1. 简介
MapReduce 是一种广泛采用的编程模型,最初由 Google 提出,用于通过 PageRank 算法计算网页排名。它被集成在 Apache Hadoop 框架中,特别适合处理大规模数据集的分布式计算任务。
该算法通过将任务拆分为 Map(映射)和 Reduce(归约)两个阶段,利用多个处理节点并行执行,从而实现高效的数据处理。每个任务都围绕着两个核心组件:Mapper 和 Reducer 展开。
2. MapReduce 的工作原理
在 MapReduce 中,键值对是其最基本的数据结构。算法接收一组输入键值对,并输出一组处理后的键值对。
2.1. Map 阶段
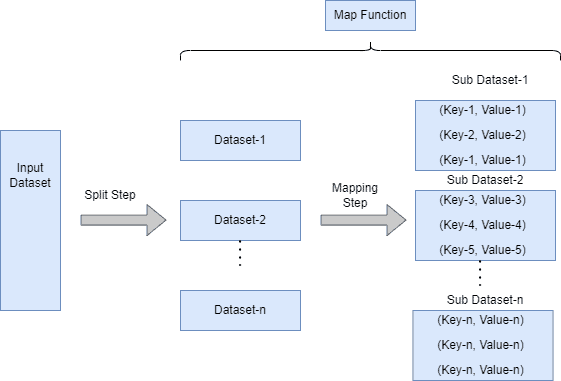
Map 阶段是整个流程的第一步,它的作用是将输入的键值对 (key1, value1) 转换为一组中间键值对 (key2, value2)。例如:
(key1, value1) → [(key2, value2)]
MapReduce 框架会将相同 key 的中间值分组,并将它们传递给 Reduce 函数进行下一步处理。
下图展示了 Map 阶段的执行流程:
2.2. Reduce 阶段
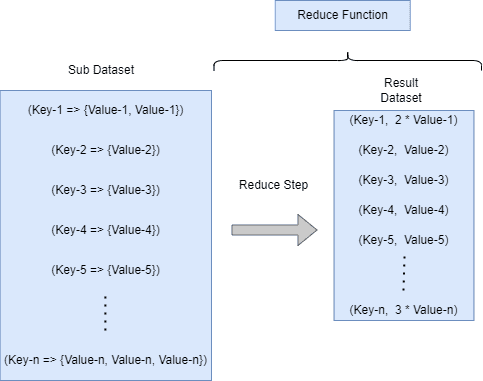
Reduce 阶段接收中间键 key2 和对应的一组值 [value2],然后将其合并简化为最终的输出键值对 (key3, value3):
(key2, [value2]) → (key3, value3)
Reduce 函数会使用一个迭代器来处理这些中间值,完成合并、汇总等操作。
下图展示了 Reduce 阶段的执行流程:
当 Reduce 阶段完成后,结果会被写入到 Hadoop 服务器中。
2.3. MapReduce 的具体任务
一个完整的 MapReduce 程序通常包括 Mapper 和 Reducer 的实现,以及输入路径、输出格式等配置参数。开发者将任务提交到集群中的某个节点,其余工作由执行框架自动处理。
MapReduce 的核心任务包括:
✅ 调度:将任务拆分为多个子任务并协调执行
✅ 数据与代码共存:为了提高数据本地性,调度器会尽量将任务分配到持有相关数据块的节点上
✅ 同步与排序:Shuffle 和 Sort 是 Map 和 Reduce 之间的中间阶段,用于对 Map 输出按 key 进行排序和分发
✅ 错误与容错处理:如果某个节点无响应,框架会将任务重新分配给其他节点继续执行
3. 为什么使用 MapReduce?
3.1. 算法优势
传统数据库在处理海量数据时常常面临性能瓶颈,特别是在计算与存储分离的架构中,即使任务本身计算需求不高,也会因数据传输延迟而受限。MapReduce 的优势在于:
✅ 任务分布式执行:将任务分发到多个节点并行执行,提高整体效率
✅ 数据本地性优化:减少数据在网络中的传输,提升性能
✅ 容错能力强:自动处理节点失败,保障任务顺利完成
✅ 可扩展性强:支持横向扩展,适用于 PB 级别的大数据处理
3.2. 使用场景
MapReduce 适用于多种大规模数据处理场景,以下是一些典型应用:
- 分布式 grep:Map 任务匹配特定模式的行,Reduce 任务直接输出结果
- URL 访问频率统计:Map 任务输出
<URL, 1>,Reduce 汇总为<URL, 总访问次数> - 反向网页链接图:Map 输出
<目标页面, 起始页面>,Reduce 合并所有起始页面形成<目标页面, [起始页面列表]> - 倒排索引:Map 读取文档并输出
<单词, 文档ID>,Reduce 合并后输出<单词, [文档ID列表]>
4. 示例:词频统计
我们以经典的“词频统计”问题为例,展示 MapReduce 的使用方式。
伪代码实现
function Map(docid, doc):
// INPUT
// docid = 文档标识符
// doc = 文档内容
// OUTPUT:
// 输出键值对 <term, 1>
for term in doc:
EMIT(term, 1)
function Reduce(term, [c1, c2, ...]):
// INPUT
// term = 唯一词项
// counts = 该词项出现的次数列表
// OUTPUT
// 输出键值对 <term, sum>
sum <- 0
for c in [c1, c2, ...]:
sum <- sum + c
EMIT(term, sum)
在这个例子中,Mapper 会为每个单词生成一个 <单词, 1> 的键值对,Reducer 则将所有相同单词的计数相加,得到最终的词频统计结果。
5. 总结
MapReduce 是一种强大的分布式计算模型,凭借其良好的并行性和容错机制,广泛应用于处理海量数据的场景。它不仅能够高效处理 TB、甚至 PB 级别的数据,还能在大规模集群中实现任务的自动调度与负载均衡。
对于需要处理大数据的开发者和企业来说,掌握 MapReduce 的原理和使用方式是构建大数据处理系统的重要基础。