1. 概述
本文将探讨如何使用生成对抗网络(GANs)进行数据增强。我们会先介绍数据增强与 GAN 的基本概念,然后展示一种能够生成高质量样本的 GAN 架构。
2. 数据增强简介
深度学习在多个领域带来了革命性突破,成为许多复杂任务(如文本翻译、图像分割、语音识别)的主流方法。其成功依赖于大量标注数据的可用性。然而,获取并标注大量训练数据往往既困难又昂贵。在这种情况下,合理使用数据增强技术可以有效提升模型性能。
以图像数据为例,虽然本文内容适用于任何数据类型,但图像增强是一个非常典型的场景。数据增强的核心思想是通过改变已有数据的属性,或生成新的合成数据来扩充数据集。
常见的图像增强操作包括:翻转、旋转、调整色调、饱和度、亮度和对比度等。这类操作简单,可以在线训练过程中实时完成。但缺点也很明显:我们并没有为模型提供真正意义上的新数据,只是让已有数据以不同形式出现。因此,对模型泛化能力的提升是有限的:
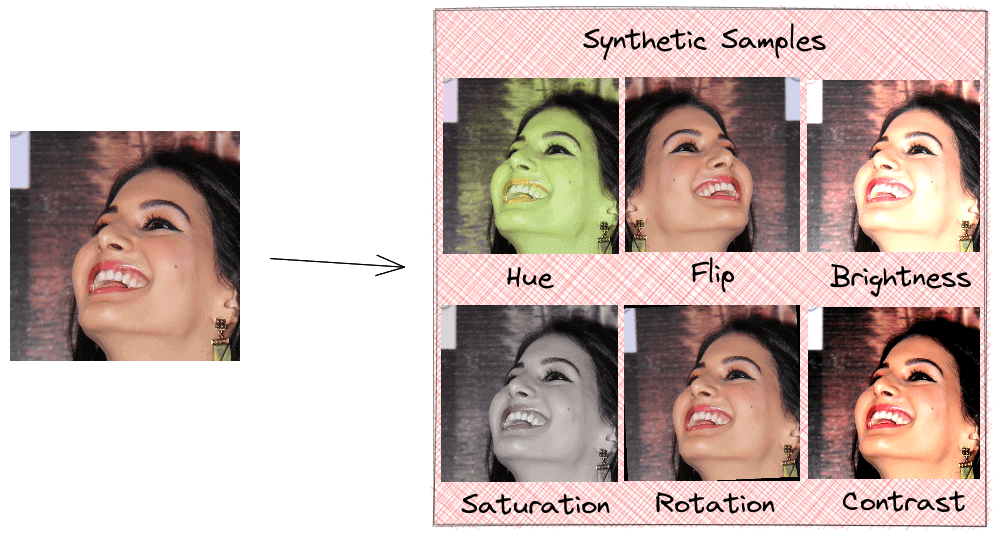
相比之下,生成逼真的新样本更具挑战性,需要模型学习原始数据的分布。正如我们将看到的,GAN 可以生成高质量样本,并显著提升模型表现。
3. GAN 简介
GAN 由两个部分组成:
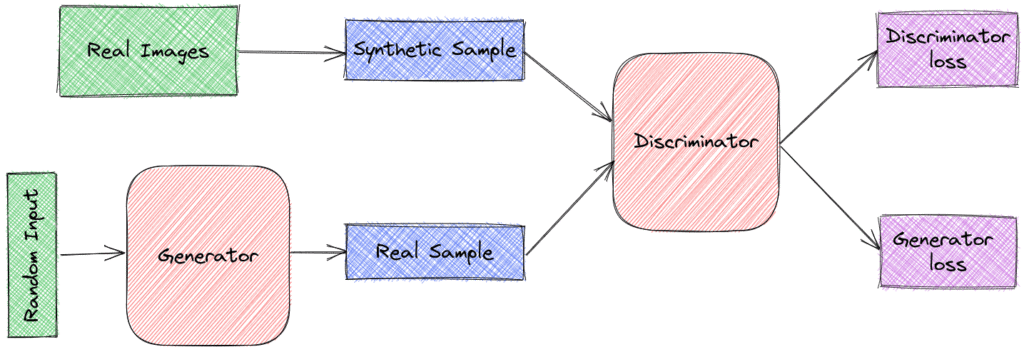
✅ 生成器(Generator):负责生成逼真的数据样本。它接收一个固定长度的随机向量作为输入,并尝试模仿原始数据集的分布来生成新样本。这些样本随后作为判别器的负样本。
✅ 判别器(Discriminator):负责判断输入样本是来自真实数据还是生成器。它将输入样本分类为“真实”或“伪造”。判别器会惩罚生成器生成不合理的样本。
以图像为例,生成器和判别器通常都是卷积神经网络(CNN)。生成器的目标是生成足够逼真的图像,使得判别器无法区分真假。通过反向传播不断更新模型参数,生成器逐渐学会模仿原始数据的分布:
这两个模型之间进行的是一个双人零和博弈(minimax game)。优化判别器的目标函数会降低生成器的目标函数值,反之亦然。具体来说:
- 生成器希望最小化
log(1 - D(G(z))),其中 z 是输入的随机向量。通过最小化这个值,生成器试图欺骗判别器,使其将伪造样本识别为真实样本。 - 判别器则希望最大化
log(D(x)) + log(1 - D(G(z))),其中 x 是真实样本。这个目标函数代表了判别器正确识别真实样本和伪造样本的概率。
4. 条件 GAN(Conditional GAN)
在小样本学习(few-shot learning)场景中,我们希望基于少量样本训练模型进行预测。例如,我们想训练一个模型,输入一张狗的图片并预测其品种。虽然我们可以获取大量动物图片,但标注了具体品种的数据却非常有限。这时,使用 GAN 增强数据集是一个有效策略。
虽然标准 GAN 在大量数据上训练后能生成高质量样本,但它无法控制生成样本的类别。条件 GAN(Conditional GAN)解决了这个问题,它通过修改原始 GAN 的结构来控制生成器输出的类别。
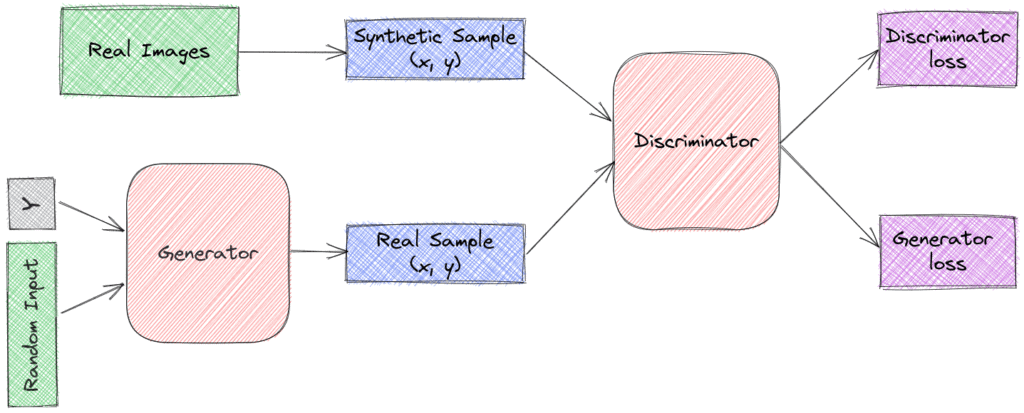
具体来说,它在生成器和判别器中都引入了类别标签:
- 生成器除了接收随机噪声 z,还接收一个类别标签 y,目标是根据这个标签生成对应的样本。
- 判别器同时接收图像 x 和标签 y,判断图像是否真实。
结构如下图所示:
通过这种方式,条件 GAN 能够生成特定类别的样本。例如,在这篇论文 Conditional Generative Adversarial Nets 中展示的 MNIST 手写数字生成结果如下图所示,每一行代表一个类别生成的样本:
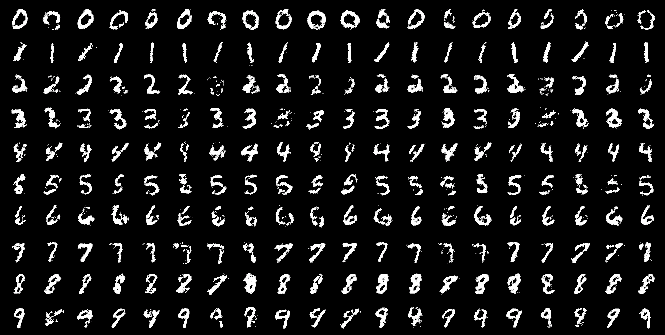
5. 局限性
虽然 GAN 在数据增强方面展现出强大潜力,但它们也存在一些明显局限性:
⚠️ 缺乏统一的评估指标:目前还没有一种标准方法可以直接评估生成样本的质量。虽然有一些实验性指标被提出,但该领域仍需更多研究。
⚠️ 训练不稳定:GAN 的训练过程常常不稳定,对计算资源要求高,调参难度大。很多初学者在训练 GAN 时会遇到“模式崩溃”等问题,生成的样本多样性不足。
6. 总结
本文介绍了如何使用 GAN 进行数据增强。我们从数据增强和生成模型的基本概念入手,重点讲解了 GAN 的工作原理及其在数据增强中的应用。特别地,我们介绍了条件 GAN 的结构,它允许我们生成特定类别的样本。最后,我们也指出了 GAN 当前存在的一些局限性。
✅ 适合场景:小样本数据集、需要高质量合成数据提升模型性能的场景
❌ 不适合场景:资源有限、对生成样本质量要求不高、对训练稳定性要求高的项目