1. 概述
在本文中,我们将深入探讨强化学习中的“策略(Policy)”这一核心概念。
强化学习的目标是让智能体(Agent)在与环境交互的过程中学习如何做出最优决策,以最大化其长期收益。而“策略”正是智能体在不同状态下选择动作的规则。掌握策略的概念,有助于我们理解强化学习的核心机制,并为后续学习策略优化方法打下基础。
2. 策略的定义
强化学习是机器学习的一个分支,专注于训练智能体在特定环境中执行任务,以实现目标的最大化收益。
根据 Russel 的观点,智能是智能体与其环境交互过程中涌现的属性。这种属性引导智能体在执行任务时做出选择。从这个角度看,智能体的智能体现在它能否选择与目标匹配的合适策略。
在强化学习中,策略(Policy)是智能体为实现目标所采用的行动规则。它是一个从状态到动作的映射函数,决定了智能体在特定状态下应采取什么动作。
3. 策略的数学定义
为了形式化地定义策略,我们通常借助马尔可夫决策过程(Markov Decision Process, MDP)。MDP 是一个四元组 (S, A, P, R),其结构如下:
- S:状态集合,表示智能体可能处于的所有状态,合称“状态空间”。例如在网格世界中,状态可能是智能体的坐标位置。
- A:动作集合,表示智能体可以采取的所有行为,合称“动作空间”。
- P:状态转移概率矩阵,其中 Pa(s, s') 表示在状态 s 执行动作 a 后转移到状态 s' 的概率。
- **R(s)**:奖励函数,输入当前状态 s,输出一个实数表示该状态的价值。
有了这些定义,我们就可以正式定义策略 π:
策略 π 是一个从状态空间 S 到动作空间 A 的映射函数,即 π(s) 表示在状态 s 下智能体应采取的动作。
4. 强化学习中的策略示例
我们来看一个具体的例子:一个智能体需要在网格世界中寻找食物来满足饥饿感。
场景设定
- 智能体的初始位置为 (1,1),状态为坐标 (x, y)。
- 动作空间 A = {上、下、左、右}。
- 状态转移概率为确定性,即每次动作都能准确执行。
- 奖励函数定义如下:
| 状态类型 | 奖励值 |
|---|---|
| 空单元格 | -1 |
| 梨 | +5 |
| 苹果 | +10 |
示例图示
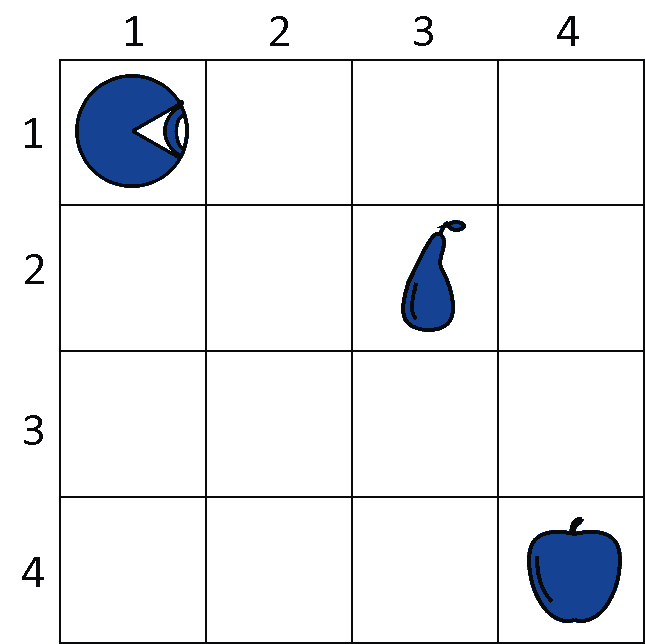
在这个环境中,智能体的目标是通过移动到达水果位置以获得最大奖励。
5. 策略评估
我们考虑两个策略 π₁ 和 π₂:
- π₁ = 下、右、右 → 到达梨
- π₂ = 右、右、右、下、下、下 → 到达苹果
路径图示
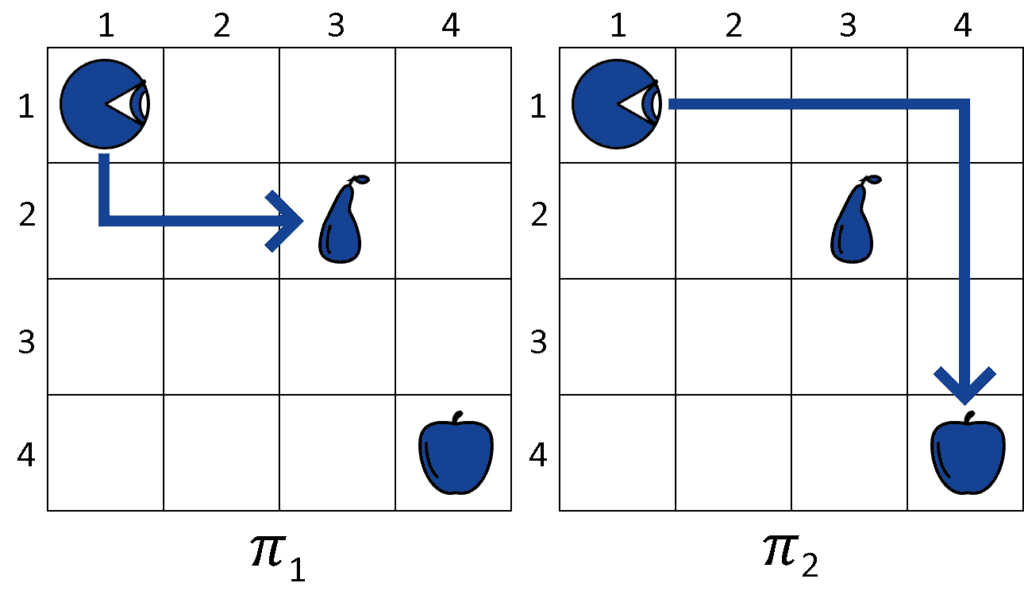
我们计算两个策略的总效用(Utility):
- U(π₁) = -1 -1 +5 = +3
- U(π₂) = -1 -1 -1 -1 -1 +10 = +5
效用对比图
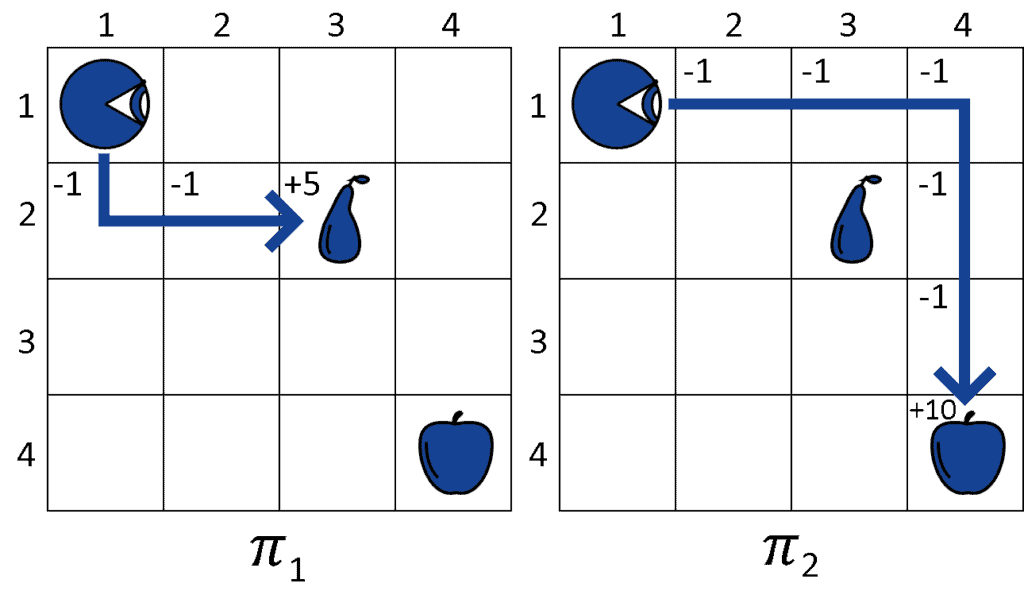
从结果来看,π₂ 的总奖励更高,因此智能体会选择 π₂ 作为其策略。
6. 小结
在本文中,我们了解了强化学习中“策略”的基本定义,学习了其在马尔可夫决策过程中的数学表达方式,并通过一个具体的网格世界例子说明了策略如何指导智能体进行决策。
✅ 策略是强化学习的核心概念之一,理解它有助于我们进一步掌握策略优化、深度策略网络等进阶方法。
❌ 在实际应用中,策略的评估和选择需要综合考虑状态空间、动作空间和奖励函数的复杂性。
⚠️ 策略设计不当可能导致智能体陷入局部最优或无法收敛,务必在实践中不断调整和优化。