1. Introduction
In this tutorial, we’ll cover recursive and iterative algorithms for enumerating all k-combinations of a set.
2. Combinations
A combination is a subset of a set. So, in this problem, we have a set  with
with  elements and want to list all its subsets with exactly
elements and want to list all its subsets with exactly  items.
items.
Unlike permutations, the order in which we choose the individual elements doesn’t matter. Instead, we’re interested in whether a particular element is in a combination.
For example, we don’t care about the order in which we selected five cards out of 52; we only care about which cards are in hand.
3. Recursive Algorithm 1: Partitioning by Elements in the Original Set
Recursive algorithms partition the problem into smaller sub-problems of the same type and combine their solutions to get the solution to the original problem. We differentiate between recursive algorithms based on their partitioning schemes.
We’ll discuss two approaches. The first partitions the problem by the elements in the original set  , whereas the other partitions by the selected elements.
, whereas the other partitions by the selected elements.
3.1. Idea
We can partition the task by inspecting the set’s elements individually. For each item in the set, we can either include it in the selection or not.
So, we traverse the set in a predetermined order. If we include the first item ( ), we need to choose
), we need to choose  elements from the remaining
elements from the remaining  items. On the other hand, if we discard , we need to select
items. On the other hand, if we discard , we need to select  elements out of the remaining items.
elements out of the remaining items.
To solve the smaller problems (the selection of  and elements out of
and elements out of  ), we apply the same partitioning scheme:
), we apply the same partitioning scheme:
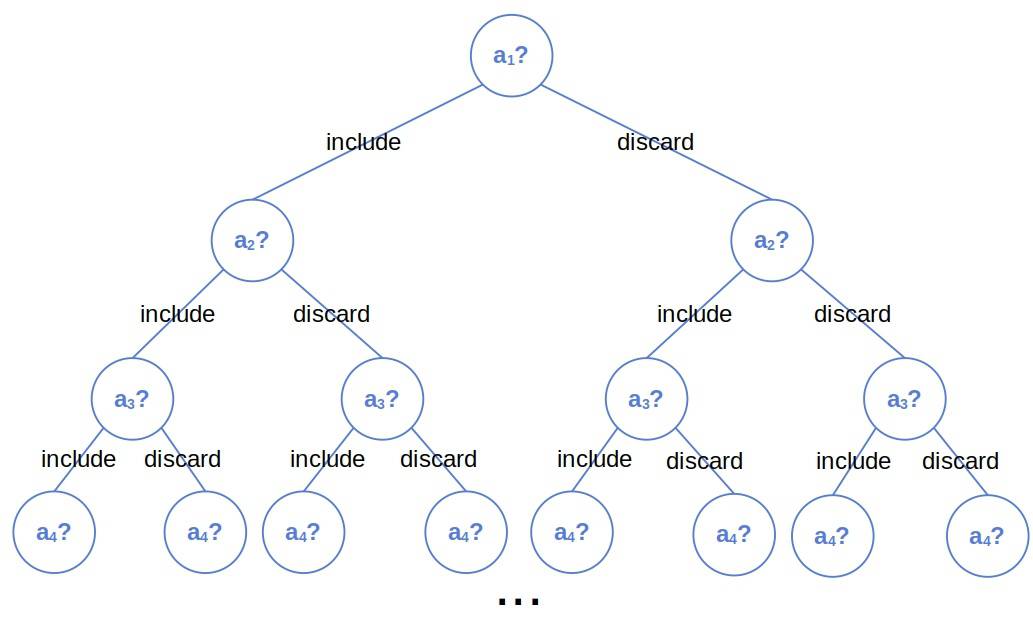
We can enumerate all -combinations by traversing the tree and collecting its leaves. At each step, we keep track of the elements in the currently active combination (which corresponds to the path from the root to the current node). Going down an edge, we remember the decision about including the node’s element; going up, we reverse the decision associated with the edge.
3.2. Pseudocode
Here’s the pseudocode:
algorithm FindAllKCombinations(S, x, k):
// INPUT
// S = {a_1, a_2, ..., a_n}
// k = number of elements to select (0 <= k <= n)
// OUTPUT
// All k-combinations of S
// x is the currently active combination
if k > |S|:
// No more elements are available, so this branch is a dead end
return
if |x| = k:
// We made a combination
Output x
else:
// Let a be the first element of S.
// First, we explore the sub-tree with a included.
FindAllKCombinations(S \ {a}, x + [a], k-1)
// Then, we explore the sub-tree with a not included.
Remove a from x
FindAllKCombinations(S \ {a}, x, k)
![x + [a]](/wp-content/ql-cache/quicklatex.com-3e8270ae64c2f0a2c6f476152e51a6fe_l3.svg "Rendered by QuickLaTeX.com") means appending
means appending  to
to  .
.
The chosen order of elements determines the order of combinations at the output. Usually, we specify  as an iterable data structure and call the order lexicographic. We denote it with the “less than” symbol:
as an iterable data structure and call the order lexicographic. We denote it with the “less than” symbol:  .
.
3.3. Complexity and Issues
The time complexity of this approach is  . This is so because there are nested decisions about elements, and each decision can have two outcomes. Therefore, this approach is inefficient if the input set is large.
. This is so because there are nested decisions about elements, and each decision can have two outcomes. Therefore, this approach is inefficient if the input set is large.
Furthermore, it takes  stack space. So, we may get a stack overflow if is too big.
stack space. So, we may get a stack overflow if is too big.
4. Recursive Algorithm 2: Partitioning by Elements in the Combination
Instead of tracking the elements in the input set, we can partition the problem by tracking the items in the selection.
4.1. Idea
Let’s assume we want to output ordered combinations. So, a -combination should satisfy ![x[1] < x[2] < \ldots < x[k]](/wp-content/ql-cache/quicklatex.com-277b7851f5d7feaaf8d1d77fb94b7ab8_l3.svg "Rendered by QuickLaTeX.com") , where
, where ![x[j]](/wp-content/ql-cache/quicklatex.com-28ba9658ecf906b3c7270d0544dca898_l3.svg "Rendered by QuickLaTeX.com") is the
is the  th element of .
th element of .
To do so, the first item in a -combination must come from ![[a_1, a_2, \ldots, a_{n-k+1}]](/wp-content/ql-cache/quicklatex.com-5f4dafeb41405d64de748394d23b1148_l3.svg "Rendered by QuickLaTeX.com") . Otherwise, we can’t make an ordered combination.
. Otherwise, we can’t make an ordered combination.
If we choose ![\boldsymbol{a_j \in [a_1, a_2, \ldots, a_{n-k+1}]}](/wp-content/ql-cache/quicklatex.com-6ee9a2015dc22b726b30ade47f778d0d_l3.svg "Rendered by QuickLaTeX.com") as the first element, we can get an ordered combination only if we select the remaining items from those to the right of
as the first element, we can get an ordered combination only if we select the remaining items from those to the right of  . In doing so, the first element in the
. In doing so, the first element in the  -combination must be from those to the left of
-combination must be from those to the left of  (or constructing a combination won’t be feasible). So, we iterate over the window
(or constructing a combination won’t be feasible). So, we iterate over the window ![[a_{j+1}, a_{j+2}, \ldots, a_{n-k+2}]](/wp-content/ql-cache/quicklatex.com-e63ee2a00631be3a3edd54f36d369076_l3.svg "Rendered by QuickLaTeX.com") and repeat the process.
and repeat the process.
4.2. Pseudocode
Here’s the pseudocode:
algorithm FindKCombinations(S, x, k):
// INPUT
// S = [a[j], a[j+1], ..., a[n]], a subset of {a_1, a_2, ..., a_n}
// x = the currently active combination
// k = the number of elements to select (0 ≤ k ≤ n)
// OUTPUT
// All k-combinations of S
if |x| = k:
// We have a combination
Output x
else:
m <- min { n, n - (k - |x|) + 1 }
for i <- j + 1, j + 2, ..., m:
FindKCombinations([a[i+1], a[i+2], ..., a[n]], x + [a[j]], k)
// Going up the recursion tree, we explore the combinations without a[j]
In the above pseudocode, the for loop chooses the next item. Then, it calls the algorithm recursively for each position in the active window. We stop when the required number of items have been selected, output a combination, and go up the recursion tree to find other combinations.
If the right end of the current window goes beyond the array, we need to cap it. That’s why we have the step  .
.
4.3. Complexity and Issues
The number of iterations corresponds to the sum of window sizes. Therefore, this number also equals the total number of times a window covered an element of .
We iterate over the element  in a window of size
in a window of size  (
( ) if
) if  items from
items from ![[a_1, a_2, \ldots, a_{i-1}]](/wp-content/ql-cache/quicklatex.com-52a68591cc63dc30b871f808780ffcfb_l3.svg "Rendered by QuickLaTeX.com") have already been selected. There are
have already been selected. There are  ways of doing it, so the number of times gets looped over is:
ways of doing it, so the number of times gets looped over is:
![[\sum_{\ell=0}^{\min\{k-1,i-1\}} \binom{i-1}{\ell}]](/wp-content/ql-cache/quicklatex.com-c7526eaed6d0d869ff77b0ecfd148307_l3.svg "Rendered by QuickLaTeX.com")
The  ensures we count valid windows. For example, there’s no way to select two elements before
ensures we count valid windows. For example, there’s no way to select two elements before  , and this condition is there to disregard such windows.
, and this condition is there to disregard such windows.
So, the total complexity is:
![[\begin{aligned} \sum_{i=1}^{n}\sum_{\ell=0}^{\min\{k-1,i-1\}} \binom{i-1}{\ell} &= \sum_{\ell=0}^{k-1}\sum_{i=\ell+1}^{n} \binom{i-1}{\ell} \in O(2^n) \end{aligned}]](/wp-content/ql-cache/quicklatex.com-ddfa1eab377fcdf09a1085643e9eb122_l3.svg "Rendered by QuickLaTeX.com")
Although this algorithm is also exponential, its recursion tree is shallower than the first. It has levels, so the stack size complexity is  .
.
Therefore, this approach can work for large sets if the number of elements to be selected is less than the maximum call stack depth.
However, if is large, this method won’t work.
5. Iterative Algorithm
In the iterative approach, we start with the first lexicographic combination: ![[a_1, a_2, \ldots, a_k]](/wp-content/ql-cache/quicklatex.com-d8697a23d6a598d3e23ce86b98d0134a_l3.svg "Rendered by QuickLaTeX.com") . Then, we keep generating the next combination from the current one until we have generated all combinations.
. Then, we keep generating the next combination from the current one until we have generated all combinations.
5.1. Generating the Next Combination
To get the next combination from the current  , we find the rightmost element of that we can replace with a lexicographically larger element. The last element
, we find the rightmost element of that we can replace with a lexicographically larger element. The last element ![x[k]](/wp-content/ql-cache/quicklatex.com-cef11349835abbe2350d882dbbe85c54_l3.svg "Rendered by QuickLaTeX.com") is replaceable if it’s lexicographically smaller than
is replaceable if it’s lexicographically smaller than  . Similarly, the second-to-last element
. Similarly, the second-to-last element ![x[k-1]](/wp-content/ql-cache/quicklatex.com-277d96cabf7a69e300e83929b75d6ecf_l3.svg "Rendered by QuickLaTeX.com") is replaceable if it’s lexicographically smaller than
is replaceable if it’s lexicographically smaller than  .
.
So, the general rule is that ![x[k-j]](/wp-content/ql-cache/quicklatex.com-02803d193cdf076b8624ada61702b01d_l3.svg "Rendered by QuickLaTeX.com") is replaceable if it’s lower than
is replaceable if it’s lower than  . The equivalent formulation is that is replaceable if
. The equivalent formulation is that is replaceable if ![x[j] < a_{n-k+j}](/wp-content/ql-cache/quicklatex.com-adf51e31633c53559e362273603a33ab_l3.svg "Rendered by QuickLaTeX.com") .
.
Let’s say that the rightmost replaceable element of is at the th position and equal to . We replace the right sub-array ![x[j : k]](/wp-content/ql-cache/quicklatex.com-f085862aca5f40431184eb82cd708108_l3.svg "Rendered by QuickLaTeX.com") with
with  successors of :
successors of : ![[a_{i+1}, a_{i+2}, \ldots, a_{i+k-j+1}]](/wp-content/ql-cache/quicklatex.com-c6e9576b8f9d7ea9dd37321464878953_l3.svg "Rendered by QuickLaTeX.com") . This way, we get the next combination.
. This way, we get the next combination.
5.2. Pseudocode
We start with the first lexicographic -combination :
algorithm OutputKCombinationsIteratively(S, k):
// INPUT
// S = {a_1, a_2, ..., a_n}, the set of elements
// k = the number of elements in each combination (0 ≤ k ≤ n)
// OUTPUT
// All k-combinations of S
// Start with the first lexicographic combination
x <- [a_1, a_2, ..., a_k]
Output x
j <- RightmostReplaceable(x, k)
while j != false:
// Let ai be the element x[k].
Set x[j : k] to [a[i+1], a[i+2], ..., a_[i+k-j+1]]
Output x
j <- RightmostReplaceable(x, k)
algorithm RightmostReplaceable(x, k):
// INPUT
// x = the current combination
// k = the number of elements in each combination
// OUTPUT
// The index of the rightmost replaceable element or false if none exists
j <- k
while j >= 1 and x[j] = a_[n-k+j]:
j <- j - 1
if j >= 1:
return j
else:
return false
The process stops when we get to the last lexicographic combination ![[a_{n-k+1},\ldots, a_{n-1}, a_n]](/wp-content/ql-cache/quicklatex.com-77109746e8e58c0f4a7c2c1d9ca805c4_l3.svg "Rendered by QuickLaTeX.com") since it has no replaceable element.
since it has no replaceable element.
5.2. Complexity
If is the rightmost replaceable element in , generating the next combination takes steps. So, the overall time complexity is:
![[O \left( \sum_{j=1}^{k}(k-j+1) \times N_j \right)]](/wp-content/ql-cache/quicklatex.com-36369e0e9585d60db084acfa0d217f32_l3.svg "Rendered by QuickLaTeX.com")
where  is the number of combinations in which the rightmost replaceable element is at the th position.
is the number of combinations in which the rightmost replaceable element is at the th position.
Let’s find . If the rightmost replaceable is , then ![x[j+1, j+2, \ldots, k]=[a_{n-k+j}, a_{n-k+j+1}, \ldots, a_n]](/wp-content/ql-cache/quicklatex.com-dbffcedefe4b2505847e534df60a4574_l3.svg "Rendered by QuickLaTeX.com") . So,
. So,  elements are fixed, and the left part contains elements we can select from
elements are fixed, and the left part contains elements we can select from  . Therefore:
. Therefore:
![[N_j = \binom{n-k+j}{j}]](/wp-content/ql-cache/quicklatex.com-badbd19ac680f6201e23755e01da90cd_l3.svg "Rendered by QuickLaTeX.com")
From there, we get the time complexity:
![[O \left( \sum_{j=1}^{k}(k-j+1) \times N_j \right) = O \left( \sum_{j=1}^{k}(k-j+1) \times \binom{n-k+j}{j} \right)]](/wp-content/ql-cache/quicklatex.com-6355c81e1d7fad95b525ed21a810b92e_l3.svg "Rendered by QuickLaTeX.com")
This reduces to:
![[O \left( \frac{n+2}{(n+2-k)(n+1-k)} \binom{n+1}{k+1}\right)]](/wp-content/ql-cache/quicklatex.com-3213cacc3148bc88f3c057e5b264f187_l3.svg "Rendered by QuickLaTeX.com")
Taking to be constant with respect to , we get  . So, this algorithm has the same polynomial complexity as
. So, this algorithm has the same polynomial complexity as  , the number of -combinations.
, the number of -combinations.
6. Conclusion
In this article, we explained three algorithms for generating combinations: two recursive and one iterative.
The recursive approaches might be easier to understand and code, but the iterative solution is the most efficient.