1. 概述
本文将介绍主题建模(Topic Modeling)的基本概念、应用场景以及重点讲解其中一种主流技术 —— LDA(Latent Dirichlet Allocation,潜在狄利克雷分布)。
LDA 是一种基于统计学的概率生成模型,广泛应用于文本挖掘、自然语言处理等领域。阅读本文前建议对多变量概率分布有基本了解,有助于更好地理解 LDA 的数学基础。
2. 主题建模简介
2.1. 什么是主题建模?
简单来说,文本的主题就是它的主旨或内容核心。
主题建模是一种无监督学习方法,输入是一组文本文档(corpus),输出是若干个“主题”(topics),每个主题由一组词构成,并带有权重。文档可以表示为这些主题的组合。
举个例子:
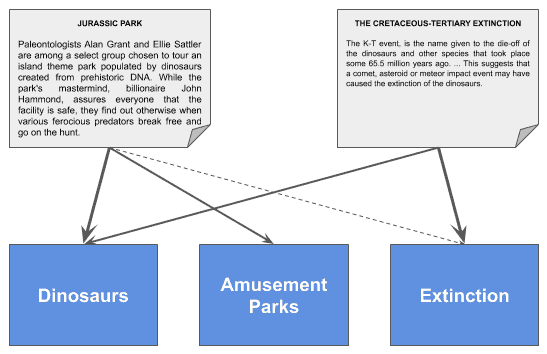
上图中,每个文档与多个主题有不同权重的关联。比如,文档“Jurassic Park”可以表示为:
✅ 主题向量:[0.97, 0.49, 0.1]
对应的主题分别是:
- “恐龙”:97%
- “主题公园”:49%
- “灭绝”:10%
因此,主题建模可用于将文档转换为嵌入向量(embedding vector),便于后续的文本相似度计算、聚类等任务。
2.2. 应用场景
主题建模在多个领域都有广泛用途,包括但不限于:
- 领域趋势分析
- 用户兴趣建模
- 文档相似度比较
- 作者归属分析
- 情感分析
- 机器翻译
- 搜索个性化
- 向量化文本表示(embedding)
2.3. 常见主题建模技术
以下是一些主流的主题建模方法:
- NMF(非负矩阵分解)
- LSA(潜在语义分析)
- PLSA(概率潜在语义分析)
- LDA(潜在狄利克雷分布)✅
- lda2vec
- tBERT(结合 BERT 的主题模型)
其中,LDA 是最经典、最广泛使用的概率生成模型之一。
3. LDA 模型详解
3.1. 简介
LDA 是一种基于狄利克雷分布(Dirichlet Distribution)的统计生成模型。
输入是一组文档集合(corpus),我们指定希望发现的主题数量 K,LDA 输出每个文档的主题分布和每个主题的词分布。
简而言之,LDA 的目标是找出文档与主题之间的关系,以及主题与词之间的关系。
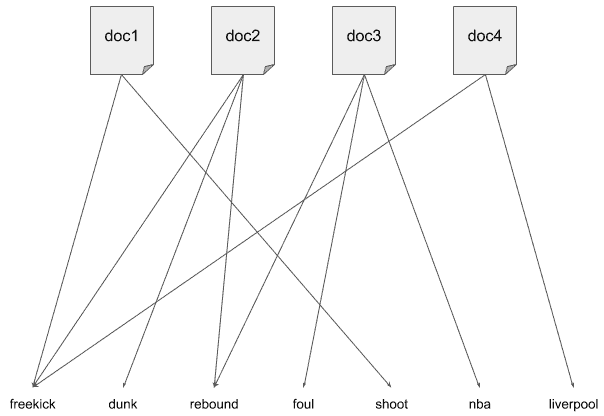
如下图所示,原始文档中词的分布:
当 K=2 时,LDA 模型可能生成如下结构:
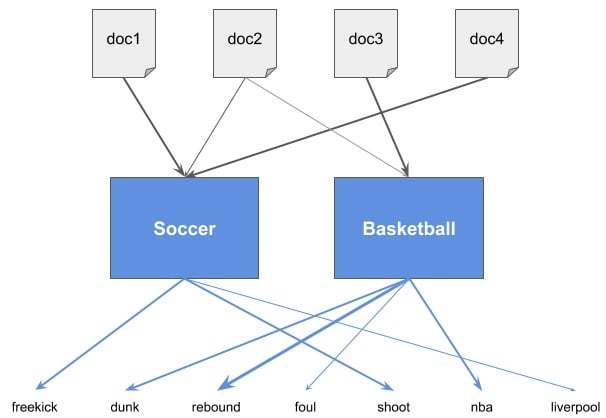
可以看到,LDA 在文档和词之间引入了“主题”这一中间层,并建立了两层关系:
- 文档 ↔ 主题
- 主题 ↔ 词
现实中,我们通常不知道每个主题具体代表什么,需要通过分析词分布来“命名”主题。
3.2. 为什么使用狄利克雷分布?
狄利克雷分布能够体现“文档通常只与少数几个主题相关”的直觉。
在传统随机分布中,文档可能均匀分布在所有主题上:
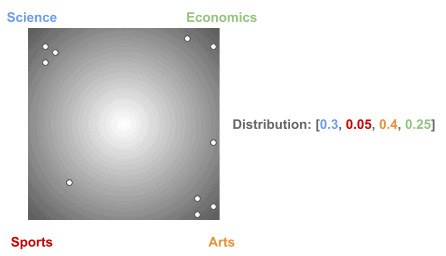
而现实中,文档往往更稀疏地分布于主题之间,如下图所示:
LDA 使用狄利克雷分布可以更自然地模拟这种稀疏性,从而提升主题建模的准确性。
3.3. 狄利克雷分布简介
狄利克雷分布是一种用于建模离散随机变量概率分布的工具。比如,掷骰子时:
- 公平骰子的概率分布:
[0.16, 0.16, 0.16, 0.16, 0.16, 0.16] - 有偏骰子的概率分布:
[0.25, 0.15, 0.15, 0.15, 0.15, 0.15]
在 LDA 中,有两个核心概率分布:
- **θd**:文档 d 中各主题的概率分布
- **φk**:主题 k 中各词的概率分布
这两个分布都服从狄利克雷分布:
- θd ~ Dir(α)
- φk ~ Dir(β)
其中 α 和 β 是集中参数(concentration parameter),它们控制分布的稀疏程度:
- α = 1:均匀分布
- α > 1:集中分布
- α < 1:稀疏分布 ✅(我们想要的)
3.4. 狄利克雷分布是一类分布
使用相同的 α 参数,可以得到不同的文档-主题分布:
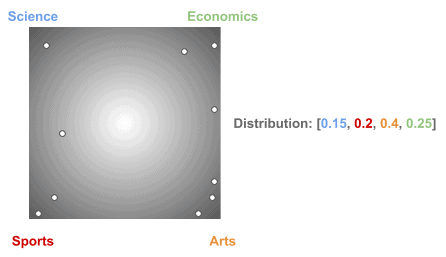
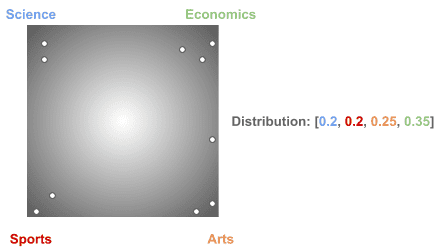
LDA 的训练过程会不断调整这些分布,以使模型更贴合实际数据。
3.5. 如何生成新文档?
LDA 是一个生成模型,可以模拟生成新的文档。虽然这些文档通常不具备语义逻辑,但能反映模型的统计特性。
假设我们有如下主题和词分布:

- D1:文档-主题分布
- D2:主题-词分布
步骤如下:
- 从 D1 中抽样主题(如 Science、Economics)
- 对每个抽样主题,从 D2 中抽样词(如 laser、recession)
- 将这些词组合成文档
示例生成文档:
"laser recession piano dollar piano piano laser computer soccer piano"
虽然语义不通,但符合模型的概率分布。
3.6. 如何理解主题含义?
LDA 生成的主题没有语义标签,需要我们根据词分布进行人工解读。
例如,当 K=4 时,词集合为:
V = {soccer, ball, piano, laser, computer, dollar, recession}
LDA 输出的主题词分布如下:
Topic 1: [0.0, 0.1, 0.0, 0.55, 0.35, 0.0, 0.0]
Topic 2: [0.4, 0.4, 0.0, 0.0 , 0.0 , 0.2, 0.0]
Topic 3: [0.0, 0.0, 0.9, 0.0 , 0.0 , 0.1, 0.0]
Topic 4: [0.0, 0.0, 0.0, 0.0 , 0.1 , 0.5, 0.4]
我们可以这样理解:
- Topic 1:laser、computer → 科技/科学
- Topic 2:soccer、ball → 体育
- Topic 3:piano → 音乐
- Topic 4:dollar、recession → 经济
3.7. 使用 Gibbs 抽样训练模型
LDA 的训练通常使用 Gibbs 抽样 方法,核心思想如下:
- 初始为每个词随机分配一个主题
- 依次重新分配每个词的主题,使文档尽可能包含更少主题
- 同时使每个词尽可能属于更少主题
该过程反复迭代直到收敛。
感兴趣的读者可以参考 这个视频 了解详细实现。
4. 总结
本文介绍了主题建模的基本概念、常见应用场景以及主流技术。重点讲解了 LDA 模型的原理、数学基础(狄利克雷分布)、如何生成新文档以及如何解读主题。
LDA 是一种强大的工具,尤其适用于大规模文本分析和信息组织。理解其背后的统计原理,有助于更好地应用和调优模型。