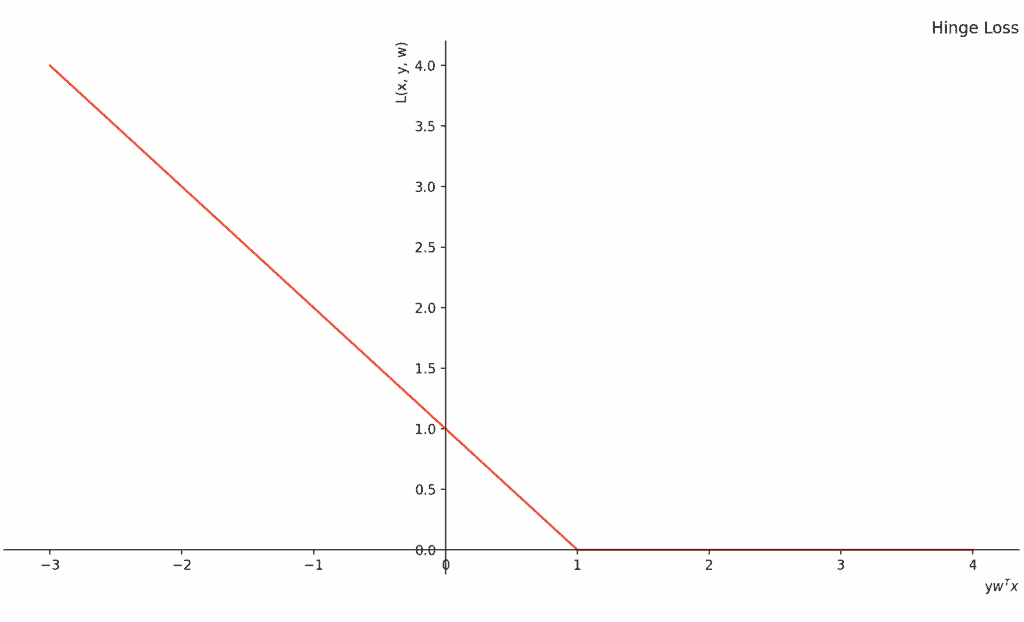
2.2. 特性
✅ 凸函数:便于使用梯度下降等凸优化方法找到全局最优解。
✅ 稀疏性:只有靠近边界的样本(支持向量)参与模型训练,其余样本不起作用。
❌ 不可导:在 $ m=1 $ 处不可导,限制了某些优化算法的使用(如 LBFGS)。
⚠️ 适用于小规模、需要最大化边界的场景。
3. Logistic Loss
Logistic Loss 又称交叉熵损失(Cross-Entropy Loss)或 Log Loss,常用于逻辑回归和深度学习分类任务。它通过最小化损失函数来实现最大似然估计。
3.1. 定义
同样假设:
- $ y \in {-1, +1} $
- $ f_w(x) = w^T x $
Logistic Loss 的数学定义为:
$$ L(x, y, w) = \ln(1 + e^{-y w^T x}) $$
该损失函数是连续且可导的,对所有样本都敏感。
下面是 Logistic Loss 的图形表示:
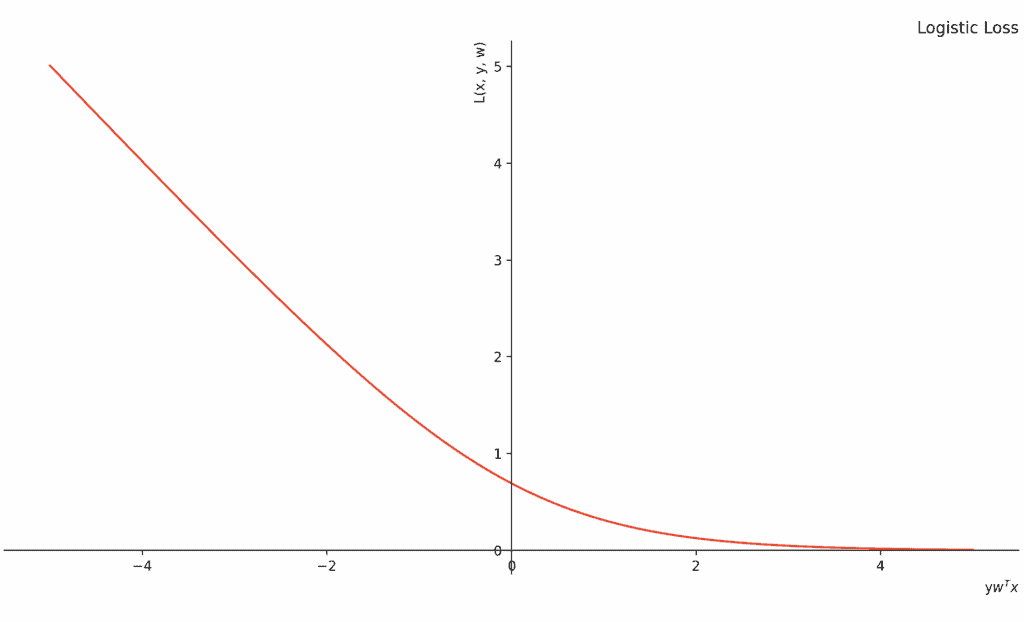
3.2. 特性
✅ 可导性:适合大规模优化问题,能使用 LBFGS、Adam 等优化算法。
✅ 概率建模:输出可解释为类别概率,具备良好的校准能力(calibration)。
❌ 不最大化边界:对所有样本敏感,可能受到噪声或异常值影响。
⚠️ 适用于需要概率输出或大规模数据训练的场景。
4. Hinge Loss 与 Logistic Loss 的对比分析
| 对比维度 | Hinge Loss | Logistic Loss |
|---|---|---|
| 凸性 | ✅ 是凸函数 | ✅ 是凸函数 |
| 可导性 | ❌ 在 m=1 不可导 | ✅ 全域可导 |
| 稀疏性 | ✅ 只使用支持向量 | ❌ 所有样本都参与 |
| 计算效率 | ✅ 更低 | ❌ 更高 |
| 分类准确率 | ✅ 通常更高 | ❌ 可能受异常值影响 |
| 概率输出 | ❌ 无 | ✅ 有 |
| 边界最大化能力 | ✅ 是 | ❌ 否 |
✅ Hinge Loss 的优势
- 更适合需要最大化分类边界的问题
- 计算更简单,收敛更快
- 稀疏性强,适合内存敏感场景
✅ Logistic Loss 的优势
- 支持概率输出,适合需要置信度的场景
- 全域可导,适合大规模优化
- 更适合逻辑回归、神经网络等模型
5. 总结
| 特性 | Hinge Loss | Logistic Loss |
|---|---|---|
| 凸性 | ✅ | ✅ |
| 可导性 | ❌ | ✅ |
| 稀疏性 | ✅ | ❌ |
| 计算成本 | ✅ 低 | ❌ 高 |
| 分类准确率潜力 | ✅ 高 | ❌ 相对低 |
| 是否支持概率输出 | ❌ | ✅ |
6. 结论
Hinge Loss 和 Logistic Loss 各有优劣,选择时应根据任务需求权衡:
- 若任务注重分类边界最大化、模型稀疏性、计算效率,建议使用 Hinge Loss
- 若任务需要概率输出、模型校准、大规模优化,建议使用 Logistic Loss
两者都具备凸性,便于优化,但在不同场景下的表现差异显著。理解它们的数学定义和特性,有助于我们在实际项目中做出更合理的损失函数选择。