1. 概述
本文将探讨如何在文本中识别情绪。通过学习,我们将掌握自然语言处理中情感分析的基本理论,并了解一些公开可用的数据集,可用于训练情绪识别模型。
文章最后,你将清晰了解情感分析在什么情况下有效、在什么情况下存在局限性。同时,也会知道从哪里获取用于文本内容分析和情绪检测的机器学习模型训练数据。
2. 情绪与语言
2.1 情绪的内外维度
人类的情绪具有两个维度:内部主观维度和外部共享维度。
内部维度是个人直接体验的情绪状态,无法直接分享给他人。它对应于个体的心理状态以及大脑中与情绪相关的神经回路活动。从内容分析的角度来看,这部分是不可观测的,可以理解为一个“黑盒”。
外部维度则是个体通过面部表情、肢体语言、语调等方式表达出来的部分。这部分是可以被他人感知和解读的。
✅ 重点:
- 内部情绪是主观的、不可观测的
- 外部情绪是表达的、可观测的
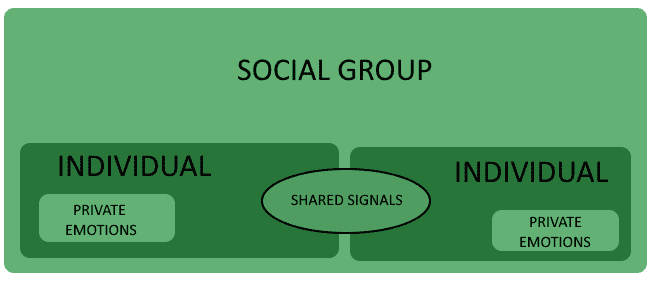
2.2 情绪与个体协作
当个体表达情绪时,周围的人会接收到这些信号,并作出相应的反应。这种信号的传播和模仿,使得群体中形成某种情绪的共鸣和协调。
例如,当一个人看到老虎时表现出恐惧,其他人也会随之警觉并表现出类似的反应:

机器学习只能观察外部情绪信号,无法直接感知个体的主观情绪体验。我们通过分析语言来推测情绪,其实是在尝试建立外部信号与内部情绪之间的映射关系。
2.3 情绪与语言的关系
人类相比其他哺乳动物,具有更丰富的语言表达能力。我们不仅可以通过肢体动作表达情绪,还能通过复杂的语言结构表达更细腻的情感。
例如:
这就引出了一个问题:我们能否通过语言来研究情绪的主观体验?这需要一个前提假设:语言信号与情绪之间存在某种映射关系。
2.4 情绪与语言的映射关系
我们假设存在一个函数:

同时,我们还假设语言信号是共享情绪信号的一个子集,存在一个函数:

从而可以组合出:

如果我们能学习这个函数,就可以通过语言来推断情绪。
2.5 这个函数真的存在吗?
答案是否定的。语言与情绪之间不存在一一对应关系。以下是几个关键原因:
- 语言与情绪的复杂性不完全匹配
- 情绪分类缺乏统一标准
- NLP目前主要依赖语法分析,语义理解仍不成熟
⚠️ 踩坑提醒:
语言是开放系统,句子结构无限多,情绪表达也高度复杂。试图通过语言完全还原情绪,是不现实的。
3. 文本分类与情感分析
3.1 当行为可预测时,可使用机器学习
大多数情绪反应是稳定且可重复的。如果一个词在某个情绪状态下被频繁使用,它在类似情绪中再次出现的概率也很高。
例如:
- Mark is happy to see Jane
- “Happy to go on holiday!”, wrote Robert
- “Chocolate makes me happy”, says Mary
这三个例子中,“happy”都表达了积极情绪。
这说明:
✅ 在某些简单情绪场景下,语言与情绪之间可以建立映射关系。
3.2 当行为不可预测时,机器学习失效
但并非所有语言都能准确表达情绪:
- “I’m so sad”, said John while crying
- “You’re so sad”, commented Edward sarcastically
- “Don’t be sad”, replied Elizabeth assertively
同一个“sad”词,在不同语境中表达的情绪完全不同。
这说明:
❌ 语言与情绪之间不存在唯一对应关系,尤其在复杂语境中。
3.3 情感分析的前提假设
要进行情感分析,必须满足以下假设:
- 存在从语言到情绪的映射函数(理想是双射)
- 语言和词义不会随时间发生剧烈变化
- 社会对情绪分类有一致认同
这些假设在现实中往往不成立,但在特定场景下可以近似成立。
3.4 实际应用中的假设成立条件
尽管这些假设在理论上不成立,但在实际应用中,我们可以通过以下方式使其成立:
- 假设情绪是简单且有限的(如“正面”、“负面”)
- 使用时间跨度较短、语言风格统一的语料库
- 假设标注者之间情绪判断基本一致(实际存在偏差)
✅ 踩坑提醒:
情绪标注具有主观性,不同人对同一句话的情绪判断可能不同。模型训练时要注意标注质量。
4. 公共情绪识别数据集
4.1 情感分析常用数据集
以下是一些适合初学者和实际应用的公开数据集:
Amazon Reviews for Sentiment Analysis
- 用于学习评论文本与评分之间的关联
- 适合训练跨产品用户情绪识别模型
-
- 包含多种语言的情绪词典
- 更适合基于规则的方法(而非统计模型)
-
- 包含Facebook帖子的情绪强度和极性标签
- 适合识别情绪强度,不只是正负极性
-
- 包含推文文本及其情绪标签
- 情绪标注一致性较差,需谨慎使用
-
- 包含新闻条目及其情绪分类
- 情绪分类较丰富,适合多分类任务
4.2 补充情绪语料库信息
上述数据集适合入门学习,但实际构建情绪识别系统时,还需要结合业务场景进行补充:
- 用户情绪识别通常只是更大系统的组成部分
- 情绪分析常与用户行为建模、偏好预测结合使用
- 可通过情绪聚类帮助人工分析负面反馈
✅ 实际应用建议:
情绪分析应结合其他机器学习方法,如用户行为建模、语义理解等,才能发挥更大价值。
5. 总结
本文从理论角度分析了文本情绪识别的可行性与限制。我们了解到:
- 情绪具有主观不可观测的内部维度和可观测的外部维度
- 语言只是情绪表达的一部分
- 情感分析依赖几个理想化假设,现实中往往不完全成立
- 但在特定场景下(如简单情绪分类、语言风格统一),情感分析是可行的
最后,我们列举了多个公开可用的情绪识别数据集,供实践使用。
✅ 总结要点:
- 情绪识别本质是通过语言信号推测主观情绪
- 语言与情绪之间不存在唯一映射
- 情感分析在简单场景下有效,复杂场景需结合语义理解和其他模型
- 标注质量对模型效果影响极大,需谨慎处理数据