1. 什么是最大似然估计?
最大似然估计(Maximum Likelihood Estimation, MLE) 是一种在统计学和机器学习中常用的参数估计方法。其核心思想是:给定一个模型结构,找出使得观测数据出现概率最大的模型参数值。
换句话说,MLE 的目标是找到最有可能“生成”我们所观察到的数据的那个参数值。这种方法广泛应用于回归模型、逻辑回归、高斯分布拟合等任务中。
1.1. 概率 vs 似然
很多人会混淆“概率”和“似然”这两个概念。下面是一个简明对比:
✅ 概率(Probability):描述在已知模型参数的情况下,观测到某组数据的可能性。
表达式:
$$ P(X | \theta) $$
即:给定参数 $\theta$,数据 $X$ 出现的概率。✅ 似然(Likelihood):描述在观测到数据 $X$ 的前提下,某组参数 $\theta$ 能够解释该数据的可能性。
表达式:
$$ L(\theta | X) $$
即:观察到数据 $X$ 后,我们认为参数 $\theta$ 的“可信度”。
⚠️ 注意:似然不是概率密度函数,因为对所有参数 $\theta$ 的似然值求和不一定等于 1。
1.2. 最大似然估计的数学表达
根据上面的定义,我们可以将似然函数写作:
$$ L(\theta | X) = P(X | \theta) $$
我们的目标是找到使这个函数值最大的 $\theta$,即:
$$ \hat{\theta} = \arg\max_{\theta} P(X | \theta) $$
1.3. 如何进行最大似然估计?
假设我们有独立同分布(i.i.d)的数据样本 $x_1, x_2, ..., x_N$,那么联合似然函数可以表示为:
$$ \max_{\theta} \prod_{i=1}^{N} p(x_i | \theta) $$
为了方便计算,通常会对这个乘积取对数,变成求和形式:
$$ \max_{\theta} \sum_{i=1}^{N} \ln p(x_i | \theta) $$
这一步转换是可行的,因为对数函数是单调递增的,不会改变最大值的位置。
✅ 优势:
- 将乘法转换为加法,避免数值下溢
- 更容易使用梯度下降等优化方法
1.4. 与最小二乘法的关系
在假设误差服从正态分布的前提下,最大似然估计等价于最小二乘法(Ordinary Least Squares, OLS)。也就是说,MLE 是一个更通用的框架,而 OLS 是其中一种特例。
而且,MLE 是一个一致估计量(Consistent Estimator),这意味着随着样本量增加,估计值会收敛到真实参数值。
2. 示例:拟合小鼠体重的分布
我们有一组小鼠的体重数据,想用一个分布模型来拟合这些数据。我们先来看一下数据分布:
2.1. 选择模型
从图中可以看出,数据呈现钟形曲线,适合使用高斯分布(Gaussian Distribution)建模。高斯分布有两个参数:
- 均值 $\mu$
- 方差 $\sigma^2$
我们的目标就是通过最大似然估计,找到这两个参数的最佳估计值。
2.2. 参数估计过程
我们尝试了几个不同参数组合的高斯分布,并绘制在原始数据上:
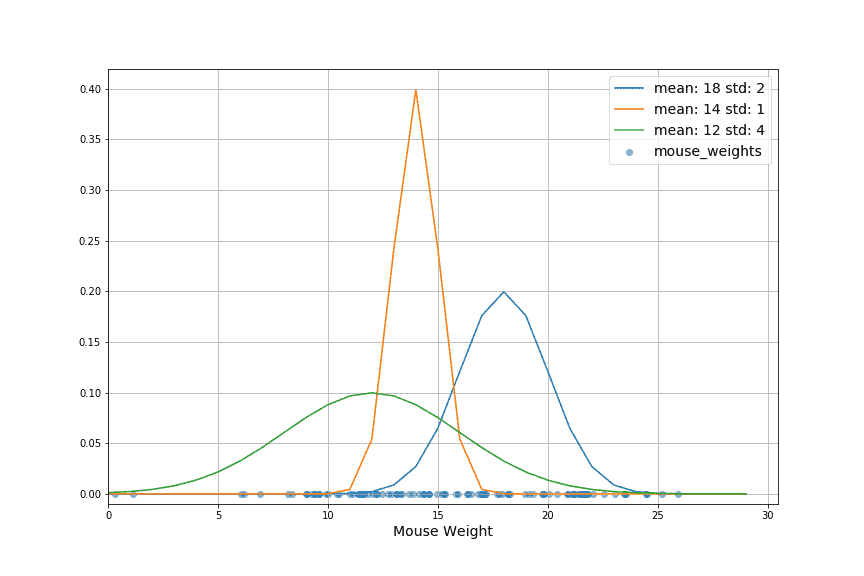
最终,通过 MLE 找到的最优参数是数据的均值和标准差。拟合出的分布能够最好地反映原始数据的统计特性。
3. MLE 的应用场景
最大似然估计被广泛应用于各种建模和优化任务中,包括但不限于:
- ✅ 统计模型参数估计(如回归、分类)
- ✅ 从样本中推断总体参数(如均值、方差)
- ✅ 模型选择(比较不同模型的拟合效果)
在深度学习中,我们常用负对数似然(Negative Log-Likelihood, NLL)作为损失函数来优化模型参数。
4. MLE 的局限性
虽然 MLE 是一个强大且通用的工具,但也有一些需要注意的地方:
- ❌ 模型必须正确指定:MLE 假设我们选择的模型是正确的。如果模型本身不适合数据(比如用高斯分布去拟合长尾分布),那么估计结果可能会有偏差。
- ❌ 计算复杂度较高:对于复杂的模型,推导似然函数并求解最大值可能需要数值优化方法,如梯度下降、模拟退火、蚁狮优化等。
- ❌ 对异常值敏感:MLE 依赖于数据分布假设,如果数据中存在异常点,可能导致参数估计不稳定。
5. 总结
最大似然估计是一种基础但强大的参数估计方法,它连接了统计学与机器学习的核心思想。通过 MLE,我们能够:
- 从数据中估计模型参数
- 评估不同模型的拟合效果
- 构建更复杂的优化问题(如深度学习)
理解 MLE 的原理,有助于我们更好地掌握很多算法背后的逻辑,也能帮助我们在建模过程中做出更合理的假设和选择。
✅ 掌握 MLE 是深入理解统计建模与机器学习的关键一步。