1. Introduction
Programming languages were created to allow developers to write human-readable source code. However, computers work with machine code, which people can hardly write or read. Thus, compilers translate the programming language’s source code to machine code dedicated to a specific machine.
In this article, we’ll analyze the compilation process phases. Then, we’ll see the differences between compilers and interpreters. Finally, we’ll introduce examples of a few compilers of modern programming languages.
2. Compilation Phases
As we already mentioned, the compilation process converts high-level source code to a low-level machine code that can be executed by the target machine. Moreover, an essential role of compilers is to inform the developer about errors committed, especially syntax-related ones.
The compilation process consists of several phases:
- Lexical analysis
- Syntax analysis
- Semantic analysis
- Intermediate code generation
- Optimization
- Code generation
In this section, we’ll discuss each phase in detail.
2.1. Lexical Analysis
The first stage of the compilation process is lexical analysis. During this phase, the compiler splits source code into fragments called lexemes. A lexeme is an abstract unit of a specific language’s lexical system. Let’s analyze a simple example:
String greeting = "hello";
In the above statement, we have five lexemes:
- String
- greeting
- =
- “hello”
- ;
After splitting code into lexemes, a sequence of tokens is created. The sequence of tokens is a final product of lexical analysis. Thus, lexical analysis is also often called tokenization. A token is an object that describes a lexeme. It gives information about the lexeme’s purpose, such as whether it’s a keyword, variable name, or string literal. Moreover, it stores the lexeme’s source code location data.
2.2. Syntax Analysis
During syntax analysis, the compiler uses a sequence of tokens generated in the first stage. Tokens are used to create a structure called an abstract syntax tree (AST), which is a tree that represents the logical structure of a program.
In this phase, the compiler checks a grammatic structure of the source code and its syntax correctness. Meanwhile, any syntax errors result in a compilation error, and the compiler informs the developer about them.
In brief, syntax analysis is responsible for two tasks:
- It checks source code for any syntax error.
- It generates an abstract syntax tree that the next stage uses.
2.3. Semantic Analysis
In this stage, the compiler uses an abstract syntax tree to detect any semantic errors, for example:
- assigning the wrong type to a variable
- declaring variables with the same name in the same scope
- using an undeclared variable
- using language’s keyword as a variable name
Semantic analysis can be divided into three steps:
- Type checking – inspects type match in assignment statements, arithmetic operations, functions, and method calls.
- Flow control checking – investigates if flow control structures are used correctly and if classes and objects are correctly accessed.
- Label checking – validates the use of labels and identifiers.
To achieve all the above goals, during semantic analysis, the compiler makes a complete traversal of the abstract syntax tree. Semantic analysis finally produces an annotated AST that describes the values of its attributes.
2.4. Intermediate Code Generation
During the compilation process, a compiler can generate one or more intermediate code forms.
“After syntax and semantic analysis of the source program, many compilers generate an explicit low-level or machine-like intermediate representation, which we can think of as a program for an abstract machine. This intermediate representation should have two important properties: it should be easy to produce and it should be easy to translate into the target machine.” – Compilers. Principles, Techniques, & Tools. Second Edition. Alfred V. Aho. Columbia University. Monica S. Lam. Stanford University. Ravi Sethi. Avaya.
Intermediate code is machine-independent. Thus, there is no need for unique compilers for every different machine**.** Besides, optimization techniques are easier to apply to intermediate code than machine code. Intermediate code has two forms of representation:
- High-Level – similar to the source language. In this form, we can easily boost the performance of source code. However, it’s less preferred for enhancing the performance of the target machine.
- Low-Level – close to the machine’s machine code. It’s preferred for making machine-related optimizations.
2.5. Optimization
In the optimization phase, the compiler uses a variety of ways to enhance the efficiency of the code. Certainly, the optimization process should follow three important rules:
- The resulting code can’t change the original meaning of the program.
- Optimization should focus on consuming fewer resources and speeding up the operation of the software.
- The optimization process shouldn’t significantly impact the overall time of compilation.
Let’s see a few examples of optimization techniques:
- Function inlining – replacing the function call with its body.
- Dead code elimination – compiler gets rid of code that is never executed, or if executed, its returned result isn’t used.
- Loop fusion – executing, in one loop, operations from the adjacent loops that have the same iteration conditions.
- Instruction combining – instructions realizing similar operations are combined into one; for example, x = x + 10; x = x – 7; could be replaced with x = x + 3;
2.6. Code Generation
Finally, the compiler converts the optimized intermediate code to the machine code dedicated to the target machine. The final code should have the same meaning as source code and be efficient in terms of memory and CPU resource usage. Furthermore, the code generation process must also be efficient.
2.7. Practical Example
In the below flowchart, we can see an example of the compilation process of a simple statement.
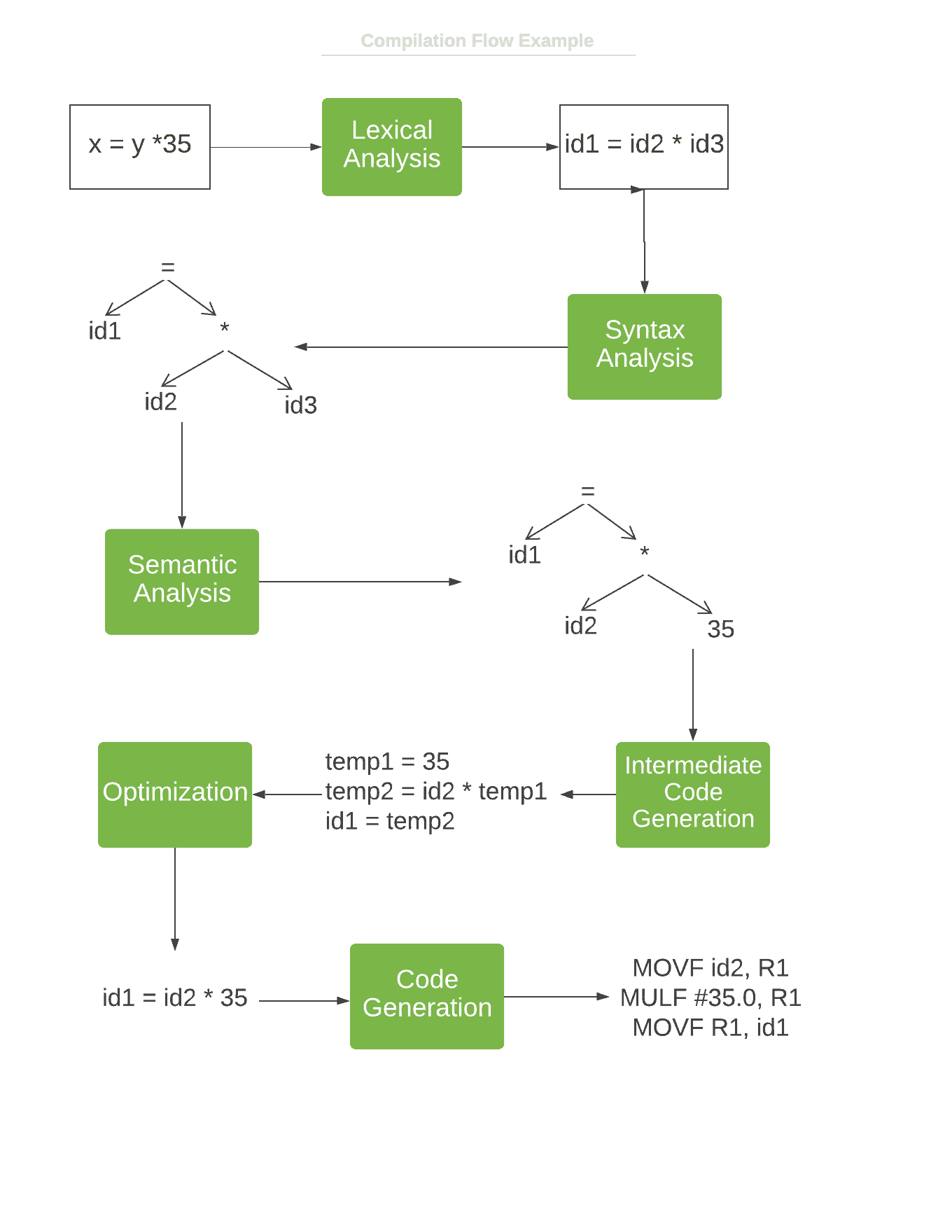
3. Compiler vs. Interpreter
As we already know, the compiler converts high-level source code to low-level code. Then, the target machine executes low-level code. On the other hand, the interpreter analyzes and executes source code directly. An interpreter usually uses one of several techniques:
- Analyzes (parses) the source code and executes it directly.
- Converts high-level source code into intermediate code and executes it immediately.
- Explicitly executes stored precompiled code generated by a compiler. In this case, the compiler belongs to the interpreter system.
Let’s see a brief comparison between an interpreter and a compiler:
COMPILER:
INTERPRETER:
1. Converts the code but doesn’t execute it.
1. Executes code directly.
2. Implementing a compiler requires knowledge about the target machine.
2. No need for knowledge about the target machine, since an interpreter executes the code.
3. Each instruction is translated only once.
3. The same instruction can be analyzed multiple times.
4. The compiled program is faster to run.
4. Interpreted programs are slower to run, but take less time to interpret than to compile and run.
5. Consumes more memory due to intermediate code generation.
5. Usually executes input code directly, thus it consumes less memory.
6. Compiled language examples: Java, C++, Swift, C#.
6. Interpreted language examples: Ruby, Lisp, PHP, PowerShell.
4. Compiler Examples
4.1. Javac
In Java, source code is first compiled to the bytecode by the javac compiler. Then, a Java Virtual Machine (JVM) interprets and executes bytecode. So, javac is an excellent example of a compiler that belongs to an interpreter system. Such a system makes Java portable and multiplatform.
Moreover, there are other languages like Kotlin or Scala that are also compiled to bytecode, but these use unique compilers. Thus, the JVM can execute code that was originally written using different technologies.
4.2. Mono
Mono is a toolset, including a C# programming language compiler, for executing software dedicated to the .NET Platform. It was created to allow .NET applications to run on different platforms. Moreover, an important goal was to give developers working on Linux a better environment and tools for working with the .NET platform.
A compiler converts C# source code into an intermediate bytecode. After that, the virtual machine executes it. Both the C# compiler and virtual machine belong to the Mono toolset.
4.3. GNU Compiler Collection
The GNU Compiler Collection (GCC) is a set of open-source compilers that belong to the GNU Project. These compilers could run on different hardware and software platforms. Therefore, they can generate machine code for various architectures and operating systems.
During compilation, GCC is responsible for processing arguments, calling the compiler for the specific programming language, running the assembler program, and eventually, running a linker to produce an executable binary.
GCC consists of compilers for several programming languages:
- C (gcc)
- C++ (g++)
- Objective-C (gobjc)
- Fortran (g77 and GFortran)
- Java (gcj)
- Ada (gnat)
5. Conclusion
In this article, we described a compiler’s role. Further, we went through all phases of the compilation process. Then we discussed differences between a compiler and interpreter. Finally, we mentioned some real-world compiler examples.