1. 概述
本文将介绍 Inception 网络的基本概念和结构。首先我们会讲解其设计动机以及名称的由来,接着深入剖析其核心模块,最后会展示两种不同版本的 Inception 网络整体架构。
2. 设计动机
Inception 网络是一种深度神经网络,由多个重复的 Inception 模块堆叠而成。每个模块的输出作为下一个模块的输入。
其设计动机主要基于两个理念:
✅ 深度网络应足够深:为了应对复杂任务,网络需要具备较多的层数和每层较多的神经元,类似 Residual Network 的结构。
✅ 特征应具有多尺度性:人类观察世界是多尺度的,先识别不同尺度的视觉模式,再整合成高层次的理解。因此,神经网络也应具备多尺度特征提取能力。
3. 名称由来
Inception 这个名字来源于克里斯托弗·诺兰执导的电影《盗梦空间》(Inception)。电影中展现了“梦中梦”的概念,并催生了如下这张广为流传的梗图:

网络设计者引用了这张图,因为它启发了他们:就像电影中“梦中梦”一样,Inception 网络中也实现了“网络中网络”的结构。
4. 核心模块
要理解 Inception 网络,我们需要了解其核心组件。
4.1 1×1 卷积
1×1 卷积的核心作用是在通道维度上进行降维,从而减少输入数据的维度。这样可以在不显著增加参数量的前提下加深网络,避免过拟合。
在 1×1 卷积中,每个像素点在通道方向上与卷积核进行运算。输出的宽和高保持不变,但通道数发生变化。
如下图所示,输入维度为 (64, 64, 192),输出变为 (64, 64, 1),即通道数减少:
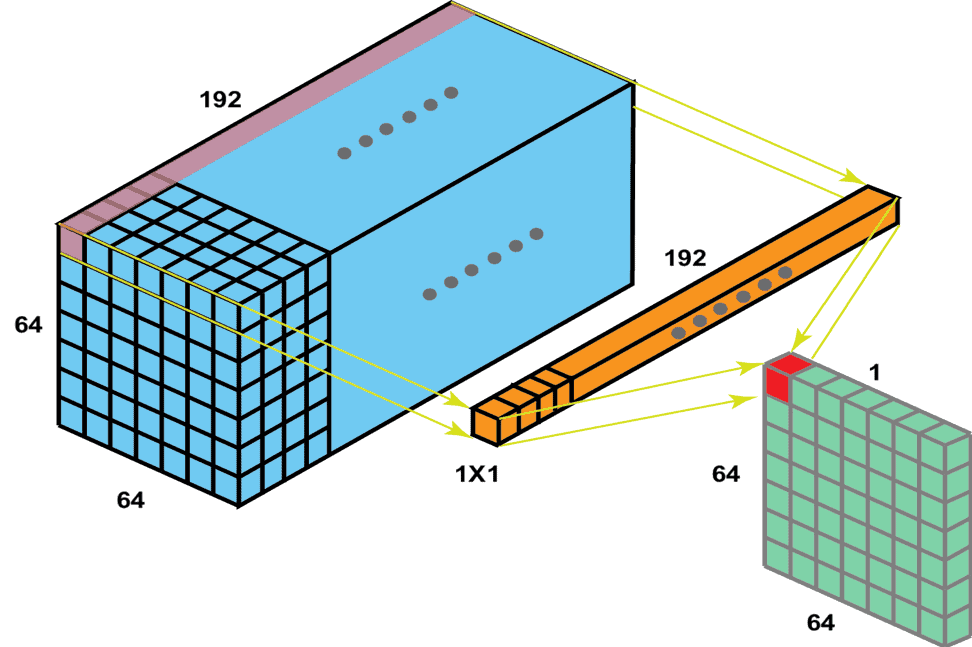
1×1 卷积还能帮助网络学习跨通道的特征。
4.2 3×3 和 5×5 卷积
3×3 和 5×5 卷积用于提取不同空间尺度上的特征。
3×3 卷积适合提取较小尺度的局部特征,5×5 卷积则能捕捉更大范围的特征信息,模拟人眼多尺度感知的能力。
5. 整体架构
Inception 网络整体由多个 Inception 模块组成,通常还包括 Max Pooling 层和 Concatenate 层,用于融合不同路径提取的特征。
下面我们介绍两种 Inception 架构设计:一种是 Naive 版本,另一种是优化后的 Original 版本。
5.1 Naive Inception
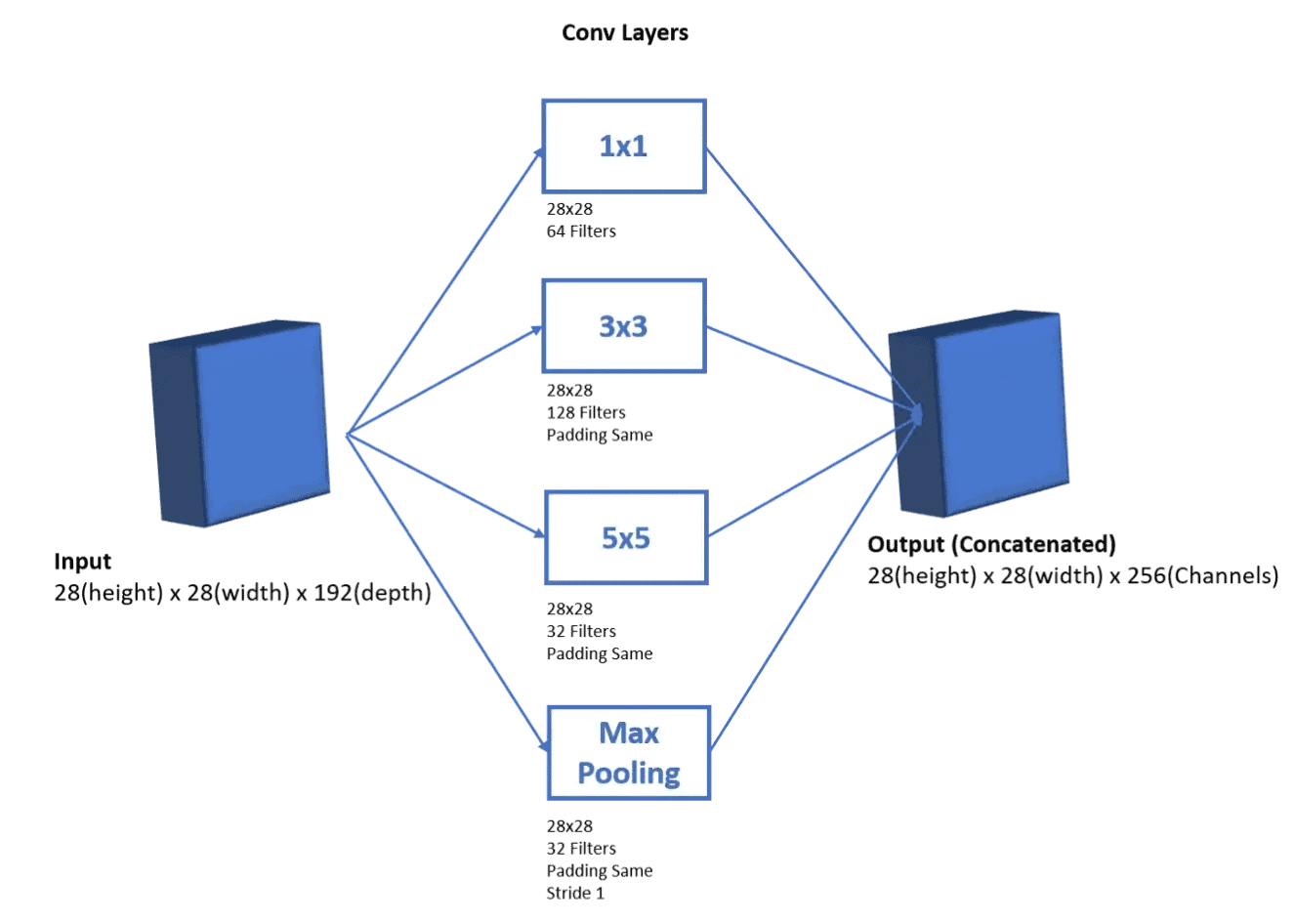
Naive Inception 的设计思路是:对输入分别应用不同卷积操作,再将输出在通道维度上拼接。
为保证输出尺寸一致,需要对每个卷积层使用 same padding,以确保输出的宽高一致。
如下图所示,输入为 (28, 28, 192),输出为 (28, 28, channels),其中通道数是各分支输出通道之和:
5.2 Optimized Inception
Naive Inception 的缺点是计算量大,尤其是在 3×3 和 5×5 卷积层中。
解决方案是引入 1×1 卷积进行降维,从而降低后续卷积操作的计算成本。
如下图所示,在 3×3 和 5×5 卷积之前加入 1×1 卷积,先对输入进行通道压缩,再进行卷积操作:
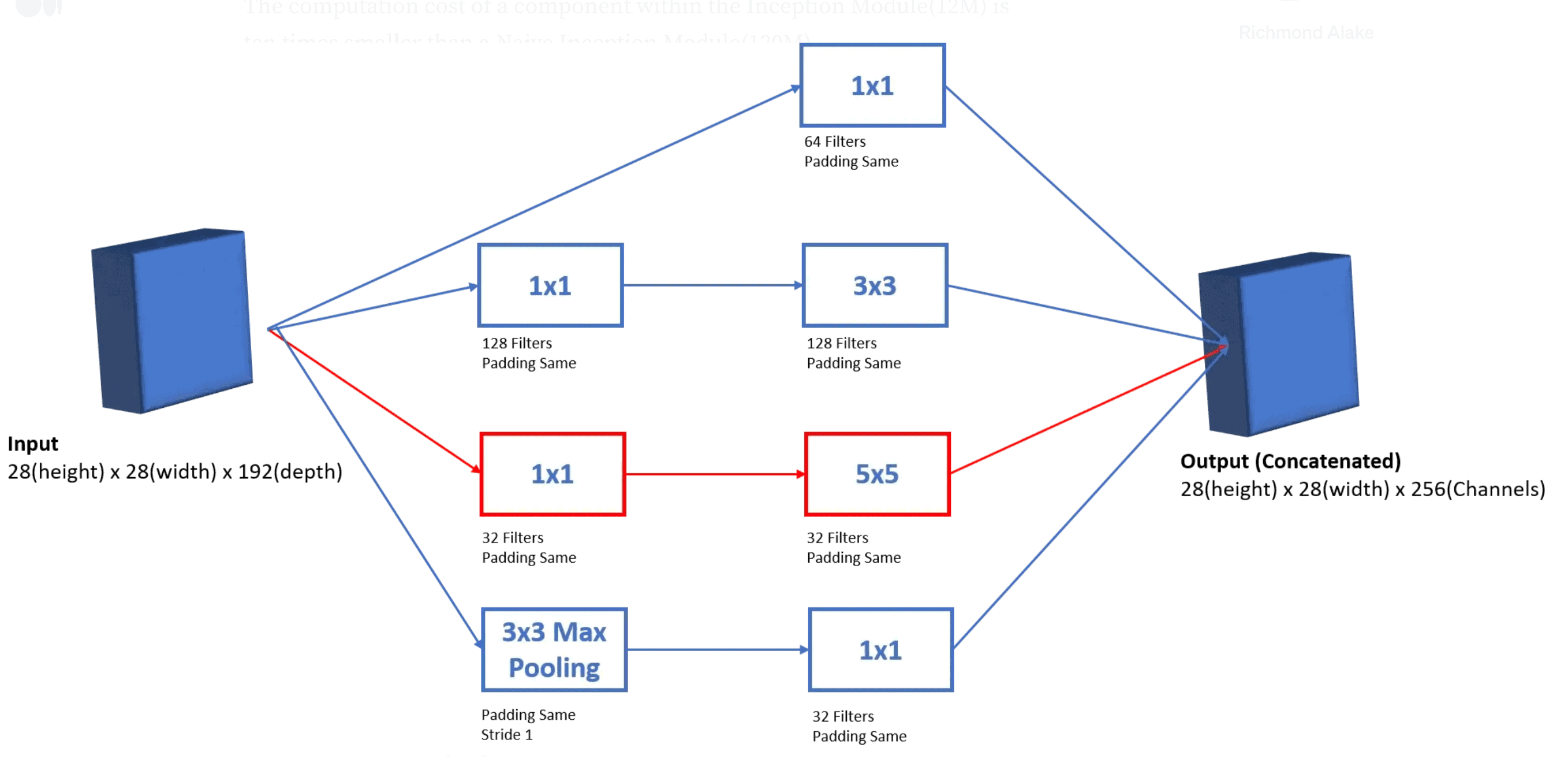
这种结构在减少计算量的同时保持了模型的表达能力,是 Inception 网络的重要优化手段。
6. 小结
本文我们介绍了 Inception 网络的基本概念和结构:
- ✅ 其设计灵感来自“梦中梦”的概念,体现“网络中网络”的思想
- ✅ 通过 1×1 卷积降维,提升计算效率
- ✅ 使用 3×3 和 5×5 卷积提取多尺度空间特征
- ✅ 提出了 Naive 和 Optimized 两种 Inception 架构版本
Inception 网络是深度学习中非常经典的设计之一,后续多个版本(如 Inception v2, v3, v4)在该基础上进行了进一步优化。掌握其核心思想对理解现代卷积神经网络架构非常有帮助。