1. 概述
图论中,计算最小生成树(Minimum Spanning Tree, MST)的两种主流算法是:
本文将分别介绍它们的原理、实现和优劣对比,帮助你根据实际场景选择更合适的算法。
2. 最小生成树(MST)
最小生成树是指一个无向连通图中,连接所有顶点且总权值最小的一组边构成的树结构。
需要注意的是:
✅ MST 是一个树结构,不含环
✅ MST 适用于无向连通图
✅ MST 的总权值是所有选中边的权重之和
如下图所示,红色边构成了一个 MST:
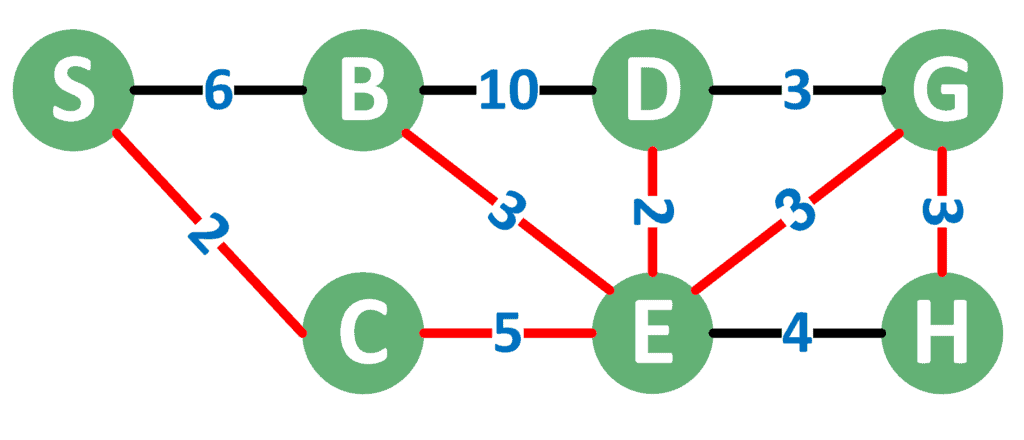
上图中 MST 的总成本为:2 + 5 + 3 + 2 + 3 + 3 = 18。
⚠️ 注意:MST 不唯一。当图中存在多个相同权重的边时,不同算法或不同处理顺序可能会得到不同的 MST,但它们的总权重一定相同。
3. Kruskal 算法
3.1 核心思想
Kruskal 算法的核心是贪心策略:
- 将所有边按权重从小到大排序
- 依次选择权重最小的边
- 如果这条边连接的两个顶点不在同一集合中(不会形成环),就将它加入 MST
- 否则跳过这条边
为了高效判断是否形成环,Kruskal 使用了并查集(Disjoint Set Union, DSU)结构。
3.2 实现步骤
伪代码如下:
algorithm KruskalAlgorithm:
// INPUT
// edges = 所有边的列表
// OUTPUT
// 返回 MST 的总权重和边集合
sort(edges)
totalCost <- 0
mst <- []
for edge in edges:
if not dsu.isMerged(edge.u, edge.v):
totalCost += edge.weight
mst.add(edge)
dsu.merge(edge.u, edge.v)
return totalCost, mst
3.3 特点分析
✅ 优点:
- 实现简单,逻辑清晰
- 对 MST 有较强的控制能力,尤其在边权重相同时可以灵活选择
❌ 缺点:
- 时间复杂度为 **O(E log V)**,排序操作是主要开销
- 更适合稀疏图(边数较少)
⚠️ 注意:Kruskal 是一种边驱动算法,每次处理一条边,因此在处理边数较多的图时效率较低。
4. Prim 算法
4.1 核心思想
Prim 算法是一种点驱动的贪心算法,其思想类似于 Dijkstra 算法:
- 从任意一个顶点开始
- 维护一个优先队列(最小堆),保存当前可到达的边
- 每次选择权重最小的边扩展 MST
- 避免重复加入顶点,使用集合记录已加入 MST 的顶点
4.2 实现步骤
伪代码如下:
algorithm PrimsAlgorithm:
// INPUT
// G = 给定图
// source = 起始顶点
// OUTPUT
// 返回 MST 的总权重和边集合
totalCost <- 0
included <- empty set
Q.addOrUpdate(source, 0, null)
while Q not empty:
u = Q.getNodeWithLowestWeight()
totalCost += u.weight
if u.edge != null:
mst.add(u.edge)
included.add(u.node)
for v in G.neighbors(u.node):
if v.node not in included:
Q.addOrUpdate(v.node, weight(u.node, v.edge), v.edge)
return totalCost, mst
4.3 特点分析
✅ 优点:
- 时间复杂度为 **O(E + V log V)**,在稠密图中性能更优
- 更适合边数多的图
❌ 缺点:
- 实现相对复杂,需要维护优先队列和更新机制
- 对 MST 的控制较弱,无法像 Kruskal 那样灵活处理相同权重的边
⚠️ 注意:Prim 算法每次只关注当前可达的最小边,因此在边权重相同时,MST 的具体结构可能不一致,但总权重一定相同。
5. Kruskal 与 Prim 的对比
| 特性 | Kruskal | Prim |
|---|---|---|
| MST 控制能力 | ✅ 强,可灵活处理相同权重边 | ❌ 弱,依赖优先队列状态 |
| 实现难度 | ✅ 简单 | ❌ 稍复杂 |
| 数据结构 | 并查集(Disjoint Set) | 优先队列(Priority Queue) |
| 时间复杂度 | O(E log V) | O(E + V log V) |
| 适用场景 | ✅ 稀疏图 | ✅ 稠密图 |
6. 总结
| 算法 | 控制能力 | 实现难度 | 时间复杂度 | 适用场景 |
|---|---|---|---|---|
| Kruskal | ✅ 强 | ✅ 简单 | O(E log V) | 稀疏图 |
| Prim | ❌ 弱 | ❌ 稍复杂 | O(E + V log V) | 稠密图 |
✅ 选择建议:
- 如果你关注 MST 的结构控制,比如在边权重相同的情况下想影响 MST 的选择顺序,优先选择 Kruskal
- 如果图中边数很多(稠密图),Prim 算法效率更高
两者都是经典的 MST 算法,掌握它们对于理解图论问题、设计高效算法非常有帮助。