1. 简介
机器学习(Machine Learning,简称 ML)是计算机科学与人工智能的一个分支,它使程序能够通过数据“学习”并做出决策,而无需依赖明确的编程规则。
在机器学习模型中,输入数据通常由多个特征(features)组成。这些特征在模型预测中所起的作用并不相同,有些特征对预测结果影响更大,有些则几乎可以忽略不计。我们把这种对模型预测影响程度的衡量称为 特征重要性(Feature Importance)。
在本文中,我们将解释特征重要性是什么、它为什么重要,并介绍一些常见的评估方法。
2. 什么是特征(Features)?
用一句话概括:特征(或变量)是从数据集中提取出来的、用于输入机器学习模型的属性。
通常,特征以数值形式出现在数据集中,但也可以是字符串类型。例如,以下表格展示了描述足球运动员的一些特征:
| goals | height | position | salary |
|---|---|---|---|
| 5 | 1.78 | attacker | 100k |
| 0 | 1.85 | defender | 110k |
| 2 | 1.81 | midfielder | 120k |
| ... | ... | ... | ... |
| 0 | 1.84 | midfielder | 100k |
特征是构建机器学习模型的核心组成部分。模型的预测质量在很大程度上取决于特征的质量。因此,特征工程(Feature Engineering)和特征选择(Feature Selection)是建模过程中非常关键的步骤。
3. 什么是特征重要性?
特征重要性表示每个特征对模型预测结果的贡献程度。
简而言之,它衡量某个变量对当前模型和预测任务的“有用性”。例如,如果我们想根据身高、年龄和姓名来预测一个人的体重,显然身高是最重要的特征,而姓名则毫无关联。
特征重要性通常用一个数值表示(称为“得分”),得分越高,说明该特征越重要。
✅ 特征重要性的好处包括:
- 帮助识别不相关的特征并将其剔除
- 提升模型训练速度和性能
- 增强模型的可解释性,便于解释预测结果
📌 两种主要的特征重要性方法:
- 模型无关(Model Agnostic):适用于多种模型
- 模型相关(Model Dependent):特定于某类模型
下文将分别介绍这些方法。
4. 模型无关的特征重要性方法
这类方法不依赖于特定的模型,可以应用于多种机器学习模型(如逻辑回归、随机森林、支持向量机等)。
4.1. 相关性分析(Correlation Criteria)
最简单的方法之一是计算每个特征与目标变量之间的相关性。这适用于目标变量为连续值的情况。
常用的相关性方法包括:
- 皮尔逊相关系数(Pearson Correlation):衡量两个变量之间的线性相关性
- 斯皮尔曼等级相关(Spearman Rank Correlation):衡量变量之间的单调关系
相关系数的取值范围为 -1 到 1:
- 1 表示完全正相关
- 0 表示无相关性
- -1 表示完全负相关
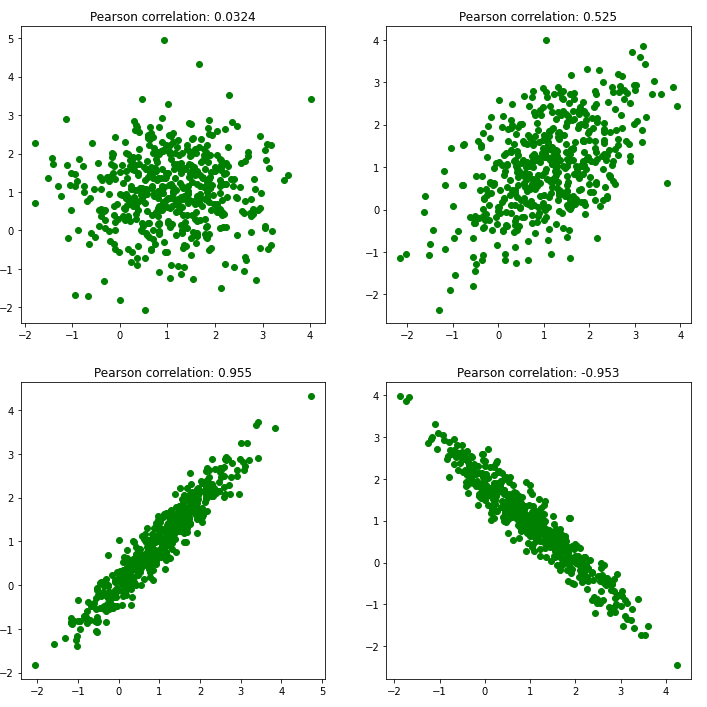
方法步骤:
- 对每个特征计算与目标变量的相关系数
- 按绝对值大小排序,确定特征重要性
4.2. 单变量预测(Single Variable Prediction)
另一种方法是将每个特征单独输入模型进行预测,然后根据预测效果(如误差、准确率等指标)评估其重要性。
注意: 单变量预测能力强的特征,不一定在多变量模型中同样重要。有时某些特征单独预测能力较弱,但与其他特征组合后却能显著提升模型性能。
4.3. 置换特征重要性(Permutation Feature Importance)
这是一种简单且常用的方法。基本思想是:打乱某个特征的值,观察模型预测性能的变化。变化越大,说明该特征越重要。
algorithm PermutationFeatureImportance():
// INPUT
// 原始数据、原始预测结果、评估指标
// OUTPUT
// 按重要性排序的特征列表
M <- 使用原始预测结果计算评估指标
for each feature F:
打乱特征 F 的值
用打乱后的数据重新预测
M_F <- 重新计算评估指标
D_F <- M - M_F (变化越大,说明该特征越重要)
保存 D_F
按 D_F 从大到小排序
return 排序后的特征列表
5. 模型相关的特征重要性方法
这类方法是特定于某个模型的,通常可以直接从模型中提取特征重要性信息。
5.1. 线性回归特征重要性(Linear Regression Feature Importance)
在线性回归模型中,可以通过系数(Coefficients)来衡量特征的重要性。前提是特征已经被标准化(归一化)处理,这样才能比较系数大小。
- 普通线性回归(Linear Regression)
- Lasso 回归(带 L1 正则化的线性回归):Lasso 可以自动进行特征选择,因为它会将不重要的特征系数压缩为零
5.2. 决策树类模型的特征重要性(Decision Tree Feature Importance)
决策树模型(如 CART、随机森林、梯度提升树)通常会输出每个特征在划分节点时对目标变量的“纯度”提升程度。
常用指标包括:
- 基尼不纯度(Gini Impurity)
- 熵(Entropy)
这些指标的提升值越高,说明该特征越重要。该方法也适用于基于决策树的集成模型。
6. 总结
在本文中,我们介绍了机器学习中的“特征”概念,并详细讲解了“特征重要性”的定义及其作用。特征重要性不仅可以帮助我们理解模型内部机制,还能用于特征选择、模型优化和增强可解释性。
我们还介绍了两种主要的特征重要性评估方法:
- 模型无关方法:如相关性分析、单变量预测、置换特征重要性
- 模型相关方法:如线性回归系数、决策树类模型的特征重要性
在实际应用中,可以根据模型类型和业务需求选择合适的方法。建议结合多种方法综合评估,避免单一指标带来的偏差。