1. 概述
卷积神经网络(CNN)是深度学习中的核心技术之一,广泛应用于图像识别、自然语言处理等多个领域。理解其内部的维度变化,是掌握 CNN 构建与优化的关键。
本文将从输入、卷积核、卷积操作和输出这四个维度角度出发,通过几个典型示例,深入浅出地解释不同维度的卷积操作在实际中的应用。
2. 卷积基础
2.1. 卷积定义
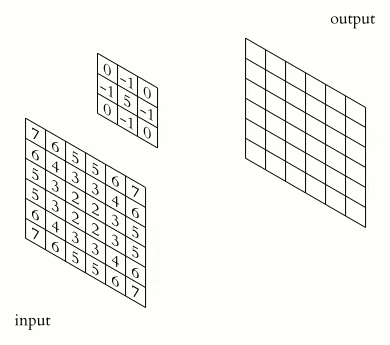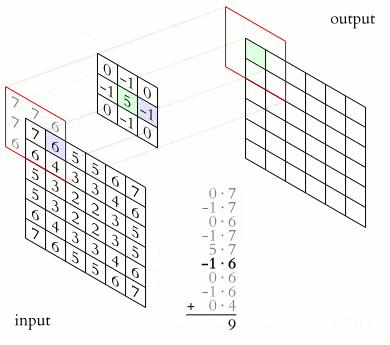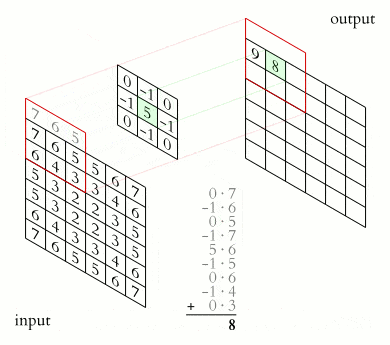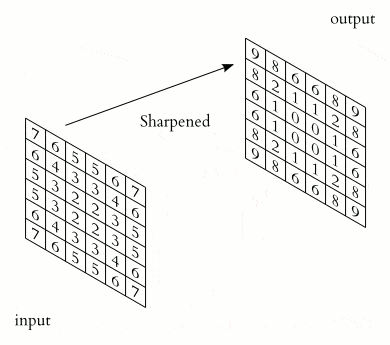
卷积神经网络的核心在于“卷积”操作。简单来说,卷积就是用一个称为 kernel(卷积核) 的小矩阵在输入数据上滑动,并与对应区域做点积运算,从而提取出特定的特征。
一个 kernel 代表一个特定的模式,输出的激活值则表示当前区域与该模式的匹配程度。
下面是一张 2D 卷积的动画示意图:
2.2. 维度组成
在 CNN 中,涉及的维度主要包括:
- 输入层(Input layer):输入数据的维度
- 卷积核(Kernel):用于提取特征的小矩阵
- 卷积操作(Convolution):kernel 在输入上滑动的方向
- 输出层(Output layer):卷积后的输出结果维度
理解这四个维度之间的关系,是掌握 CNN 架构设计的前提。
3. 一维输入
3.1. 用 1D 卷积平滑曲线
对于一维输入,维度配置如下:
- 输入层:1D
- 卷积核:1D
- 卷积操作:1D
- 输出层:1D
一维输入可以看作是一条数值序列,例如时间序列或音频信号。
下图展示了一个原始 1D 数据的图形表示:
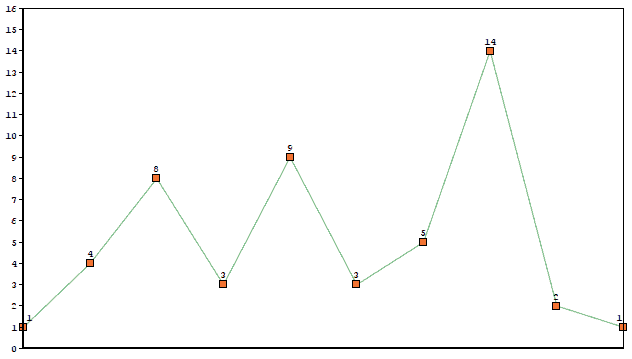
如果我们使用一个 kernel 为 [0.33, 0.67, 0.33] 的卷积核进行平滑处理,输出结果如下:
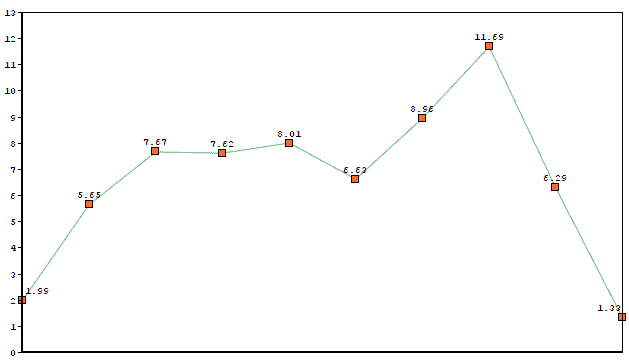
可以看到,输出曲线保留了原始形状,但变得更加平滑。
✅ 小技巧:1D 卷积常用于时间序列平滑、语音信号处理等场景。
4. 二维输入
4.1. 计算机视觉中的 2D 卷积
这是最常见的一种卷积形式,维度配置如下:
- 输入层:2D(如图像)
- 卷积核:2D
- 卷积操作:2D
- 输出层:2D
这种卷积非常适合用于图像处理,随着网络加深,可以提取出越来越复杂的特征。
例如在人脸识别任务中:

- 浅层(左图):识别边缘和基本形状
- 中层(中图):识别鼻子、眼睛等局部特征
- 深层(右图):识别整张人脸的不同模式
✅ 小技巧:2D 卷积是图像分类、目标检测等任务的核心操作。
4.2. 用 1D 卷积编码 n-Gram 模式
在自然语言处理(NLP)中,我们通常将每个词表示为一个 m 维向量,然后使用 n × m 的卷积核来编码 n-Gram 模式。
这种操作的维度配置如下:
- 输入层:2D(词序列 × 向量维度)
- 卷积核:2D
- 卷积操作:1D
- 输出层:1D
比如我们使用一个表示“very wealthy”的 kernel,相似词如“the richest”会产生较高的激活值,而无关词如“is the”则激活值较低。
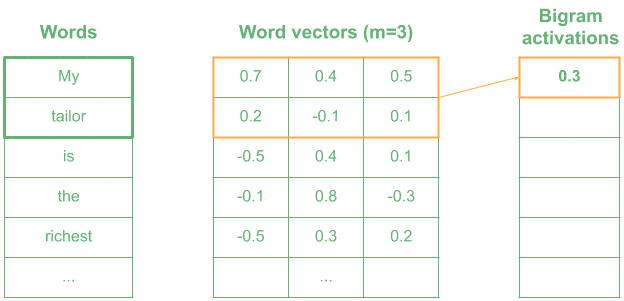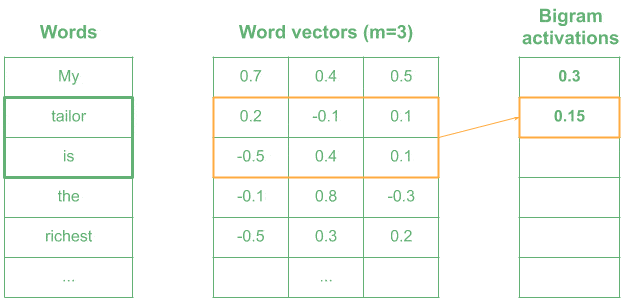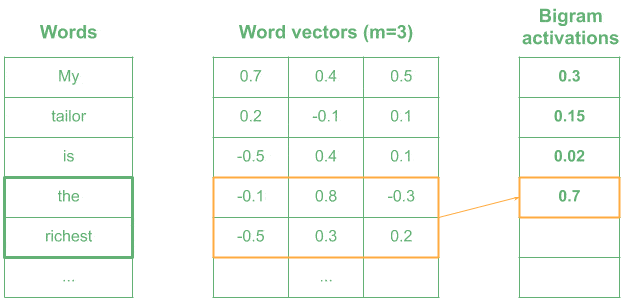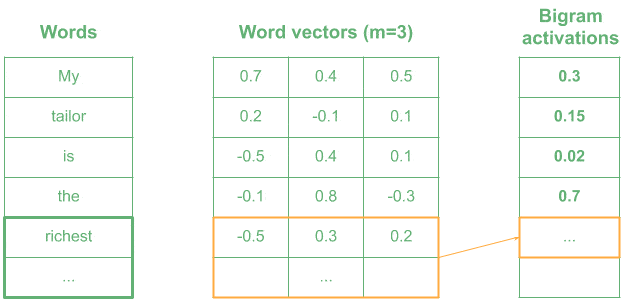
✅ 小技巧:1D 卷积在 NLP 中可用于文本分类、情感分析等任务。
5. 三维输入
5.1. 用 3D 卷积识别三维模式
当输入为三维数据时(如 3D 医学图像或视频),我们可以使用 3D 卷积进行特征提取:
- 输入层:3D
- 卷积核:3D
- 卷积操作:3D
- 输出层:3D
每个 3D kernel 会作用在整个体积上,提取出新的三维特征:
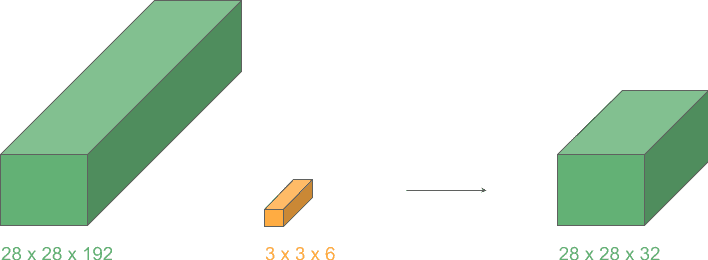
这种操作常用于脑部肿瘤识别、视频动作检测等任务。
✅ 小技巧:3D 卷积在医学图像和视频分析中非常有用。
5.2. 用 2D 卷积进行维度压缩
当卷积核的深度等于输入的深度时,我们可以用 2D 卷积进行维度压缩:
- 输入层:3D
- 卷积核:3D
- 卷积操作:2D
- 输出层:2D
此时,kernel 只在高度和宽度方向滑动,深度方向不做移动。结果是一个维度减少的输出层。
这种操作常用于通道压缩,尤其当 kernel 尺寸为 1×1 时效率更高。
✅ 小技巧:这种技巧在 Inception 模块中被广泛使用。
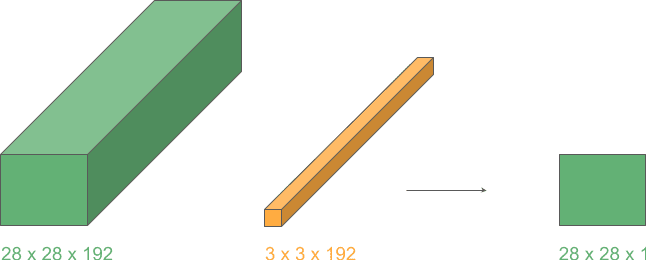
5.3. 用 1D 卷积减少通道数
我们可以进一步利用上述思想,使用 1D 卷积在保持空间维度不变的前提下,减少通道数。
维度配置如下:
- 输入层:3D
- 卷积核:1D
- 卷积操作:2D
- 输出层:3D
如果使用 m 个这样的 kernel,就可以将输出通道数压缩为 m:
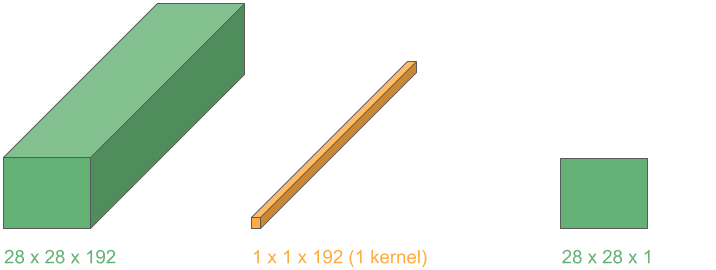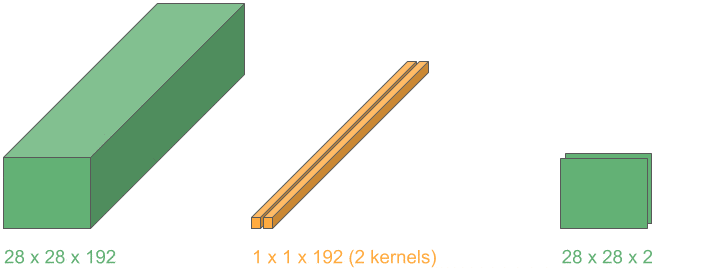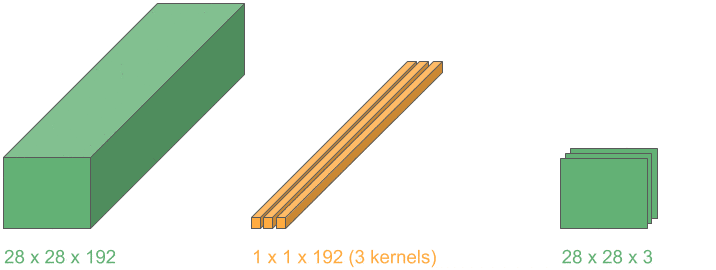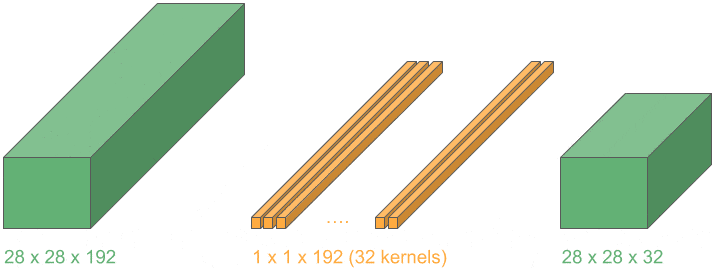
这种操作在 Inception 网络中被大量使用,用于减少计算量并提升效率。
✅ 小技巧:1×1 卷积是通道压缩的利器,Inception 网络的精髓之一。
6. 总结
通过本文我们了解到:
- 不同维度的卷积操作适用于不同任务
- 1D 卷积适用于序列数据处理
- 2D 卷积是图像任务的核心
- 3D 卷积适用于体积数据或视频分析
- 利用不同维度的 kernel 可以实现通道压缩、降维等高级操作
理解这些维度变化,有助于我们更好地设计 CNN 模型结构,提升模型效率和性能。