1. 概述
本文将展示如何在一个二叉搜索树中找到第 k 小的元素。我们将详细讨论如何实现这一功能,并对比不同方法的时间复杂度。
2. 第 k 小元素
假设我们有一个二叉搜索树 T,包含 n 个元素:[a_1, a_2, \ldots, a_n]。我们的目标是找到第 k 小的元素。具体来说,如果 [a_{(1)} \leq a_{(2)} \leq \ldots \leq a_{(n)}] 是排序后的序列,那么我们需要找到对应的 (a_{(k)}),其中 (k \in {1, 2, \ldots, n})。
以下是一个示例二叉搜索树:
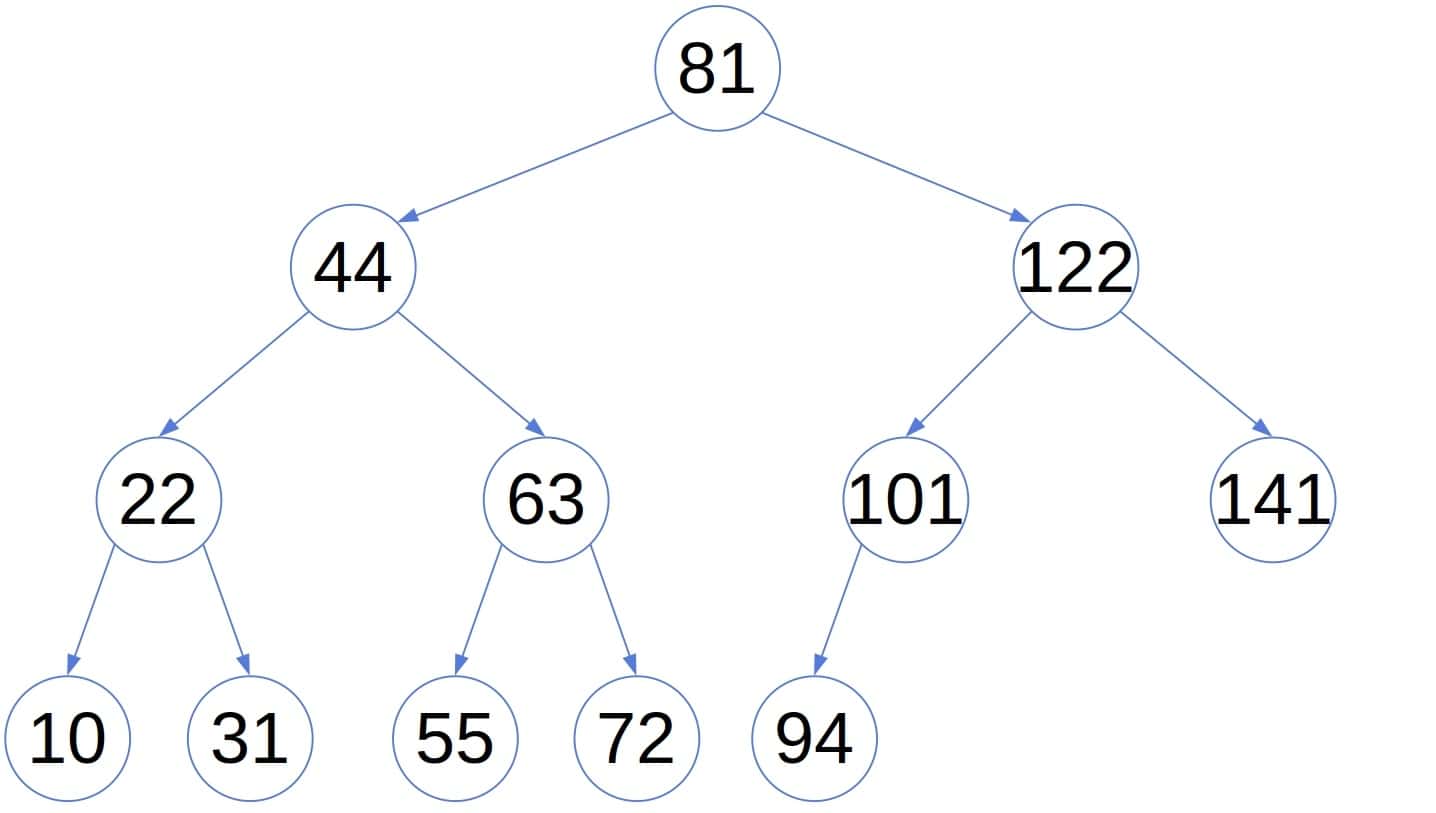
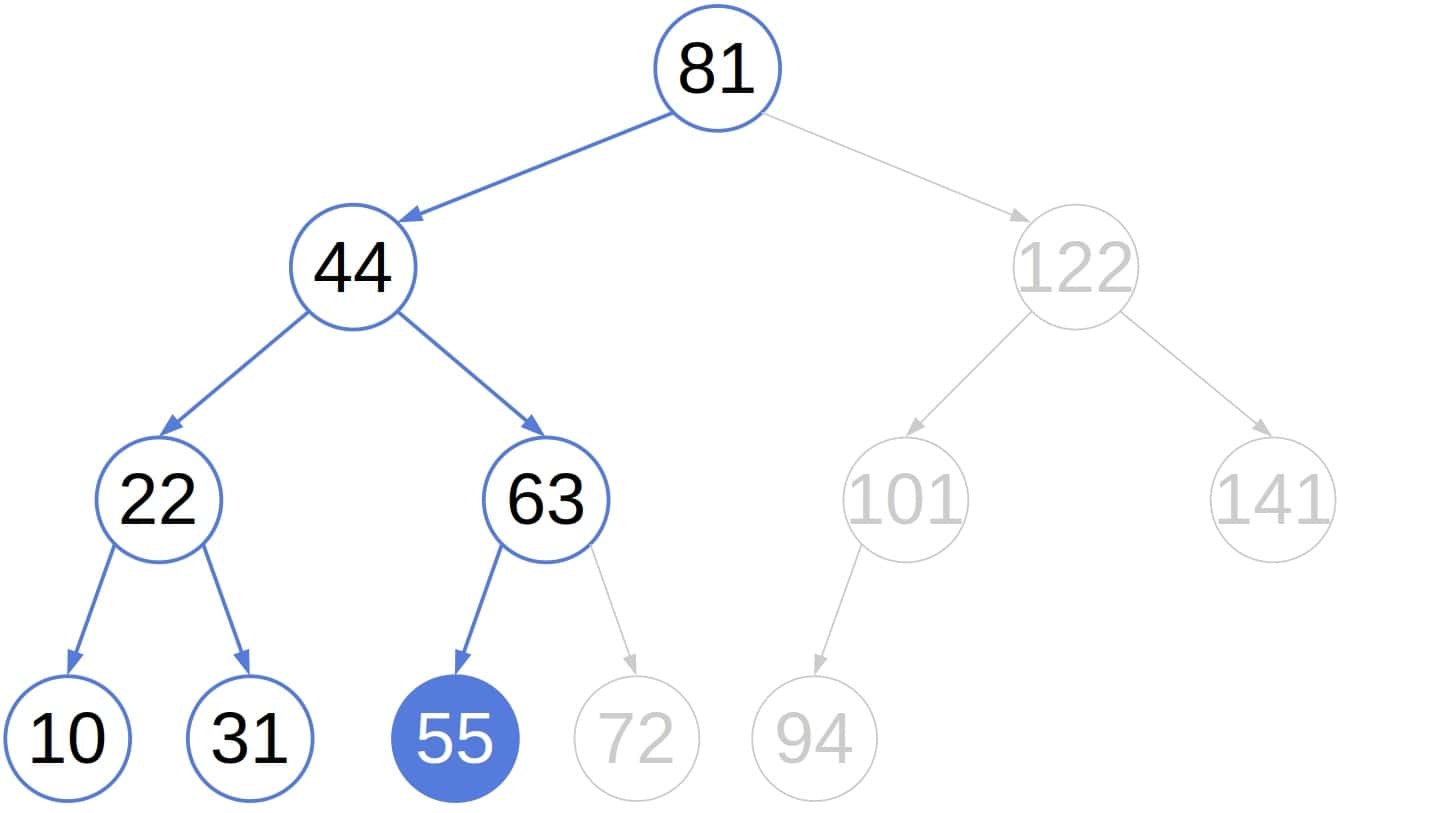
这是一个典型的二叉搜索树,其中每个节点的值都小于其右子树的所有节点的值,并且大于或等于其左子树的所有节点的值。例如,若 (k=5),则在树中找到第5小的数如下所示:
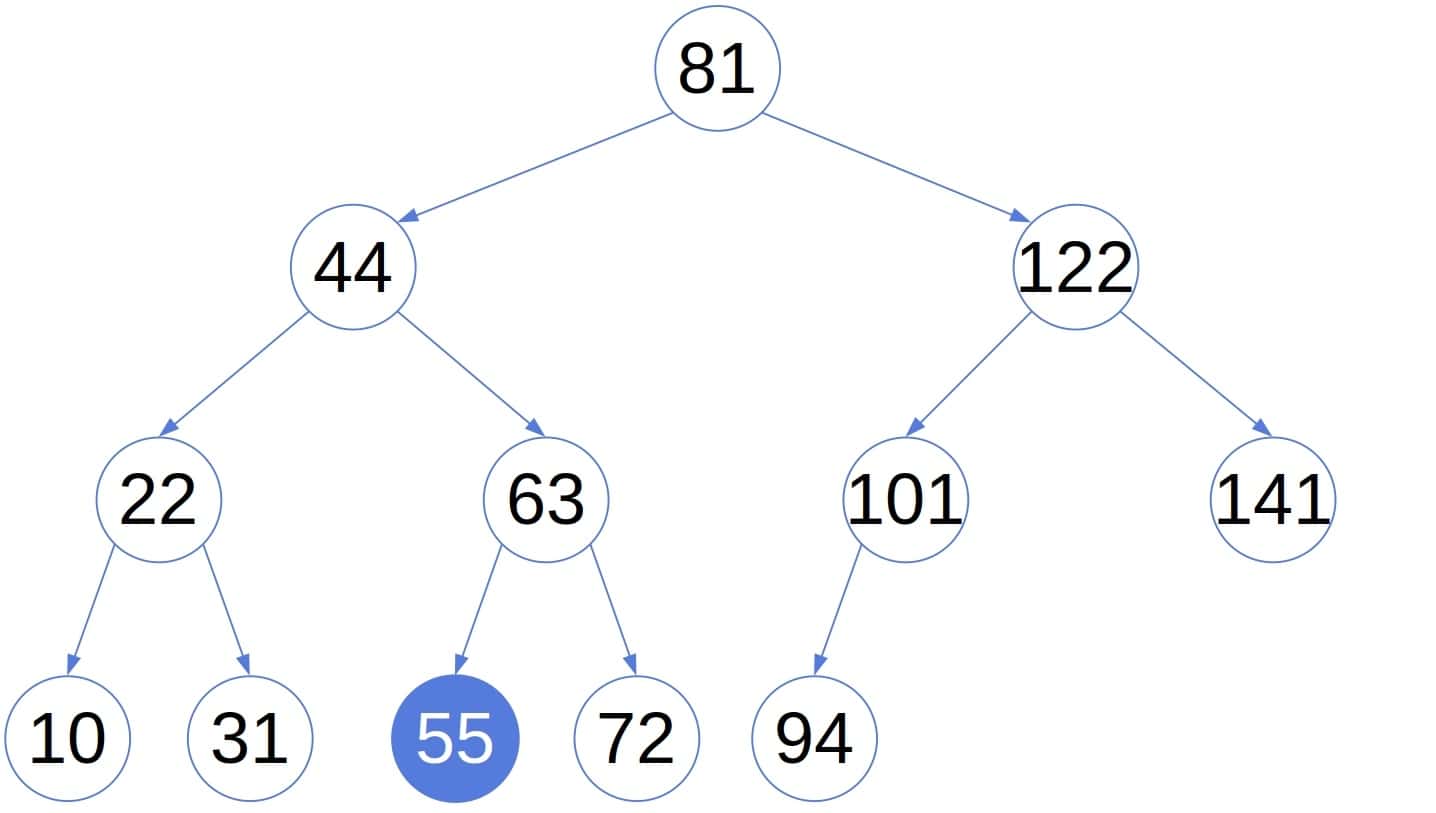
3. 使用中序遍历查找第 k 小元素
由于二叉搜索树的中序遍历可以按照升序输出所有元素,我们可以通过执行遍历来找到第 k 个元素。当遍历到第 k 个元素时,我们可以停止,因为此时我们已经找到了所需元素。
algorithm findKthSmallestElementInOrder(T, k):
// INPUT
// T = the tree to traverse
// k = the rank of the element we want to find
// OUTPUT
// The k-th smallest element in the tree or null if the tree has fewer than k nodes.
m <- 0
for x in TRAVERSE-IN-ORDER(T.root):
m <- m + 1
if m = k:
return x
return null
function TRAVERSE-IN-ORDER(x):
if x.left != null:
TRAVERSE-IN-ORDER(x.left)
yield x
if x.right != null:
TRAVERSE-IN-ORDER(x.right)
我们使用了遍历过程作为迭代器,因此使用了关键字 yield。当然,完全递归算法同样有效。
3.1. 复杂度
这种方法适用于任何二叉搜索树,但时间复杂度为线性。对于 (k=n) 的情况,算法会遍历整个树以获取最大元素。
4. 通过跳过子树查找第 k 小元素
如果我们存储每个节点的子节点数量,我们可以更高效地找到第 k 小的元素。例如:
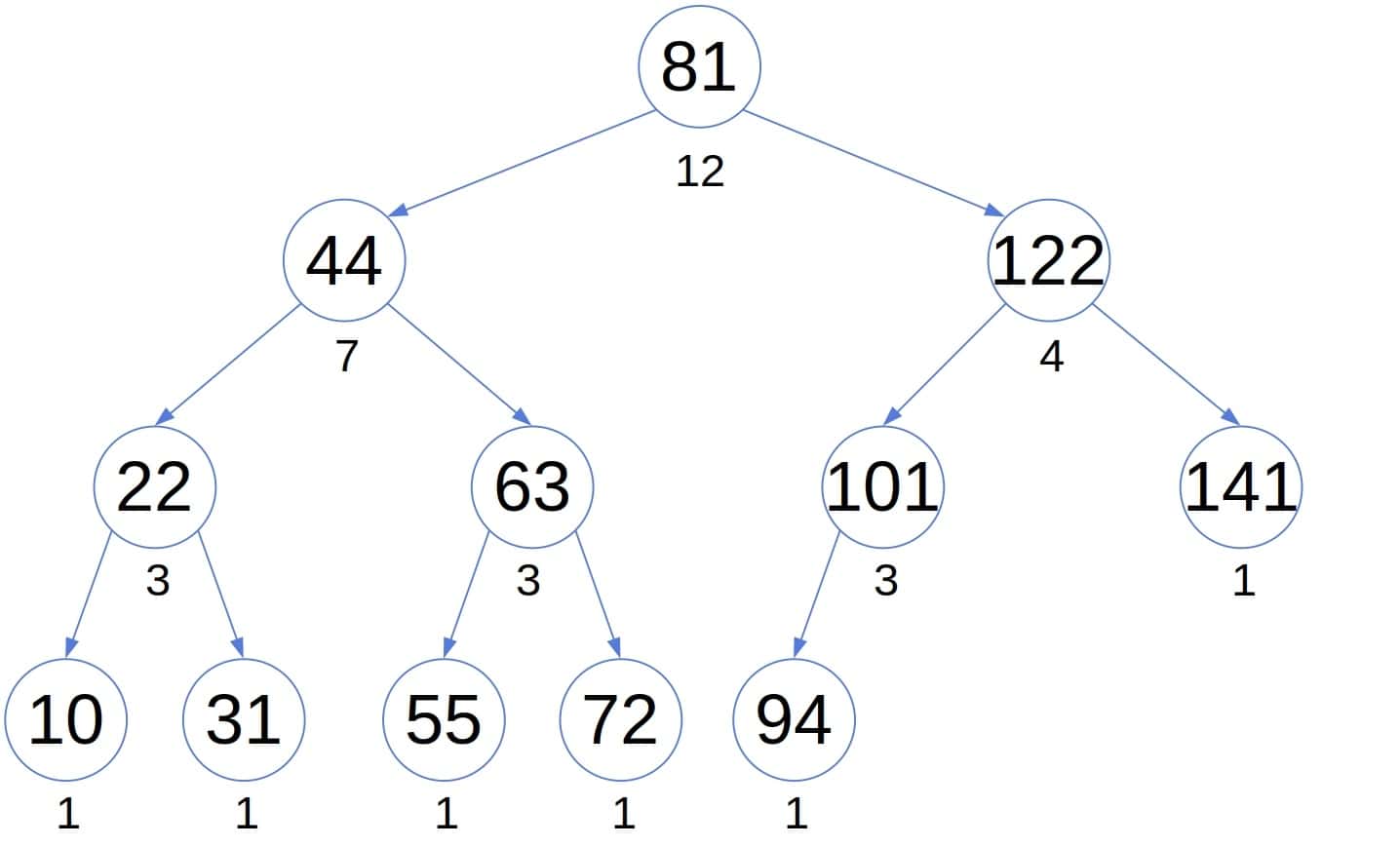
额外的信息可以加速中序遍历。假设我们访问了 m 个节点之前到达 x 节点,并且 x 的左子树有 (\ell) 个节点,则如果 (m + \ell < k),我们可以跳过遍历该子树。为什么呢?因为我们可以确定第 k 小的元素不在子树中。因此,安全地“跳过”它是合理的。在这样做时,我们区分两种情况。如果 (m + \ell = k - 1),则 x 是树中第 k 小的元素。如果 (m + \ell < k - 1),我们可以跳过 x 直接进入右子树。
相反,如果 (m + \ell \geq k),第 k 小的元素肯定在左子树中。
4.1. 模拟代码
以下是模拟代码:
algorithm JUMP-TRAVERSE(x, k, m):
// INPUT
// x = the node we've reached (initially, the tree's root)
// m = the number of nodes we visited before calling the function with x as its argument
// k = the rank of the element we want to find
// OUTPUT
// the k-th smallest element in the tree
if x.left = null:
l <- 0
else:
l <- x.left.size
if m + l >= k and x.left != null:
return JUMP-TRAVERSE(x.left, k, m)
else if m + l = k - 1:
return x
else if m + l < k - 1 and x.right != NULL:
return JUMP-TRAVERSE(x.right, k, m + l + 1)
开始时,我们可以测试 (T.root.size < k) 来检查元素是否存在。
4.2. 示例
为了展示修改后的遍历效率,让我们检查在上述树中查找第5小元素前访问了多少节点:
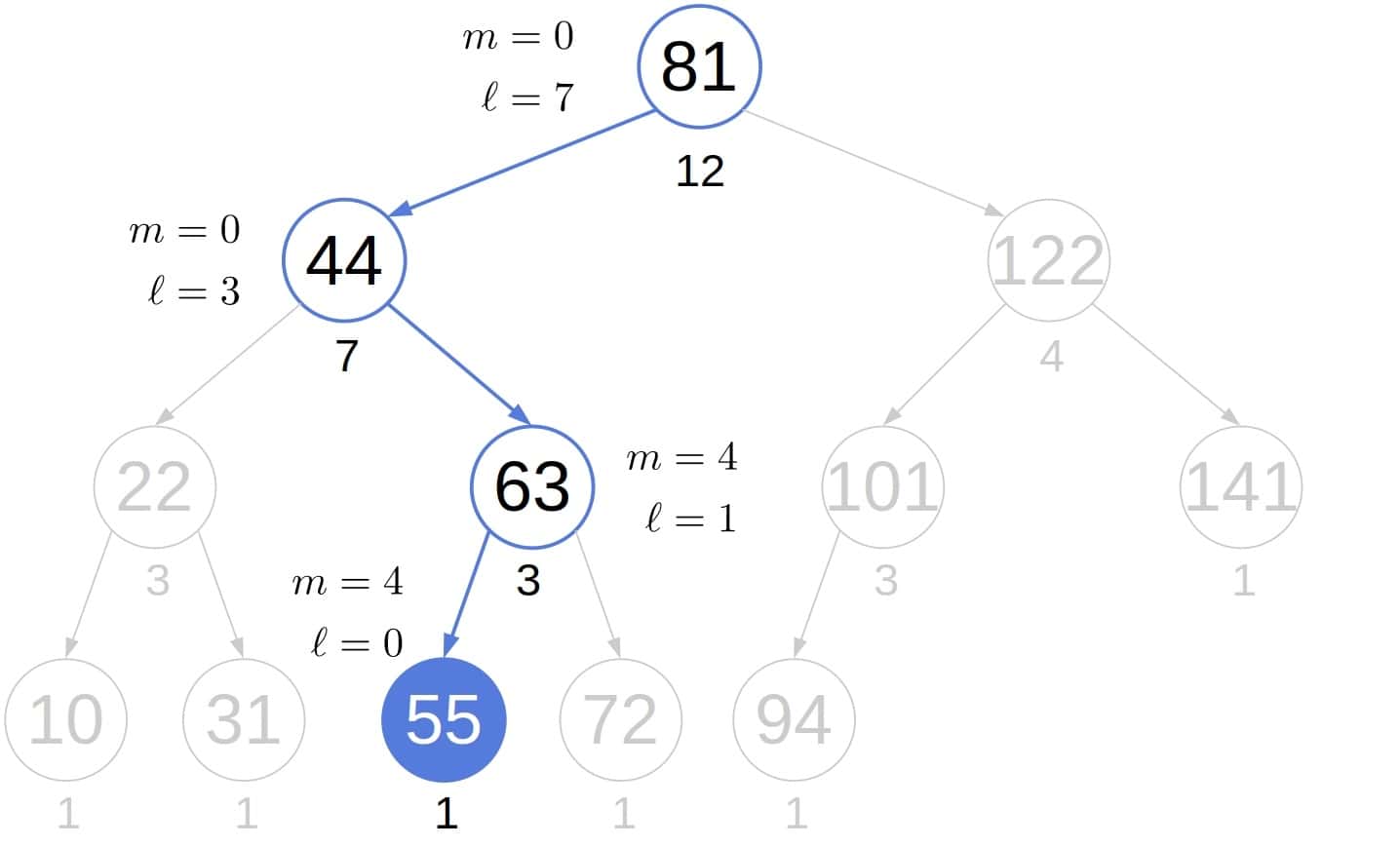
相比之下,通常的中序搜索会遍历我们跳过的左子树的所有节点:
4.3. 复杂度
最坏情况下,我们跳过的子树是最小可能的情况。这种情况发生在 (k=n) 并且树中的每个节点只有一个右子节点时。这种树本质上是一个链表。每步跳过零个节点,总共遍历 (n) 个节点。
一般而言,每次跳过子树的节点都在从根到包含所需值的节点的路径上。因此,此算法的最坏情况时间复杂度为 (\mathcal{O}(h)),其中 (h) 是树的高度,即从根到叶的最长路径。如果树是平衡的,则有 (h \in O(\log n)),因此算法具有对数复杂度。没有额外的子树大小信息,普通的遍历即使在平衡树中也会有 (\mathcal{O}(n)) 运行时间。
然而,平衡树增加的计算开销意味着这种方法只在查找次数多于插入和删除次数的情况下才值得使用。此算法的理想应用场景是在构建一次后不再更改的查找树。
5. 总结
本文展示了如何在二叉搜索树中找到第 k 小的元素。除了常规的中序遍历外,我们还可以使用更有效的方法,特别是当我们使用平衡树时,可以在树中存储每个子树的大小信息。