1. 引言
在本文中,我们将讨论统计抽样中的选择偏差问题,以及如何通过一些技术手段来减少其影响。选择偏差是一种常见的统计误差,尤其在机器学习领域中,它可能导致训练数据的失真,从而影响模型的预测准确性。
2. 从战争中学习统计学
2.1. 统计学在战争中的应用
选择偏差不仅影响统计分析,也会对机器学习模型造成严重干扰。一个经典的例子发生在二战期间,美国海军邀请数学家沃尔德(Abraham Wald)研究如何减少空战中的飞机损失。
当时,军方统计了返航飞机的受损部位,试图通过加固这些“高频受损区域”来提高飞机的生存率。但沃尔德提出了一个令人惊讶的结论:那些最常被修复的部位反而是飞机最坚固的部分。真正需要加固的,是那些在返航飞机上几乎看不到损坏的区域,比如驾驶舱和引擎。
2.2. 幸存者的误导
沃尔德的结论基于一个关键观察:只有成功返航的飞机才会被统计。那些被击落的飞机根本不会出现在数据集中,因此这些数据本身就存在偏差。这种偏差被称为“幸存者偏差(Survivorship Bias)”,是选择偏差的一种典型表现。
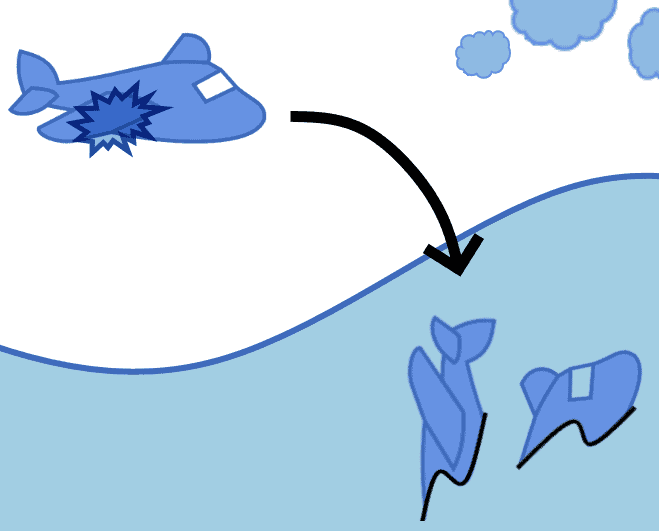
这个故事说明了一个重要问题:样本选择方式会影响我们对整体的判断。如果我们忽视了数据背后的采样机制,就可能得出完全错误的结论。
3. 所有中奖者都是幸运儿?
另一个关于选择偏差的例子来自彩票中奖者。一位来自佛罗里达的男子连续多次中奖,并在采访和著作中分享了他的“中奖秘诀”:
“买彩票,中奖后用奖金继续买更多彩票。”
这个策略听起来简单粗暴,但他确实从中获利超过百万美元。而且还有不少“成功案例”也声称使用了同样的方法。
我们可以用一个流程图来表示他的策略:

从表面上看,这似乎是一个可行的投资策略。毕竟,有那么多“成功案例”摆在眼前。
4. 偏见下的选择
4.1. 选择性忽略失败案例
但问题出在哪儿呢?
答案是:我们只关注了“成功者”的经验,忽略了那些失败的、无法发声的人。实际上,大多数采用这种策略的人都赔了钱,但他们不会写书、也不会接受采访。
这正是选择偏差的核心:样本选择过程中遗漏了某些群体,导致我们对整体情况的判断出现偏差。
4.2. 统计者自身的责任
选择偏差并不是数据本身的错误,而是统计分析者在采样或分析过程中引入的系统性偏差。如果我们只收集中奖者的反馈,而忽略了所有未中奖的参与者,那我们的分析就会严重失真。
这种情况也被称为“幸存者偏差”。关键在于:有多少人尝试了这个策略?又有多少人真正成功了?
如果只看成功者,就像只看返航的飞机,我们就会得出错误的结论。
5. 如何避免选择偏差
5.1. 查阅文献,了解背景知识
要避免选择偏差,首先要了解你研究领域的背景知识。这通常意味着要在研究开始前进行文献综述(Literature Review)。
例如,如果你想研究某个国家的教育水平,你应该先查阅政府或学术机构过去发布的相关报告。这些资料将帮助你建立一个更全面的认知框架,避免在采样时忽略关键群体。
✅ 建议:不要闭门造车,先看看别人是怎么做的。
5.2. 方法与理论一致
其次,你的采样方法必须与研究目标一致。例如,如果你想了解一个地区的教育水平,却只发放纸质问卷,那就可能遗漏文盲人群,从而导致偏差。
✅ 建议:根据研究对象选择合适的调查方式,比如语音访谈、实地走访等。
5.3. 随机抽样与分层抽样
在一些情况下,人群可以被划分为多个相似的子群体(Cluster)。这时,随机抽样和分层抽样(Stratified Sampling) 是减少偏差的有效方法。
分层抽样的核心思想是:每个子群体在样本中应按其在总体中的比例出现。这样可以确保样本具有代表性。
✅ 建议:当样本存在明显分组时,使用分层抽样,而不是简单随机抽样。
5.4. 知道你的先验分布
最后,作为一名统计分析者,你应具备“贝叶斯思维”:知道你的先验(Priors)。
也就是说,在开始分析前,你应该对数据的分布有一个合理的预期。如果实际数据与预期偏差很大,那可能是采样过程中出现了偏差。
✅ 建议:如果你发现数据与常识严重不符,先别急着下结论,先查查你的采样过程。
6. 总结
选择偏差是统计分析中一个常见但容易被忽视的问题。它可能导致我们对现实的认知出现系统性偏差。
要避免选择偏差,你可以:
- ✅ 查阅文献,了解已有研究
- ✅ 确保采样方法与研究目标一致
- ✅ 使用随机或分层抽样方法
- ✅ 理解并验证你的先验分布
记住:数据不会说谎,但采样方式可能会误导你。作为统计分析者,你有责任识别并纠正这些偏差。