1. 引言
在机器学习模型评估过程中,如何合理地划分训练集和测试集是一个非常关键的步骤。本文将介绍一种常用的数据采样技术 —— 分层抽样(Stratified Sampling),它能有效提升测试集的代表性,避免因样本分布不均而导致的评估偏差。我们会结合代码示例说明其原理与实现方式,并通过对比实验展示其优势。
2. 采样技术概述
在评估机器学习模型时,通常需要将原始数据集划分为训练集和测试集。最简单的方式是随机选取一部分数据作为测试集,比如选取 20% 的数据。这种方法叫做 简单随机抽样(Simple Random Sampling)。
✅ 优点:实现简单
❌ 缺点:当原始数据集本身分布不均时,测试集可能无法真实反映整体数据分布,从而引入偏差
分层抽样 是一种改进的采样方法,它将整个数据集按照某种特征划分为若干个子群(称为 strata,层),然后在每个子群中进行随机抽样。这样可以确保每个子群在训练集和测试集中保持原有比例,从而提升模型评估的准确性。
例如,如果原始数据中 10% 是正样本,90% 是负样本,使用分层抽样后,训练集和测试集中正样本的比例也应大致为 10%。
3. 分层抽样的步骤
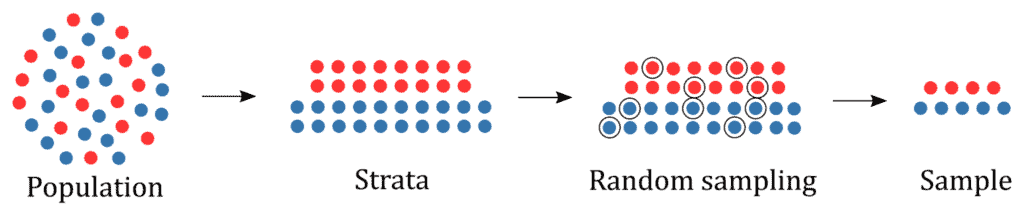
实现分层抽样可以分为以下三步:
- 确定样本数量:通常测试集占总数据集的 20% 左右,但具体比例可根据数据规模调整。
- 将数据集按特征分层:将数据集划分为若干个互不重叠的子群,每个样本只能属于一个子群。
- 在每一层中进行随机抽样:按照设定的比例从每一层中抽取样本,组合成最终的测试集或训练集。
下图展示了分层抽样的整个流程:
4. 分层抽样的优缺点
✅ 优点:
- 测试集更具有代表性,能更准确地反映整体数据分布
- 减少采样误差,提升模型评估的稳定性
- 在类别不平衡数据集中特别有效
❌ 缺点:
- 需要先对数据集进行分层,增加了实现复杂度
- 若数据集本身无法有效分层(如样本差异太大),则随机抽样反而更合适
5. 示例:使用 Scikit-Learn 实现分层交叉验证
我们以 MNIST 数据集为例,构建一个二分类模型,判断一个数字是否为 9。由于数据集中数字 9 的样本较少,属于典型的类别不平衡数据集。
5.1 加载并预处理数据
import numpy as np
from keras.datasets import mnist
(x_train, y_train), (_, _) = mnist.load_data()
x_train = x_train.reshape(-1, 28*28) / 255.0 # 归一化到 [0, 1]
y_train = (y_train == 9) # 构建二分类标签
5.2 使用 StratifiedKFold 进行交叉验证
from sklearn.linear_model import SGDClassifier
from sklearn.model_selection import StratifiedKFold
skfolds = StratifiedKFold(n_splits=3)
splits = skfolds.split(x_train, y_train)
for i, (train_idx, test_idx) in enumerate(splits):
x_tr, x_te = x_train[train_idx], x_train[test_idx]
y_tr, y_te = y_train[train_idx], y_train[test_idx]
clf = SGDClassifier()
clf.fit(x_tr, y_tr)
y_pred = clf.predict(x_te)
accuracy = np.mean(y_pred == y_te)
print(f"[SPLIT {i+1}]")
print(f"Positive class (digit 9) in original data: {np.mean(y_train)*100:.2f}%")
print(f"Positive class in training set: {np.mean(y_tr)*100:.2f}%")
print(f"Positive class in test set: {np.mean(y_te)*100:.2f}%")
print(f"Accuracy: {accuracy:.4f}")
输出结果如下图所示:

可以看到,使用 StratifiedKFold 后,每个 fold 中正样本(数字 9)的比例都与原始数据集保持一致。
5.3 对比:使用普通 KFold 的效果
如果我们改用普通的 KFold:
from sklearn.model_selection import KFold
skfolds = KFold(n_splits=3)
输出如下:

可以看到,正样本的比例在不同 fold 中波动很大,这说明测试集的代表性下降,模型评估结果的可信度也随之降低。
6. 总结
本文介绍了分层抽样(Stratified Sampling)在机器学习中的应用,特别适用于类别不平衡或需要保持样本分布一致性的场景。通过 Scikit-Learn 提供的 StratifiedKFold 类,我们可以非常方便地实现分层交叉验证。
✅ 适用场景:
- 类别不平衡数据集
- 需要保持样本分布一致性的模型评估
- 多分类任务中希望每个类别在训练和测试中都有合理代表
❌ 不适用场景:
- 样本之间差异过大,难以有效分层
- 数据集本身已经高度随机化,无需额外控制分布
分层抽样是提升模型评估稳定性与准确性的有效手段之一,建议在实际项目中优先使用。