1. Introduction
In this tutorial, we’re going to discuss the Learning Rate Warm-up, which is a method that aims to automatically tune a hyper-parameter called Learning Rate (LR) before formally starting to train a model.
2. Context
3. Dive Into the Learning Rate Warm-up Heuristic
4. Different Types of Learning Rate Warm-up Heuristics and Alternatives
There exist several types of LR warm-ups. Let’s go through some of them below:
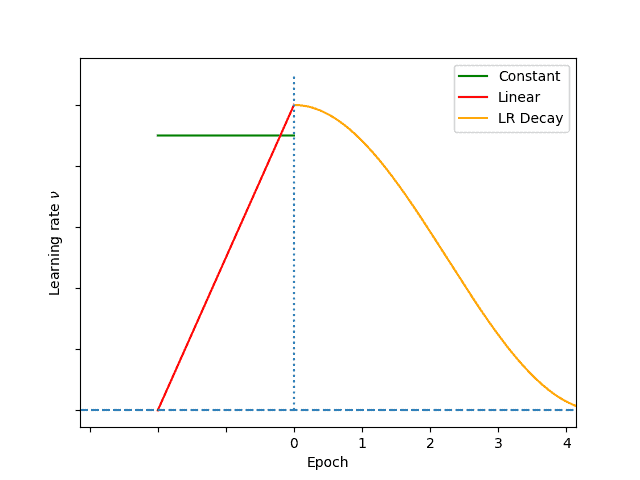
We denote by  the initial LR and
the initial LR and  the number of warm-up steps (epochs or iterations):
the number of warm-up steps (epochs or iterations):
- Constant Warm-up: a constant LR value
 is used to warm up the network. Then, the training directly starts with LR . One drawback is the abrupt change of LR from
is used to warm up the network. Then, the training directly starts with LR . One drawback is the abrupt change of LR from  to
to - Gradual or linear Warm-up: the warm-up starts at LR and linearly increases to in steps. In other words, the LR at step
 is
is  . The gradual change of LR smoothes the Warm-up by connecting and with several intermediate LR steps
. The gradual change of LR smoothes the Warm-up by connecting and with several intermediate LR steps
Here again, there is no method to find the most efficient LR Warm-up type other than trying them one by one with different LR values.
There are other alternatives to this heuristic such as using an optimizer called RAdam. This relatively recent optimizer provides better control of the gradient variance, which is necessary when the model trains at a high LR. RAdam detects variance instabilities and smoothly changes the LR to avoid divergence at the earliest training steps.
5. Conclusion
In this article, we discussed the Learning Rate Warm-up as a powerful network regularization technique. In most common model training, it is combined with a high LR that decreases over time, which is a standard and reliable solution to obtain a good model, including large models such as Transformers.